 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Generalizable Human Motion Generator with Reinforcement Learning
Paper and Code
May 24, 2024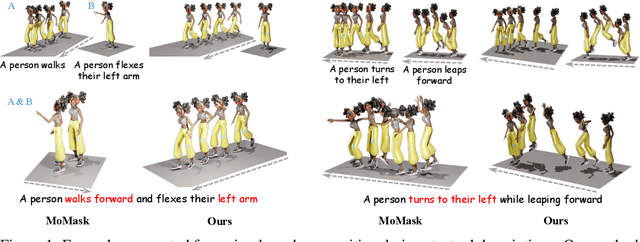
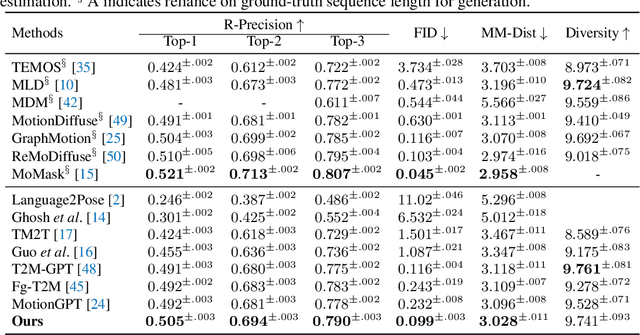
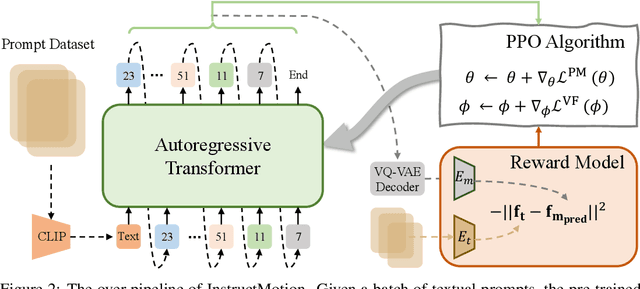
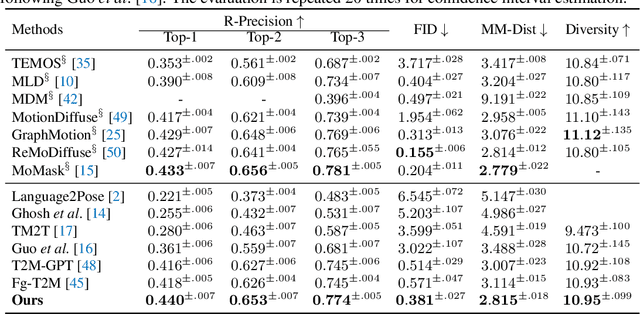
Text-driven human motion generation, as one of the vital tasks in computer-aided content creation, has recently attracted increasing attention. While pioneering research has largely focused on improving numerical performance metrics on given datasets, practical applications reveal a common challenge: existing methods often overfit specific motion expressions in the training data, hindering their ability to generalize to novel descriptions like unseen combinations of motions. This limitation restricts their broader applicability. We argue that the aforementioned problem primarily arises from the scarcity of available motion-text pairs, given the many-to-many nature of text-driven motion generation. To tackle this problem, we formulate text-to-motion generation as a Markov decision process and present \textbf{InstructMotion}, which incorporate the trail and error paradigm in reinforcement learning for generalizable human motion generation. Leveraging contrastive pre-trained text and motion encoders, we delve into optimizing reward design to enable InstructMotion to operate effectively on both paired data, enhancing global semantic level text-motion alignment, and synthetic text-only data, facilitating better generalization to novel prompts without the need for ground-truth motion supervision. Extensive experiments on prevalent benchmarks and also our synthesized unpaired dataset demonstrate that the proposed InstructMotion achieves outstanding performance both quantitatively and qualitatively.