 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs
Paper and Code
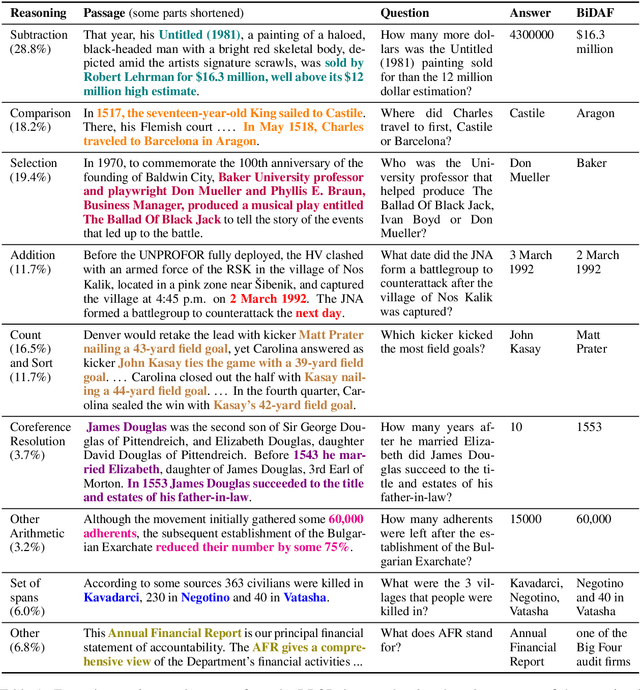
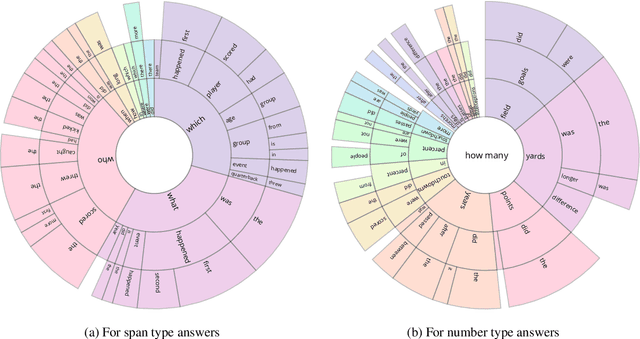
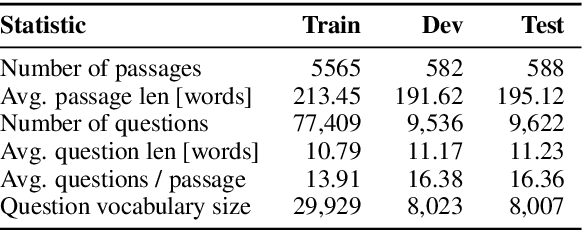
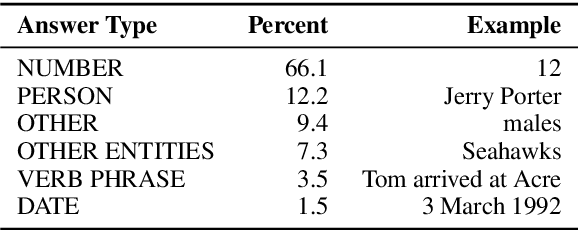
Reading comprehension has recently seen rapid progress, with systems matching humans on the most popular datasets for the task. However, a large body of work has highlighted the brittleness of these systems, showing that there is much work left to be done. We introduce a new English reading comprehension benchmark, DROP, which requires Discrete Reasoning Over the content of Paragraphs. In this crowdsourced, adversarially-created, 96k-question benchmark, a system must resolve references in a question, perhaps to multiple input positions, and perform discrete operations over them (such as addition, counting, or sorting). These operations require a much more comprehensive understanding of the content of paragraphs than what was necessary for prior datasets. We apply state-of-the-art methods from both the reading comprehension and semantic parsing literature on this dataset and show that the best systems only achieve 32.7% F1 on our generalized accuracy metric, while expert human performance is 96.0%. We additionally present a new model that combines reading comprehension methods with simple numerical reasoning to achieve 47.0% F1.