 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Theoretical Understanding of Hashing-Based Neural Nets
Paper and Code
Dec 26, 2018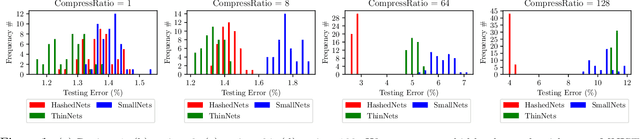
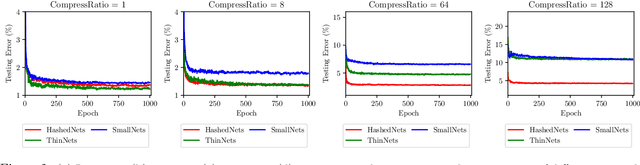
Parameter reduction has been an important topic in deep learning due to the ever-increasing size of deep neural network models and the need to train and run them on resource limited machines. Despite many efforts in this area, there were no rigorous theoretical guarantees on why existing neural net compression methods should work. In this paper, we provide provable guarantees on some hashing-based parameter reduction methods in neural nets. First, we introduce a neural net compression scheme based on random linear sketching (which is usually implemented efficiently via hashing), and show that the sketched (smaller) network is able to approximate the original network on all input data coming from any smooth and well-conditioned low-dimensional manifold. The sketched network can also be trained directly via back-propagation. Next, we study the previously proposed HashedNets architecture and show that the optimization landscape of one-hidden-layer HashedNets has a local strong convexity property similar to a normal fully connected neural network. We complement our theoretical results with empirical verifications.