 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Medical Artificial General Intelligence via Knowledge-Enhanced Multimodal Pretraining
Apr 26, 2023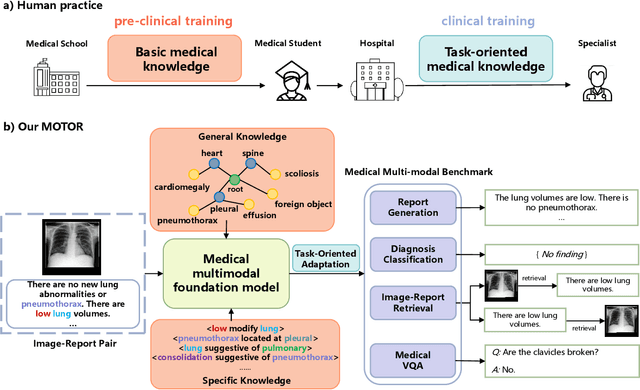

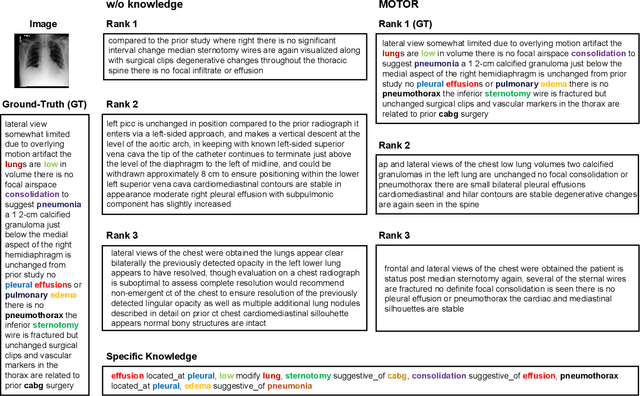
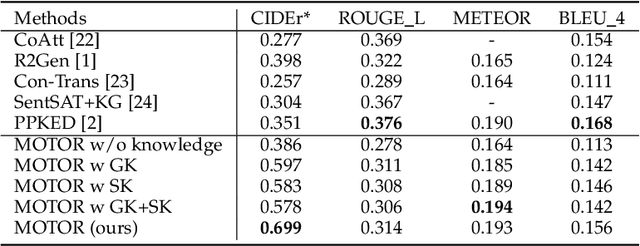
Medical artificial general intelligence (MAGI) enables one foundation model to solve different medical tasks, which is very practical in the medical domain. It can significantly reduce the requirement of large amounts of task-specific data by sufficiently sharing medical knowledge among different tasks. However, due to the challenges of designing strongly generalizable models with limited and complex medical data, most existing approaches tend to develop task-specific models. To take a step towards MAGI, we propose a new paradigm called Medical-knOwledge-enhanced mulTimOdal pretRaining (MOTOR). In MOTOR, we combine two kinds of basic medical knowledge, i.e., general and specific knowledge, in a complementary manner to boost the general pretraining process. As a result, the foundation model with comprehensive basic knowledge can learn compact representations from pretraining radiographic data for better cross-modal alignment. MOTOR unifies the understanding and generation, which are two kinds of core intelligence of an AI system, into a single medical foundation model, to flexibly handle more diverse medical tasks. To enable a comprehensive evaluation and facilitate further research, we construct a medical multimodal benchmark including a wide range of downstream tasks, such as chest x-ray report generation and medical visual question answering. Extensive experiments on our benchmark show that MOTOR obtains promising results through simple task-oriented adaptation. The visualization shows that the injected knowledge successfully highlights key information in the medical data, demonstrating the excellent interpretability of MOTOR. Our MOTOR successfully mimics the human practice of fulfilling a "medical student" to accelerate the process of becoming a "specialist". We believe that our work makes a significant stride in realizing MAGI.
Dynamic Graph Enhanced Contrastive Learning for Chest X-ray Report Generation
Mar 18, 2023



Automatic radiology reporting has great clinical potential to relieve radiologists from heavy workloads and improve diagnosis interpretation. Recently, researchers have enhanced data-driven neural networks with medical knowledge graphs to eliminate the severe visual and textual bias in this task. The structures of such graphs are exploited by using the clinical dependencies formed by the disease topic tags via general knowledge and usually do not update during the training process. Consequently, the fixed graphs can not guarantee the most appropriate scope of knowledge and limit the effectiveness. To address the limitation, we propose a knowledge graph with Dynamic structure and nodes to facilitate medical report generation with Contrastive Learning, named DCL. In detail, the fundamental structure of our graph is pre-constructed from general knowledge. Then we explore specific knowledge extracted from the retrieved reports to add additional nodes or redefine their relations in a bottom-up manner. Each image feature is integrated with its very own updated graph before being fed into the decoder module for report generation. Finally, this paper introduces Image-Report Contrastive and Image-Report Matching losses to better represent visual features and textual information. Evaluated on IU-Xray and MIMIC-CXR datasets, our DCL outperforms previous state-of-the-art models on these two benchmarks.
* Accepted by CVPR 2023. Project page: https://github.com/mlii0117/DCL
ADAPT: Vision-Language Navigation with Modality-Aligned Action Prompts
May 31, 2022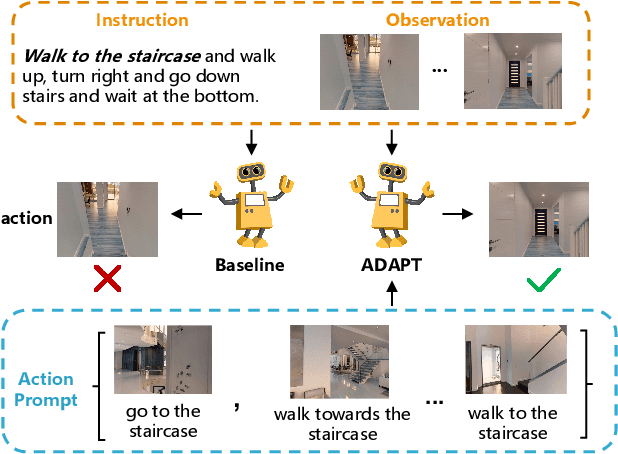

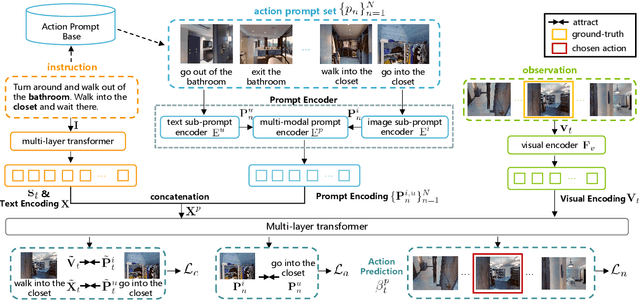

Vision-Language Navigation (VLN) is a challenging task that requires an embodied agent to perform action-level modality alignment, i.e., make instruction-asked actions sequentially in complex visual environments. Most existing VLN agents learn the instruction-path data directly and cannot sufficiently explore action-level alignment knowledge inside the multi-modal inputs. In this paper, we propose modAlity-aligneD Action PrompTs (ADAPT), which provides the VLN agent with action prompts to enable the explicit learning of action-level modality alignment to pursue successful navigation. Specifically, an action prompt is defined as a modality-aligned pair of an image sub-prompt and a text sub-prompt, where the former is a single-view observation and the latter is a phrase like ''walk past the chair''. When starting navigation, the instruction-related action prompt set is retrieved from a pre-built action prompt base and passed through a prompt encoder to obtain the prompt feature. Then the prompt feature is concatenated with the original instruction feature and fed to a multi-layer transformer for action prediction. To collect high-quality action prompts into the prompt base, we use the Contrastive Language-Image Pretraining (CLIP) model which has powerful cross-modality alignment ability. A modality alignment loss and a sequential consistency loss are further introduced to enhance the alignment of the action prompt and enforce the agent to focus on the related prompt sequentially. Experimental results on both R2R and RxR show the superiority of ADAPT over state-of-the-art methods.