 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSKG Hub: An Expert-Guided Platform for LLM-Empowered Sustainability Standards Knowledge Graphs
Feb 28, 2026Sustainability disclosure standards (e.g., GRI, SASB, TCFD, IFRS S2) are comprehensive yet lengthy, terminology-dense, and highly cross-referential, hindering structured analysis and downstream use. We present SSKG Hub (Sustainability Standards Knowledge Graph Hub), a research prototype and interactive web platform that transforms standards into auditable knowledge graphs (KGs) through an LLM-centered, expert-guided pipeline. The system integrates automatic standard identification, configurable chunking, standard-specific prompting, robust triple parsing, and provenance-aware Neo4j storage with fine-grained audit metadata. LLM extraction produces a provenance-linked Draft KG, which is reviewed, curated, and formally promoted to a Certified KG through meta-expert adjudication. A role-based governance framework covering read-only guest access, expert review and CRUD operations, meta-expert certification, and administrative oversight ensures traceability and accountability across draft and certified states. Beyond graph exploration and triple-level evidence tracing, SSKG Hub supports cross-KG fusion, KG-driven tasks, and dedicated modules for insights and curated resources. We validate the platform through a comprehensive expert-led KG review case study that demonstrates end-to-end curation and quality assurance. The web application is publicly available at www.sskg-hub.com.
SP^2DPO: An LLM-assisted Semantic Per-Pair DPO Generalization
Jan 29, 2026Direct Preference Optimization (DPO) controls the trade-off between fitting preference labels and staying close to a reference model using a single global temperature beta, implicitly treating all preference pairs as equally informative. Real-world preference corpora are heterogeneous: they mix high-signal, objective failures (for example, safety, factuality, instruction violations) with low-signal or subjective distinctions (for example, style), and also include label noise. We introduce our method, SP2DPO (Semantic Per-Pair DPO), a generalization that replaces the global temperature with an instance-specific schedule beta_i pre-decided offline from structured semantic-gap annotations (category, magnitude, confidence) produced by teacher language models. We instantiate this procedure on the UltraFeedback preference corpus (59,960 pairs), enabling large-scale construction of an auditable beta_i artifact, and incur zero training-time overhead: the inner-loop optimizer remains standard DPO with beta set per pair. We focus our empirical study on AlpacaEval 2.0, reporting both raw win rate and length-controlled win rate. Across four open-weight, instruction-tuned student backbones (4B-8B), SP2DPO is competitive with a tuned global-beta DPO baseline and improves AlpacaEval 2.0 length-controlled win rate on two of four backbones, while avoiding per-model beta sweeps. All code, annotations, and artifacts will be released.
Multi-Scale Quasi-RNN for Next Item Recommendation
Feb 26, 2019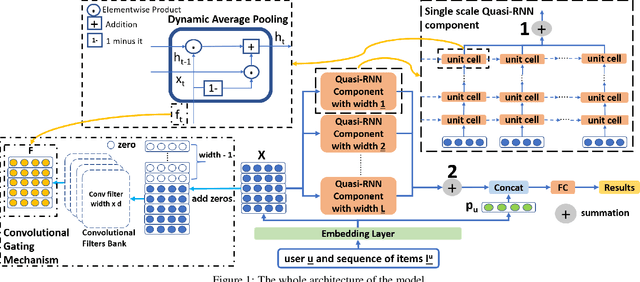
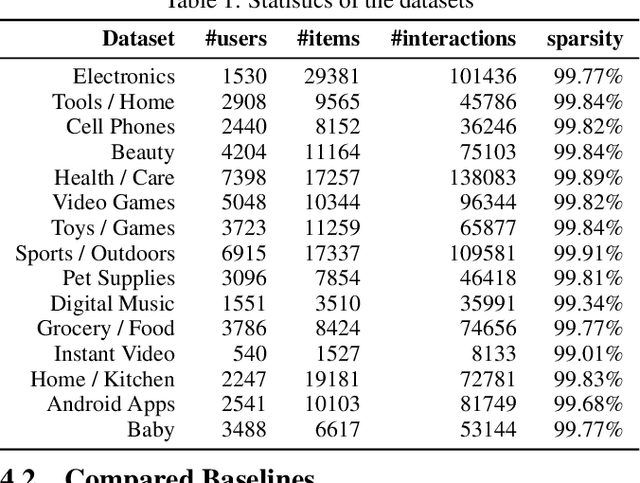
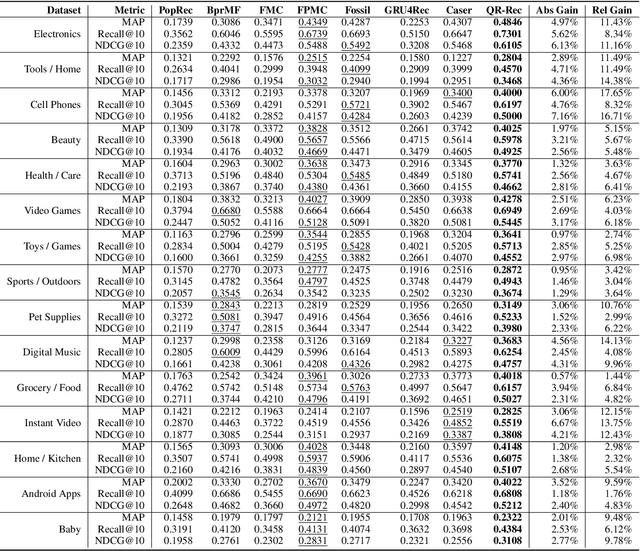
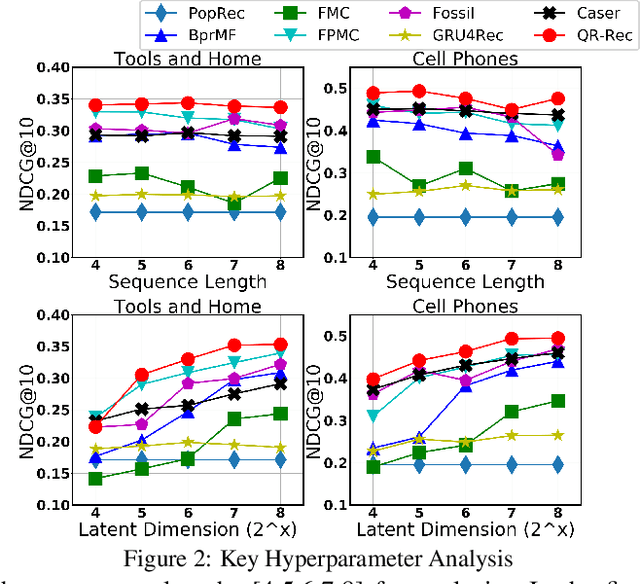
How to better utilize sequential information has been extensively studied in the setting of recommender systems. To this end, architectural inductive biases such as Markov-Chains, Recurrent models, Convolutional networks and many others have demonstrated reasonable success on this task. This paper proposes a new neural architecture, multi-scale Quasi-RNN for next item Recommendation (QR-Rec) task. Our model provides the best of both worlds by exploiting multi-scale convolutional features as the compositional gating functions of a recurrent cell. The model is implemented in a multi-scale fashion, i.e., convolutional filters of various widths are implemented to capture different union-level features of input sequences which influence the compositional encoder. The key idea aims to capture the recurrent relations between different kinds of local features, which has never been studied previously in the context of recommendation. Through extensive experiments, we demonstrate that our model achieves state-of-the-art performance on 15 well-established datasets, outperforming strong competitors such as FPMC, Fossil and Caser absolutely by 0.57%-7.16% and relatively by 1.44%-17.65% in terms of MAP, Recall@10 and NDCG@10.