 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Loops to Oops: Fallback Behaviors of Language Models Under Uncertainty
Paper and Code


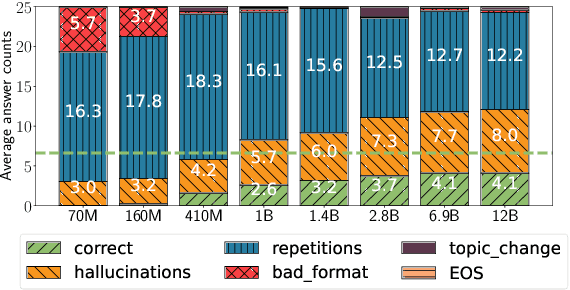
Large language models (LLMs) often exhibit undesirable behaviors, such as hallucinations and sequence repetitions. We propose to view these behaviors as fallbacks that models exhibit under uncertainty, and investigate the connection between them. We categorize fallback behaviors -- sequence repetitions, degenerate text, and hallucinations -- and extensively analyze them in models from the same family that differ by the amount of pretraining tokens, parameter count, or the inclusion of instruction-following training. Our experiments reveal a clear and consistent ordering of fallback behaviors, across all these axes: the more advanced an LLM is (i.e., trained on more tokens, has more parameters, or instruction-tuned), its fallback behavior shifts from sequence repetitions, to degenerate text, and then to hallucinations. Moreover, the same ordering is observed throughout a single generation, even for the best-performing models; as uncertainty increases, models shift from generating hallucinations to producing degenerate text and then sequence repetitions. Lastly, we demonstrate that while common decoding techniques, such as random sampling, might alleviate some unwanted behaviors like sequence repetitions, they increase harder-to-detect hallucinations.