 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Learning Necessary and Sufficient Causal Graphs
Paper and Code
Jan 29, 2023
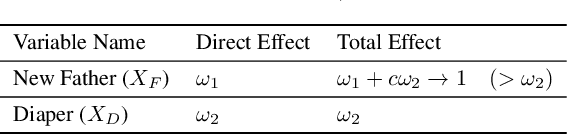
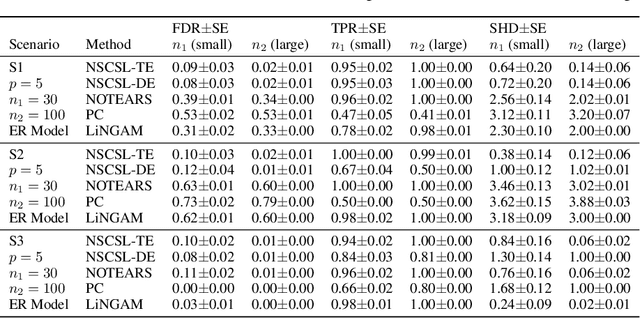
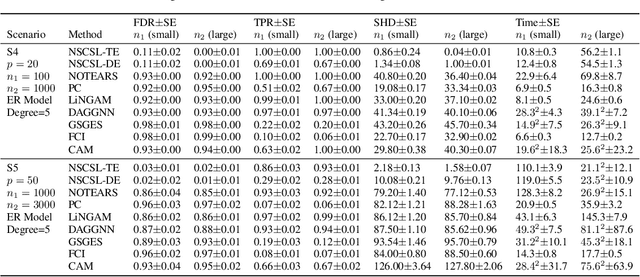
The causal revolution has spurred interest in understanding complex relationships in various fields. Most existing methods aim to discover causal relationships among all variables in a large-scale complex graph. However, in practice, only a small number of variables in the graph are relevant for the outcomes of interest. As a result, causal estimation with the full causal graph -- especially given limited data -- could lead to many falsely discovered, spurious variables that may be highly correlated with but have no causal impact on the target outcome. In this paper, we propose to learn a class of necessary and sufficient causal graphs (NSCG) that only contains causally relevant variables for an outcome of interest, which we term causal features. The key idea is to utilize probabilities of causation to systematically evaluate the importance of features in the causal graph, allowing us to identify a subgraph that is relevant to the outcome of interest. To learn NSCG from data, we develop a score-based necessary and sufficient causal structural learning (NSCSL) algorithm, by establishing theoretical relationships between probabilities of causation and causal effects of features. Across empirical studies of simulated and real data, we show that the proposed NSCSL algorithm outperforms existing algorithms and can reveal important yeast genes for target heritable traits of interest.