 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Developer and LLM Biases in Code Evaluation
Mar 25, 2026As LLMs are increasingly used as judges in code applications, they should be evaluated in realistic interactive settings that capture partial context and ambiguous intent. We present TRACE (Tool for Rubric Analysis in Code Evaluation), a framework that evaluates LLM judges' ability to predict human preferences and automatically extracts rubric items to reveal systematic biases in how humans and models weigh each item. Across three modalities -- chat-based programming, IDE autocompletion, and instructed code editing -- we use TRACE to measure how well LLM judges align with developer preferences. Among 13 different models, the best judges underperform human annotators by 12-23%. TRACE identifies 35 significant sources of misalignment between humans and judges across interaction modalities, the majority of which correspond to existing software engineering code quality criteria. For example, in chat-based coding, judges are biased towards longer code explanations while humans prefer shorter ones. We find significant misalignment on the majority of existing code quality dimensions, showing alignment gaps between LLM judges and human preference in realistic coding applications.
Rubric Is All You Need: Enhancing LLM-based Code Evaluation With Question-Specific Rubrics
Mar 31, 2025
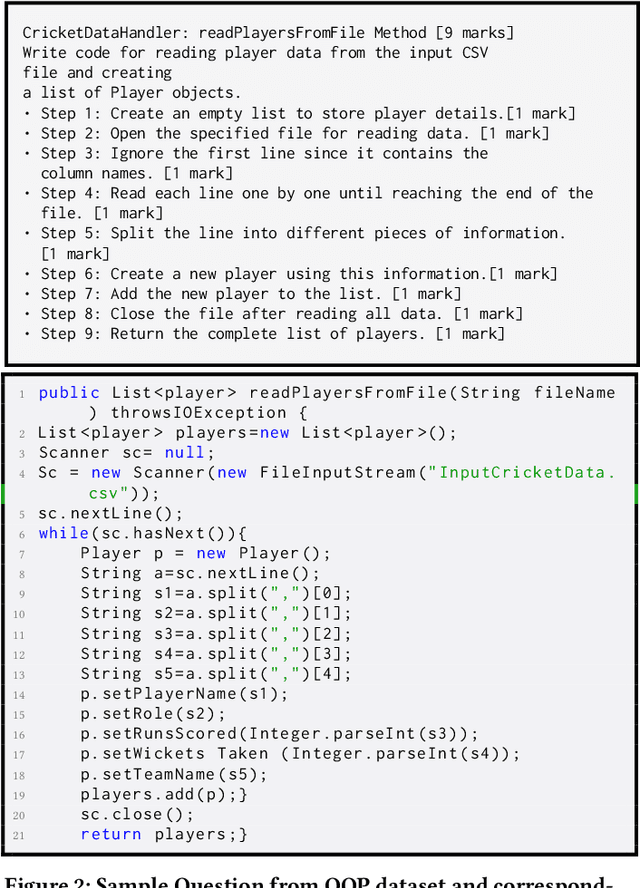
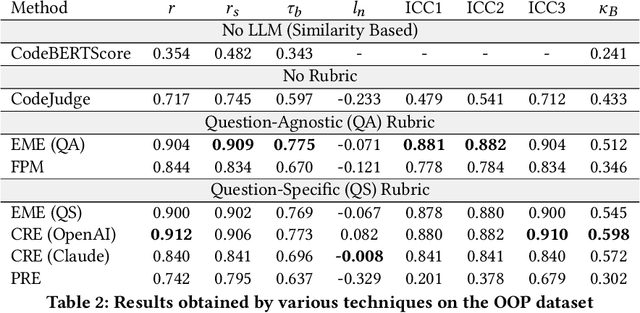
Since the disruption in LLM technology brought about by the release of GPT-3 and ChatGPT, LLMs have shown remarkable promise in programming-related tasks. While code generation remains a popular field of research, code evaluation using LLMs remains a problem with no conclusive solution. In this paper, we focus on LLM-based code evaluation and attempt to fill in the existing gaps. We propose multi-agentic novel approaches using question-specific rubrics tailored to the problem statement, arguing that these perform better for logical assessment than the existing approaches that use question-agnostic rubrics. To address the lack of suitable evaluation datasets, we introduce two datasets: a Data Structures and Algorithms dataset containing 150 student submissions from a popular Data Structures and Algorithms practice website, and an Object Oriented Programming dataset comprising 80 student submissions from undergraduate computer science courses. In addition to using standard metrics (Spearman Correlation, Cohen's Kappa), we additionally propose a new metric called as Leniency, which quantifies evaluation strictness relative to expert assessment. Our comprehensive analysis demonstrates that question-specific rubrics significantly enhance logical assessment of code in educational settings, providing better feedback aligned with instructional goals beyond mere syntactic correctness.
TowerDebias: A Novel Debiasing Method based on the Tower Property
Nov 13, 2024



Decision-making processes have increasingly come to rely on sophisticated machine learning tools, raising concerns about the fairness of their predictions with respect to any sensitive groups. The widespread use of commercial black-box machine learning models necessitates careful consideration of their legal and ethical implications on consumers. In situations where users have access to these "black-box" models, a key question emerges: how can we mitigate or eliminate the influence of sensitive attributes, such as race or gender? We propose towerDebias (tDB), a novel approach designed to reduce the influence of sensitive variables in predictions made by black-box models. Using the Tower Property from probability theory, tDB aims to improve prediction fairness during the post-processing stage in a manner amenable to the Fairness-Utility Tradeoff. This method is highly flexible, requiring no prior knowledge of the original model's internal structure, and can be extended to a range of different applications. We provide a formal improvement theorem for tDB and demonstrate its effectiveness in both regression and classification tasks, underscoring its impact on the fairness-utility tradeoff.
dsld: A Socially Relevant Tool for Teaching Statistics
Nov 06, 2024


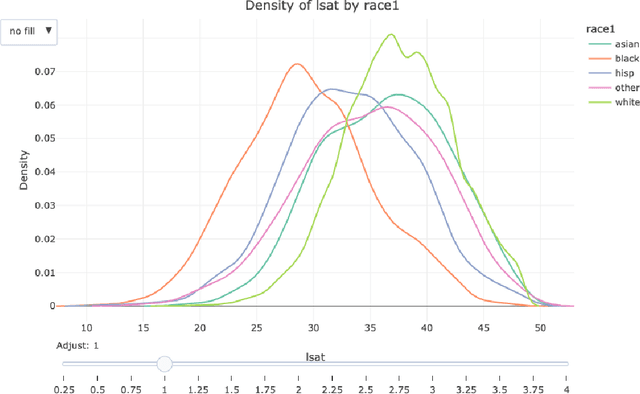
The growing power of data science can play a crucial role in addressing social discrimination, necessitating nuanced understanding and effective mitigation strategies of potential biases. Data Science Looks At Discrimination (dsld) is an R and Python package designed to provide users with a comprehensive toolkit of statistical and graphical methods for assessing possible discrimination related to protected groups, such as race, gender, and age. Our software offers techniques for discrimination analysis by identifying and mitigating confounding variables, along with methods for reducing bias in predictive models. In educational settings, dsld offers instructors powerful tools to teach important statistical principles through motivating real world examples of discrimination analysis. The inclusion of an 80-page Quarto book further supports users, from statistics educators to legal professionals, in effectively applying these analytical tools to real world scenarios.