 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Harmonization: Federated Clustered Batch Effect Adjustment and Generalization
May 23, 2024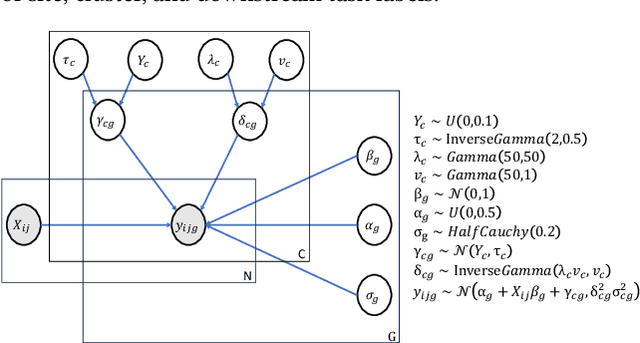


Independent and identically distributed (i.i.d.) data is essential to many data analysis and modeling techniques. In the medical domain, collecting data from multiple sites or institutions is a common strategy that guarantees sufficient clinical diversity, determined by the decentralized nature of medical data. However, data from various sites are easily biased by the local environment or facilities, thereby violating the i.i.d. rule. A common strategy is to harmonize the site bias while retaining important biological information. The ComBat is among the most popular harmonization approaches and has recently been extended to handle distributed sites. However, when faced with situations involving newly joined sites in training or evaluating data from unknown/unseen sites, ComBat lacks compatibility and requires retraining with data from all the sites. The retraining leads to significant computational and logistic overhead that is usually prohibitive. In this work, we develop a novel Cluster ComBat harmonization algorithm, which leverages cluster patterns of the data in different sites and greatly advances the usability of ComBat harmonization. We use extensive simulation and real medical imaging data from ADNI to demonstrate the superiority of the proposed approach.
Towards Stability of Parameter-free Optimization
May 07, 2024



Hyperparameter tuning, particularly the selection of an appropriate learning rate in adaptive gradient training methods, remains a challenge. To tackle this challenge, in this paper, we propose a novel parameter-free optimizer, AdamG (Adam with the golden step size), designed to automatically adapt to diverse optimization problems without manual tuning. The core technique underlying AdamG is our golden step size derived for the AdaGrad-Norm algorithm, which is expected to help AdaGrad-Norm preserve the tuning-free convergence and approximate the optimal step size in expectation w.r.t. various optimization scenarios. To better evaluate tuning-free performance, we propose a novel evaluation criterion, stability, to comprehensively assess the efficacy of parameter-free optimizers in addition to classical performance criteria. Empirical results demonstrate that compared with other parameter-free baselines, AdamG achieves superior performance, which is consistently on par with Adam using a manually tuned learning rate across various optimization tasks.
Stochastic Two Points Method for Deep Model Zeroth-order Optimization
Feb 02, 2024



Large foundation models, such as large language models, have performed exceptionally well in various application scenarios. Building or fully fine-tuning such large models is usually prohibitive due to either hardware budget or lack of access to backpropagation. The zeroth-order methods offer a promising direction for tackling this challenge, where only forward passes are needed to update the model. This paper introduces an efficient Stochastic Two-Point (S2P) approach within the gradient-free regime. We present the theoretical convergence properties of S2P under the general and relaxed smoothness assumptions. The theoretical properties also shed light on a faster and more stable S2P variant, Accelerated S2P (AS2P), through exploiting our new convergence properties that better represent the dynamics of deep models in training. Our comprehensive empirical results show that AS2P is highly effective in optimizing objectives for large deep models, including language models, and outperforms standard methods across various model types and scales, with 2 $\times$ speed-up in training over most conducted tasks.
RUSH: Robust Contrastive Learning via Randomized Smoothing
Jul 11, 2022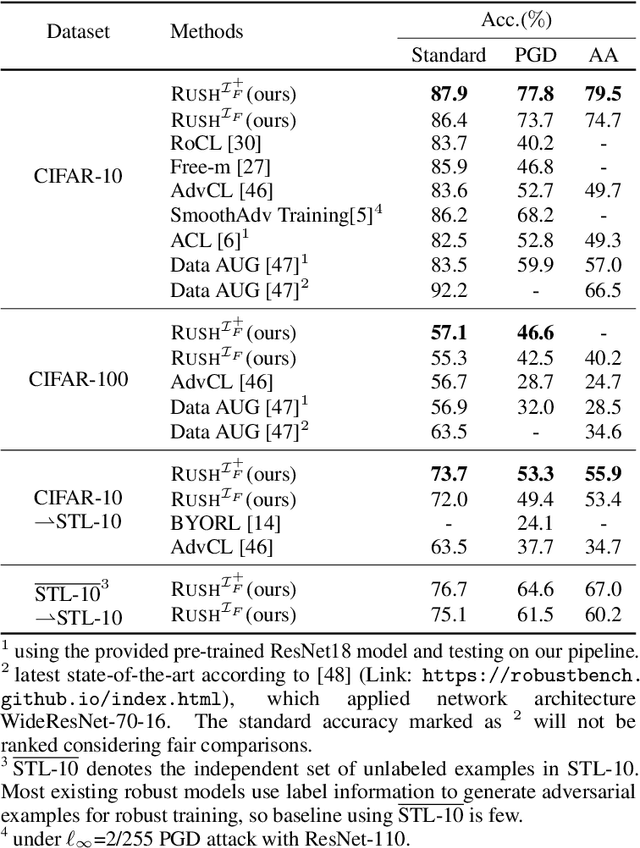
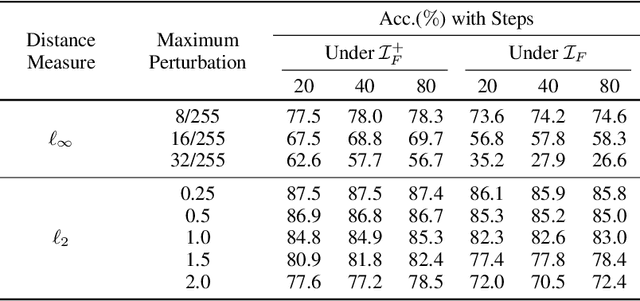
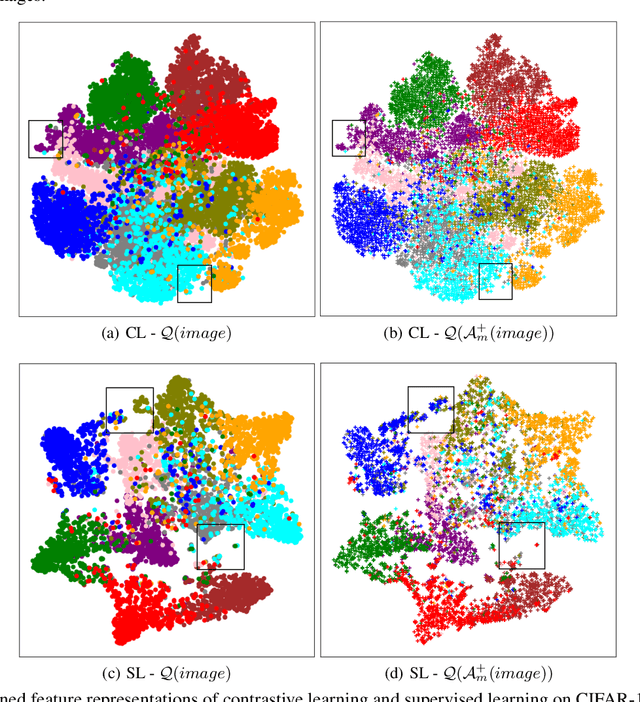
Recently, adversarial training has been incorporated in self-supervised contrastive pre-training to augment label efficiency with exciting adversarial robustness. However, the robustness came at a cost of expensive adversarial training. In this paper, we show a surprising fact that contrastive pre-training has an interesting yet implicit connection with robustness, and such natural robustness in the pre trained representation enables us to design a powerful robust algorithm against adversarial attacks, RUSH, that combines the standard contrastive pre-training and randomized smoothing. It boosts both standard accuracy and robust accuracy, and significantly reduces training costs as compared with adversarial training. We use extensive empirical studies to show that the proposed RUSH outperforms robust classifiers from adversarial training, by a significant margin on common benchmarks (CIFAR-10, CIFAR-100, and STL-10) under first-order attacks. In particular, under $\ell_{\infty}$-norm perturbations of size 8/255 PGD attack on CIFAR-10, our model using ResNet-18 as backbone reached 77.8% robust accuracy and 87.9% standard accuracy. Our work has an improvement of over 15% in robust accuracy and a slight improvement in standard accuracy, compared to the state-of-the-arts.
Synthesized Trust Learning from Limited Human Feedback for Human-Load-Reduced Multi-Robot Deployments
Apr 07, 2021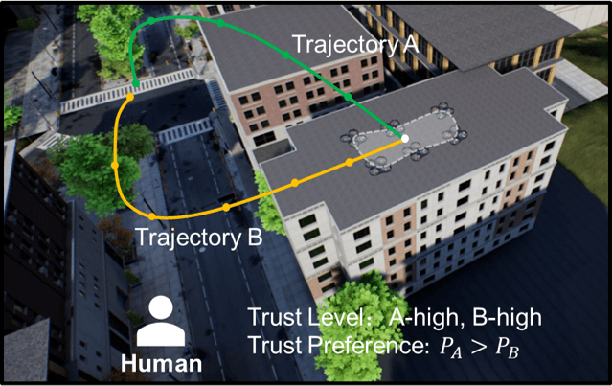
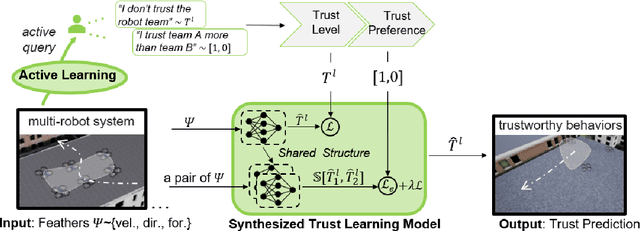
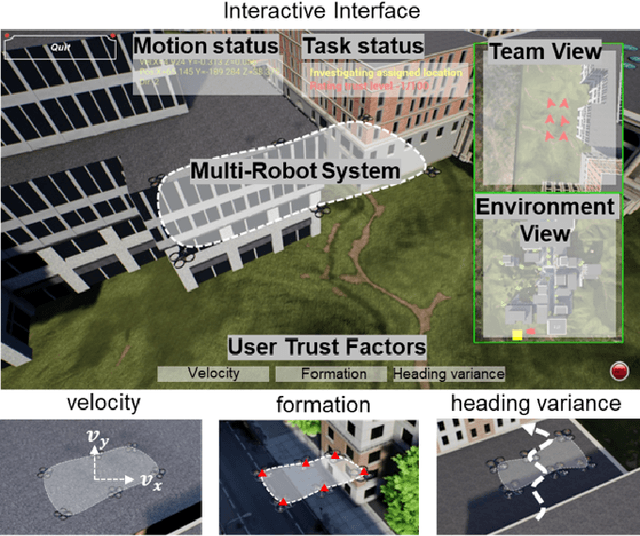
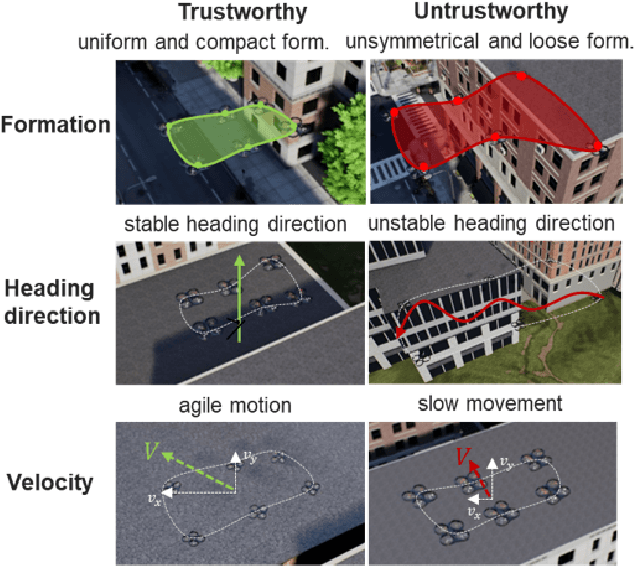
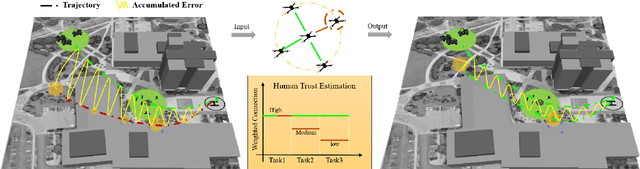
Human multi-robot system (MRS) collaboration is demonstrating potentials in wide application scenarios due to the integration of human cognitive skills and a robot team's powerful capability introduced by its multi-member structure. However, due to limited human cognitive capability, a human cannot simultaneously monitor multiple robots and identify the abnormal ones, largely limiting the efficiency of the human-MRS collaboration. There is an urgent need to make robots understand human expectations to proactively reduce unnecessary human engagements and further reduce human cognitive loads. Human trust in human MRS collaboration reveals human expectations on robot performance. Based on trust estimation, the work between a human and MRS will be reallocated that an MRS will self-monitor and only request human guidance in critical situations. Inspired by that, a novel Synthesized Trust Learning (STL) method was developed to model human trust in the collaboration. STL explores two aspects of human trust (trust level and trust preference), meanwhile accelerates the convergence speed by integrating active learning to reduce human workload. To validate the effectiveness of the method, tasks "searching victims in the context of city rescue" were designed in an open-world simulation environment, and a user study with 10 volunteers was conducted to generate real human trust feedback. The results showed that by maximally utilizing human feedback, the STL achieved higher accuracy in trust modeling with a few human feedback, effectively reducing human interventions needed for modeling an accurate trust, therefore reducing human cognitive load in the collaboration.
Trust Aware Emergency Response for A Resilient Human-Swarm Cooperative System
Jun 27, 2020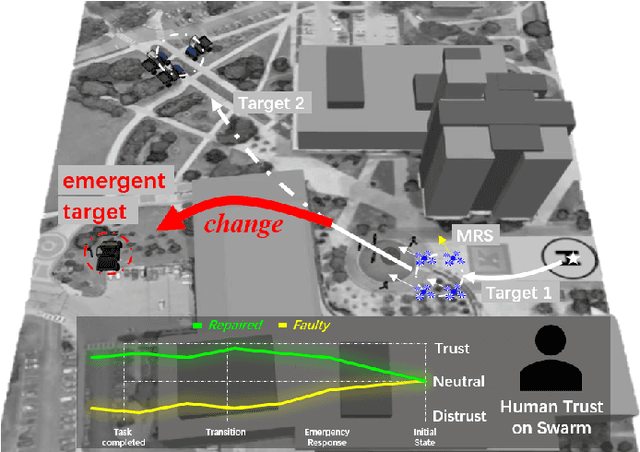
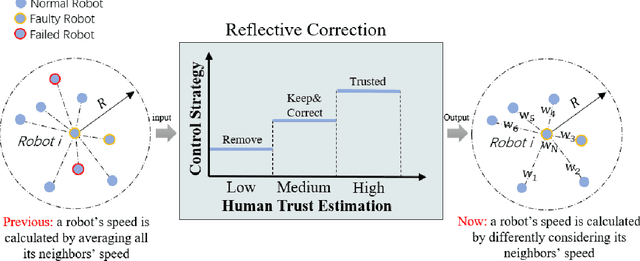
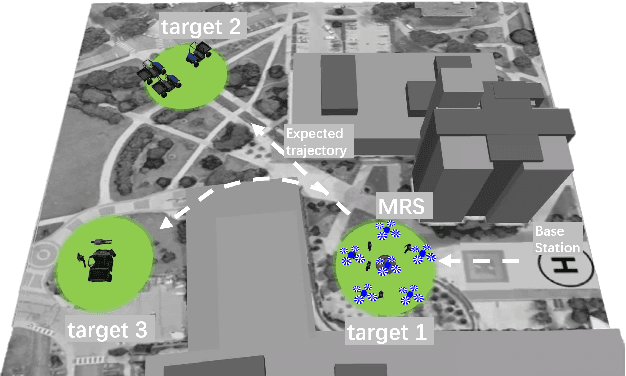
A human-swarm cooperative system, which mixes multiple robots and a human supervisor to form a heterogeneous team, is widely used for emergent scenarios such as criminal tracking in social security and victim assistance in a natural disaster. These emergent scenarios require a cooperative team to quickly terminate the current task and transit the system to a new task, bringing difficulty in motion planning. Moreover, due to the immediate task transitions, uncertainty from both physical systems and prior tasks is accumulated to decrease swarm performance, causing robot failures and influencing the cooperation effectiveness between the human and the robot swarm. Therefore, given the quick-transition requirements and the introduced uncertainty, it is challenging for a human-swarm system to respond to emergent tasks, compared with executing normal tasks where a gradual transition between tasks is allowed. Human trust reveals the behavior expectations of others and is used to adjust unsatisfactory behaviors for better cooperation. Inspired by human trust, in this paper, a trust-aware reflective control (Trust-R) is developed to dynamically calibrate human-swarm cooperation. Trust-R, based on a weighted mean subsequence reduced algorithm (WMSR) and human trust modeling, helps a swarm to self-reflect its performance from the perspective of human trust; then proactively correct its faulty behaviors in an early stage before a human intervenes. One typical task scenario {emergency response} was designed in the real-gravity simulation environment, and a human user study with 145 volunteers was conducted. Trust-R's effectiveness in correcting faulty behaviors in emergency response was validated by the improved swarm performance and increased trust scores.
Trust Repairing for Human-Swarm Cooperation inDynamic Task Response
Feb 18, 2020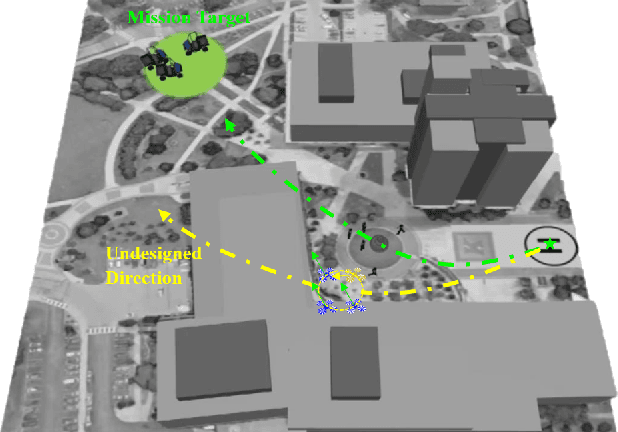
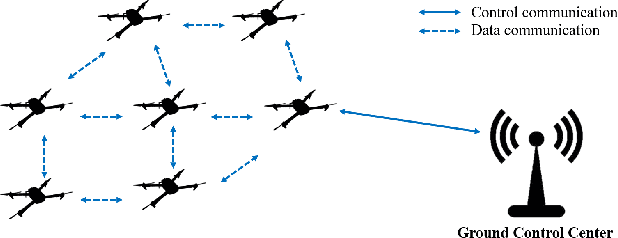
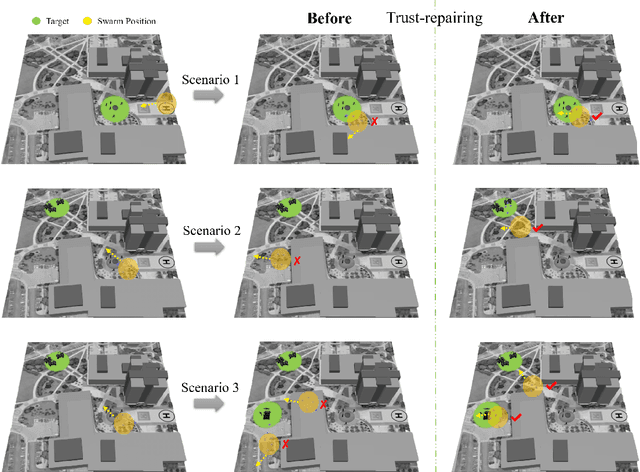
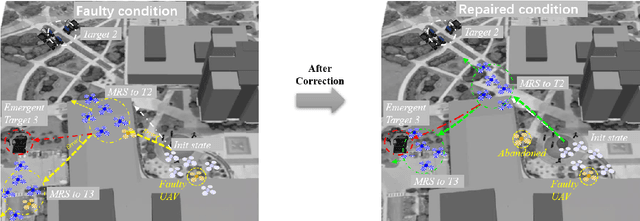
Emergency happens in human-UAV cooperation, such as criminal activity tracking and urgent needs for ground assistance. Emergency response usually has high requirements on the motion control of the multi-UAV system, by maintaining both the team performance and team behaviors. However When a UAV swarm executes tasks in a real-world environment, because of real-world factors, such as system reliability and environmental disturbances, some robots in the swarm will behave abnormally, such as slow flocking speed, wrong heading direction, or poor spatial relations. In the meanwhile, incorrect trust between human and UAV swarm could map the abnormal behavior of faulty robot to the whole swarm and request a time-consuming intervention from human supervisor, damage the UAV swarm response for a dynamic task, even evolve to a failure of task because of accumulated error. To correct reflect the trust between humans and UAV swarm and rebuild the trust to improve the performance caused by incorrect trust. We propose a dynamic trust repair model. The dynamic trust model focus on human-supervisory UAV system which can help UAV swarm to reduce the negative influence from faulty UAV on the performance of the UAV swarm, get a flexible reaction and stable human-supervisory UAV task performance. Results show that trust model could improve the performance of the swarm for dynamic task response and regain human trust.
Proficiency Aware Multi-Agent Actor-Critic for Mixed Aerial and Ground Robot Teaming
Feb 10, 2020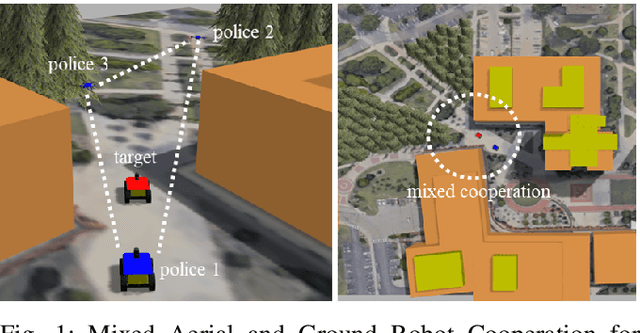
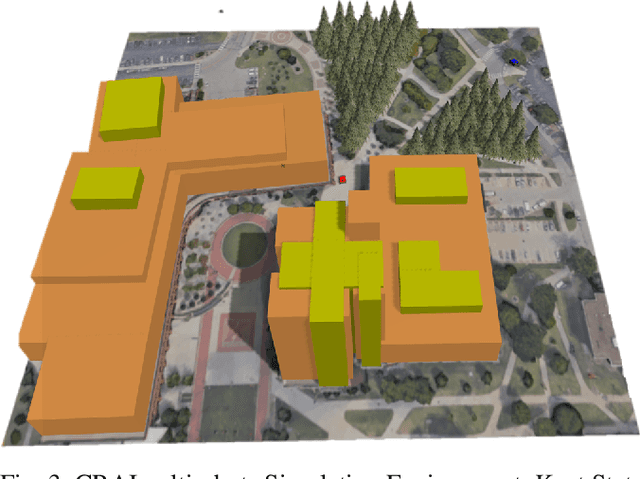
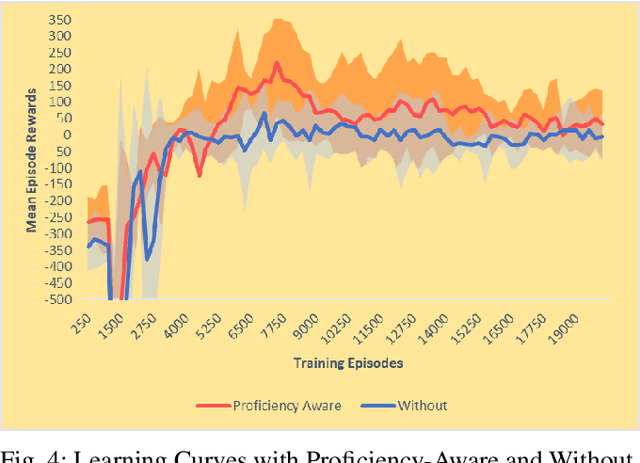
Mixed Cooperation and competition are the actual scenarios of deploying multi-robot systems, such as the multi-UAV/UGV teaming for tracking criminal vehicles and protecting important individuals. Types and the total number of robot are all important factors that influence mixed cooperation quality. In various real-world environments, such as open space, forest, and urban building clusters, robot deployments have been influenced largely, as different robots have different configurations to support different environments. For example, UGVs are good at moving on the urban roads and reach the forest area while UAVs are good at flying in open space and around the high building clusters. However, it is challenging to design the collective behaviors for robot cooperation according to the dynamic changes in robot capabilities, working status, and environmental constraints. To solve this question, we proposed a novel proficiency-aware mixed environment multi-agent deep reinforcement learning (Mix-DRL). In Mix-DRL, robot capability and environment factors are formalized into the model to update the policy to model the nonlinear relations between heterogeneous team deployment strategies and the real-world environmental conditions. Mix-DRL can largely exploit robot capability while staying aware of the environment limitations. With the validation of a heterogeneous team with 2 UAVs and 2 UGVs in tasks, such as social security for criminal vehicle tracking, the Mix-DRL's effectiveness has been evaluated with $14.20\%$ of cooperation improvement. Given the general setting of Mix-DRL, it can be used to guide the general cooperation of UAVs and UGVs for multi-target tracking.