 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBREPS: Bounding-Box Robustness Evaluation of Promptable Segmentation
Jan 21, 2026Promptable segmentation models such as SAM have established a powerful paradigm, enabling strong generalization to unseen objects and domains with minimal user input, including points, bounding boxes, and text prompts. Among these, bounding boxes stand out as particularly effective, often outperforming points while significantly reducing annotation costs. However, current training and evaluation protocols typically rely on synthetic prompts generated through simple heuristics, offering limited insight into real-world robustness. In this paper, we investigate the robustness of promptable segmentation models to natural variations in bounding box prompts. First, we conduct a controlled user study and collect thousands of real bounding box annotations. Our analysis reveals substantial variability in segmentation quality across users for the same model and instance, indicating that SAM-like models are highly sensitive to natural prompt noise. Then, since exhaustive testing of all possible user inputs is computationally prohibitive, we reformulate robustness evaluation as a white-box optimization problem over the bounding box prompt space. We introduce BREPS, a method for generating adversarial bounding boxes that minimize or maximize segmentation error while adhering to naturalness constraints. Finally, we benchmark state-of-the-art models across 10 datasets, spanning everyday scenes to medical imaging. Code - https://github.com/emb-ai/BREPS.
RoboBenchMart: Benchmarking Robots in Retail Environment
Nov 13, 2025Most existing robotic manipulation benchmarks focus on simplified tabletop scenarios, typically involving a stationary robotic arm interacting with various objects on a flat surface. To address this limitation, we introduce RoboBenchMart, a more challenging and realistic benchmark designed for dark store environments, where robots must perform complex manipulation tasks with diverse grocery items. This setting presents significant challenges, including dense object clutter and varied spatial configurations -- with items positioned at different heights, depths, and in close proximity. By targeting the retail domain, our benchmark addresses a setting with strong potential for near-term automation impact. We demonstrate that current state-of-the-art generalist models struggle to solve even common retail tasks. To support further research, we release the RoboBenchMart suite, which includes a procedural store layout generator, a trajectory generation pipeline, evaluation tools and fine-tuned baseline models.
SUPER: Selfie Undistortion and Head Pose Editing with Identity Preservation
Jun 18, 2024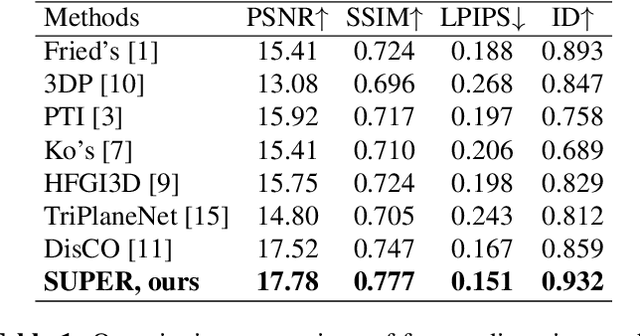
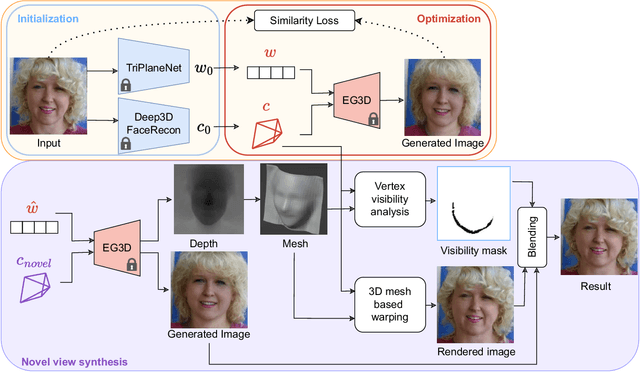
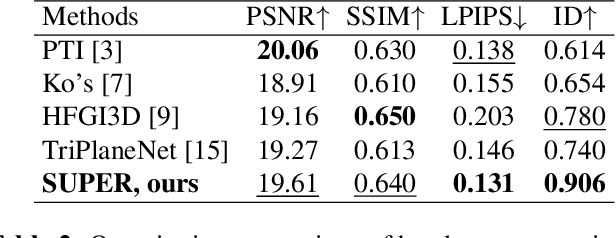

Self-portraits captured from a short distance might look unnatural or even unattractive due to heavy distortions making facial features malformed, and ill-placed head poses. In this paper, we propose SUPER, a novel method of eliminating distortions and adjusting head pose in a close-up face crop. We perform 3D GAN inversion for a facial image by optimizing camera parameters and face latent code, which gives a generated image. Besides, we estimate depth from the obtained latent code, create a depth-induced 3D mesh, and render it with updated camera parameters to obtain a warped portrait. Finally, we apply the visibility-based blending so that visible regions are reprojected, and occluded parts are restored with a generative model. Experiments on face undistortion benchmarks and on our self-collected Head Rotation dataset (HeRo), show that SUPER outperforms previous approaches both qualitatively and quantitatively, opening new possibilities for photorealistic selfie editing.
FIANCEE: Faster Inference of Adversarial Networks via Conditional Early Exits
Apr 20, 2023



Generative DNNs are a powerful tool for image synthesis, but they are limited by their computational load. On the other hand, given a trained model and a task, e.g. faces generation within a range of characteristics, the output image quality will be unevenly distributed among images with different characteristics. It follows, that we might restrain the models complexity on some instances, maintaining a high quality. We propose a method for diminishing computations by adding so-called early exit branches to the original architecture, and dynamically switching the computational path depending on how difficult it will be to render the output. We apply our method on two different SOTA models performing generative tasks: generation from a semantic map, and cross-reenactment of face expressions; showing it is able to output images with custom lower-quality thresholds. For a threshold of LPIPS <=0.1, we diminish their computations by up to a half. This is especially relevant for real-time applications such as synthesis of faces, when quality loss needs to be contained, but most of the inputs need fewer computations than the complex instances.