 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHG-PIPE: Vision Transformer Acceleration with Hybrid-Grained Pipeline
Paper and Code
Jul 25, 2024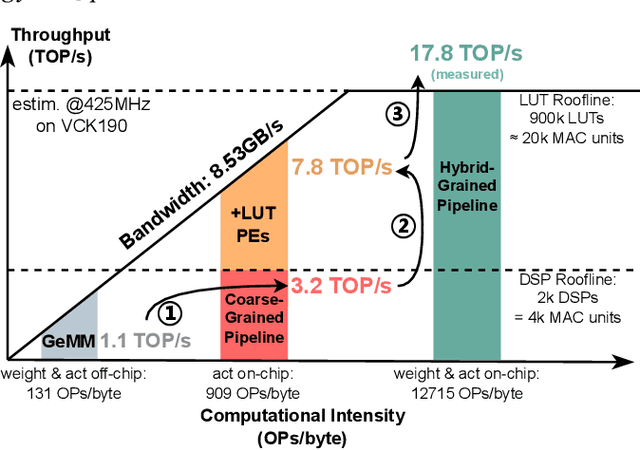
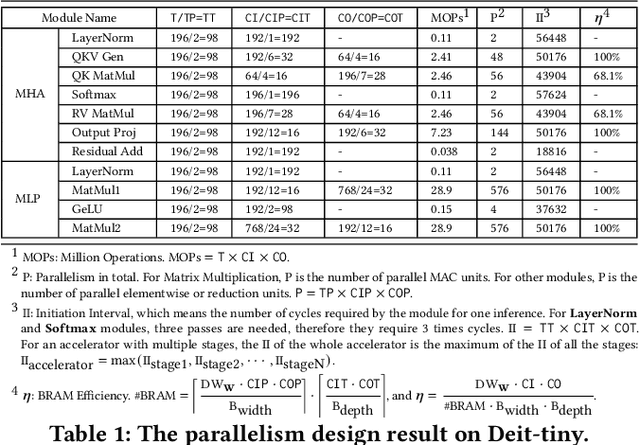
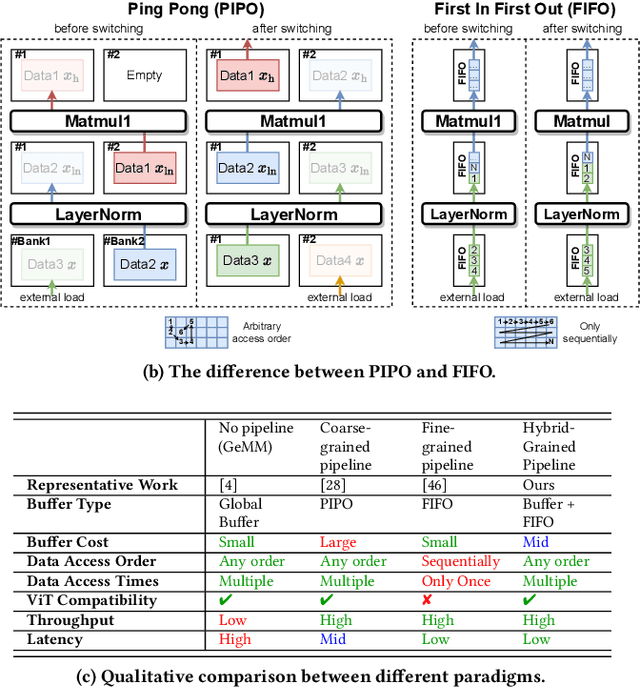
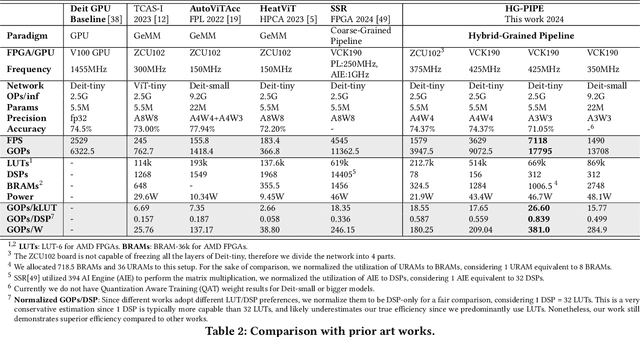
Vision Transformer (ViT) acceleration with field programmable gate array (FPGA) is promising but challenging. Existing FPGA-based ViT accelerators mainly rely on temporal architectures, which process different operators by reusing the same hardware blocks and suffer from extensive memory access overhead. Pipelined architectures, either coarse-grained or fine-grained, unroll the ViT computation spatially for memory access efficiency. However, they usually suffer from significant hardware resource constraints and pipeline bubbles induced by the global computation dependency of ViT. In this paper, we introduce HG-PIPE, a pipelined FPGA accelerator for high-throughput and low-latency ViT processing. HG-PIPE features a hybrid-grained pipeline architecture to reduce on-chip buffer cost and couples the computation dataflow and parallelism design to eliminate the pipeline bubbles. HG-PIPE further introduces careful approximations to implement both linear and non-linear operators with abundant Lookup Tables (LUTs), thus alleviating resource constraints. On a ZCU102 FPGA, HG-PIPE achieves 2.78 times better throughput and 2.52 times better resource efficiency than the prior-art accelerators, e.g., AutoViTAcc. With a VCK190 FPGA, HG-PIPE realizes end-to-end ViT acceleration on a single device and achieves 7118 images/s, which is 2.81 times faster than a V100 GPU.