 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteger-Only Neural Network Quantization Scheme Based on Shift-Batch-Normalization
Paper and Code
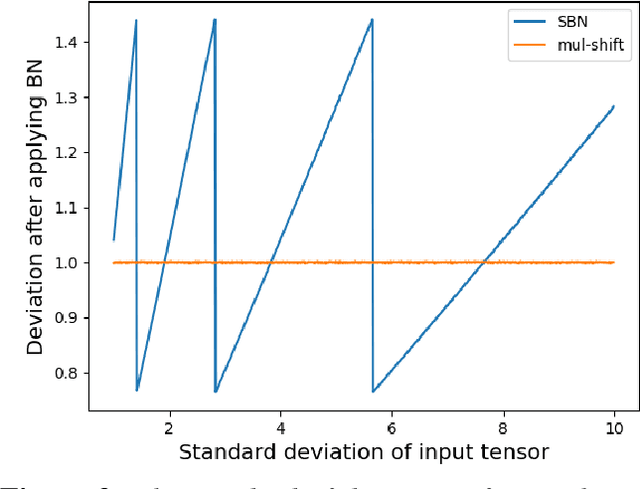
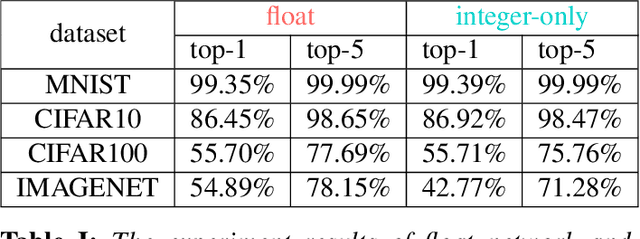
Neural networks are very popular in many areas, but great computing complexity makes it hard to run neural networks on devices with limited resources. To address this problem, quantization methods are used to reduce model size and computation cost, making it possible to use neural networks on embedded platforms or mobile devices. In this paper, an integer-only-quantization scheme is introduced. This scheme uses one layer that combines shift-based batch normalization and uniform quantization to implement 4-bit integer-only inference. Without big integer multiplication(which is used in previous integer-only-quantization methods), this scheme can achieve good power and latency efficiency, and is especially suitable to be deployed on co-designed hardware platforms. Tests have proved that this scheme works very well for easy tasks. And for tough tasks, performance loss can be tolerated for its inference efficiency. Our work is available on github: https://github.com/hguq/IntegerNet.