 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdding Multimodal Controls to Whole-body Human Motion Generation
Paper and Code

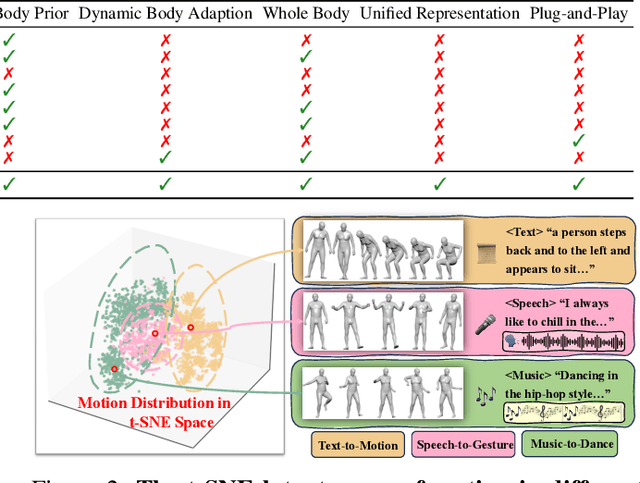
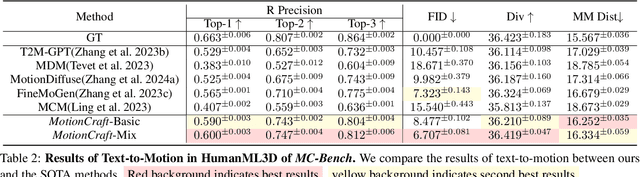
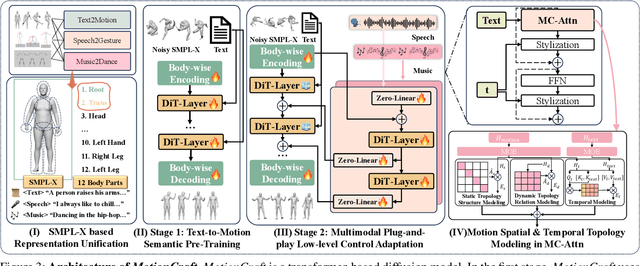
Whole-body multimodal motion generation, controlled by text, speech, or music, has numerous applications including video generation and character animation. However, employing a unified model to accomplish various generation tasks with different condition modalities presents two main challenges: motion distribution drifts across different generation scenarios and the complex optimization of mixed conditions with varying granularity. Furthermore, inconsistent motion formats in existing datasets further hinder effective multimodal motion generation. In this paper, we propose ControlMM, a unified framework to Control whole-body Multimodal Motion generation in a plug-and-play manner. To effectively learn and transfer motion knowledge across different motion distributions, we propose ControlMM-Attn, for parallel modeling of static and dynamic human topology graphs. To handle conditions with varying granularity, ControlMM employs a coarse-to-fine training strategy, including stage-1 text-to-motion pre-training for semantic generation and stage-2 multimodal control adaptation for conditions of varying low-level granularity. To address existing benchmarks' varying motion format limitations, we introduce ControlMM-Bench, the first publicly available multimodal whole-body human motion generation benchmark based on the unified whole-body SMPL-X format. Extensive experiments show that ControlMM achieves state-of-the-art performance across various standard motion generation tasks. Our website is at https://yxbian23.github.io/ControlMM.