 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-level Contrastive Learning Framework for Sequential Recommendation
Aug 27, 2022
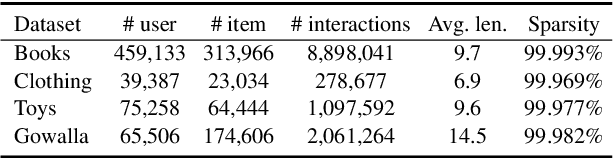
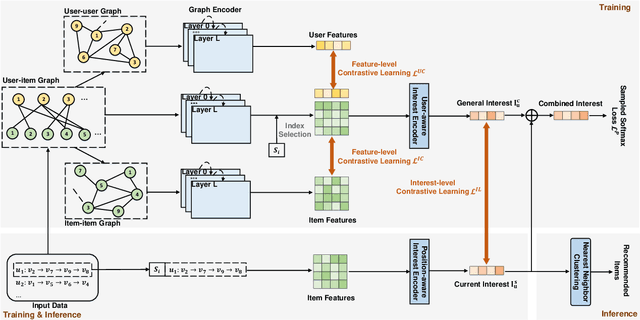
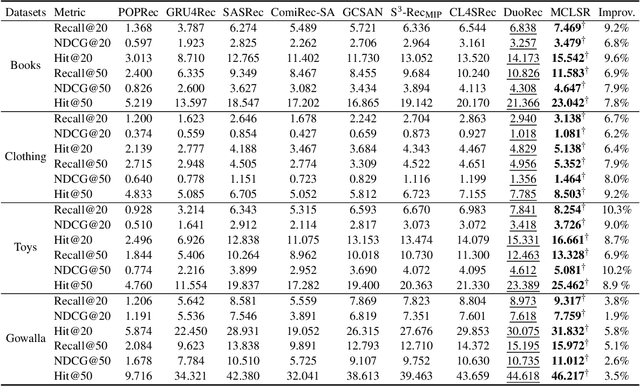
Sequential recommendation (SR) aims to predict the subsequent behaviors of users by understanding their successive historical behaviors. Recently, some methods for SR are devoted to alleviating the data sparsity problem (i.e., limited supervised signals for training), which take account of contrastive learning to incorporate self-supervised signals into SR. Despite their achievements, it is far from enough to learn informative user/item embeddings due to the inadequacy modeling of complex collaborative information and co-action information, such as user-item relation, user-user relation, and item-item relation. In this paper, we study the problem of SR and propose a novel multi-level contrastive learning framework for sequential recommendation, named MCLSR. Different from the previous contrastive learning-based methods for SR, MCLSR learns the representations of users and items through a cross-view contrastive learning paradigm from four specific views at two different levels (i.e., interest- and feature-level). Specifically, the interest-level contrastive mechanism jointly learns the collaborative information with the sequential transition patterns, and the feature-level contrastive mechanism re-observes the relation between users and items via capturing the co-action information (i.e., co-occurrence). Extensive experiments on four real-world datasets show that the proposed MCLSR outperforms the state-of-the-art methods consistently.
Learning User Representations with Hypercuboids for Recommender Systems
Nov 11, 2020
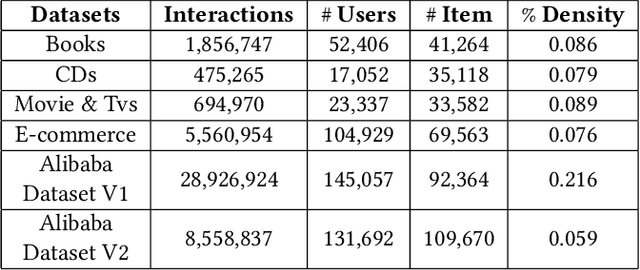
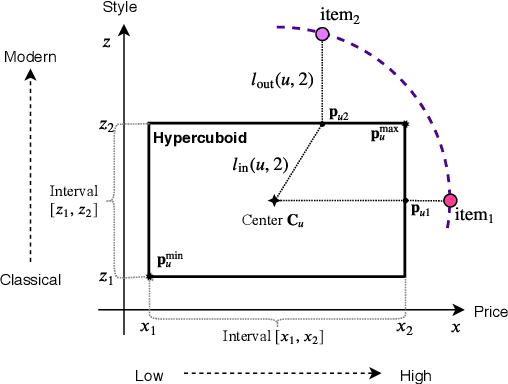
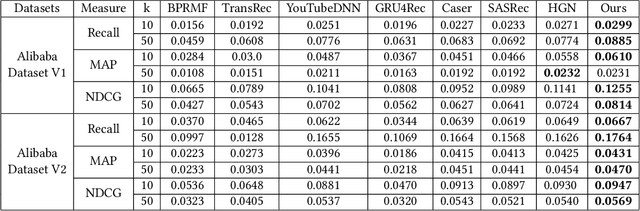
Modeling user interests is crucial in real-world recommender systems. In this paper, we present a new user interest representation model for personalized recommendation. Specifically, the key novelty behind our model is that it explicitly models user interests as a hypercuboid instead of a point in the space. In our approach, the recommendation score is learned by calculating a compositional distance between the user hypercuboid and the item. This helps to alleviate the potential geometric inflexibility of existing collaborative filtering approaches, enabling a greater extent of modeling capability. Furthermore, we present two variants of hypercuboids to enhance the capability in capturing the diversities of user interests. A neural architecture is also proposed to facilitate user hypercuboid learning by capturing the activity sequences (e.g., buy and rate) of users. We demonstrate the effectiveness of our proposed model via extensive experiments on both public and commercial datasets. Empirical results show that our approach achieves very promising results, outperforming existing state-of-the-art.
Contextual-Bandit Based Personalized Recommendation with Time-Varying User Interests
Feb 29, 2020
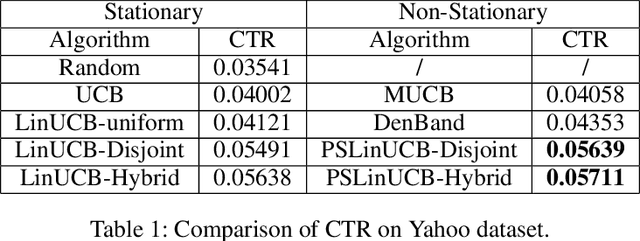
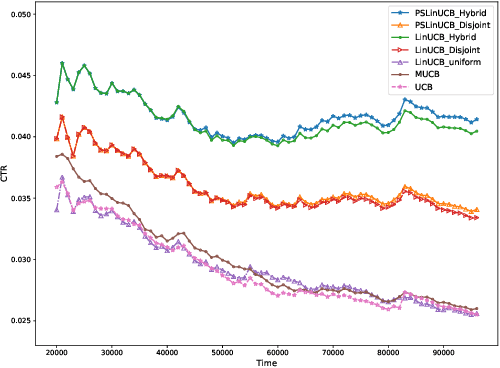
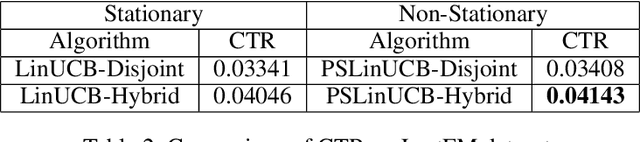
A contextual bandit problem is studied in a highly non-stationary environment, which is ubiquitous in various recommender systems due to the time-varying interests of users. Two models with disjoint and hybrid payoffs are considered to characterize the phenomenon that users' preferences towards different items vary differently over time. In the disjoint payoff model, the reward of playing an arm is determined by an arm-specific preference vector, which is piecewise-stationary with asynchronous and distinct changes across different arms. An efficient learning algorithm that is adaptive to abrupt reward changes is proposed and theoretical regret analysis is provided to show that a sublinear scaling of regret in the time length $T$ is achieved. The algorithm is further extended to a more general setting with hybrid payoffs where the reward of playing an arm is determined by both an arm-specific preference vector and a joint coefficient vector shared by all arms. Empirical experiments are conducted on real-world datasets to verify the advantages of the proposed learning algorithms against baseline ones in both settings.