 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Analysis and Prediction of Job Interview Performance
Paper and Code
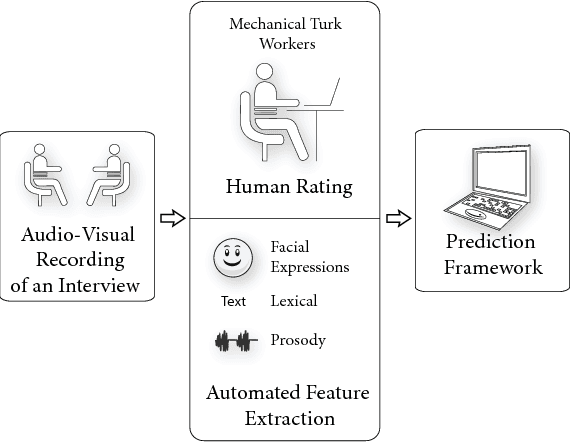
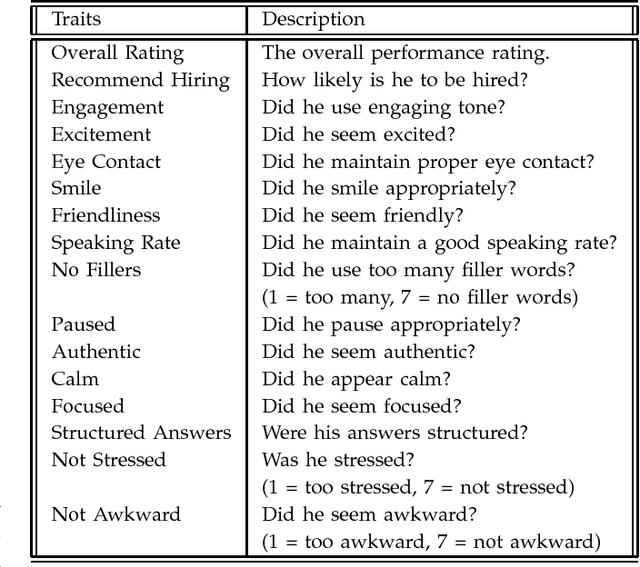


We present a computational framework for automatically quantifying verbal and nonverbal behaviors in the context of job interviews. The proposed framework is trained by analyzing the videos of 138 interview sessions with 69 internship-seeking undergraduates at the Massachusetts Institute of Technology (MIT). Our automated analysis includes facial expressions (e.g., smiles, head gestures, facial tracking points), language (e.g., word counts, topic modeling), and prosodic information (e.g., pitch, intonation, and pauses) of the interviewees. The ground truth labels are derived by taking a weighted average over the ratings of 9 independent judges. Our framework can automatically predict the ratings for interview traits such as excitement, friendliness, and engagement with correlation coefficients of 0.75 or higher, and can quantify the relative importance of prosody, language, and facial expressions. By analyzing the relative feature weights learned by the regression models, our framework recommends to speak more fluently, use less filler words, speak as "we" (vs. "I"), use more unique words, and smile more. We also find that the students who were rated highly while answering the first interview question were also rated highly overall (i.e., first impression matters). Finally, our MIT Interview dataset will be made available to other researchers to further validate and expand our findings.