 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOVE: A Mixture-of-Vision-Encoders Approach for Domain-Focused Vision-Language Processing
Paper and Code

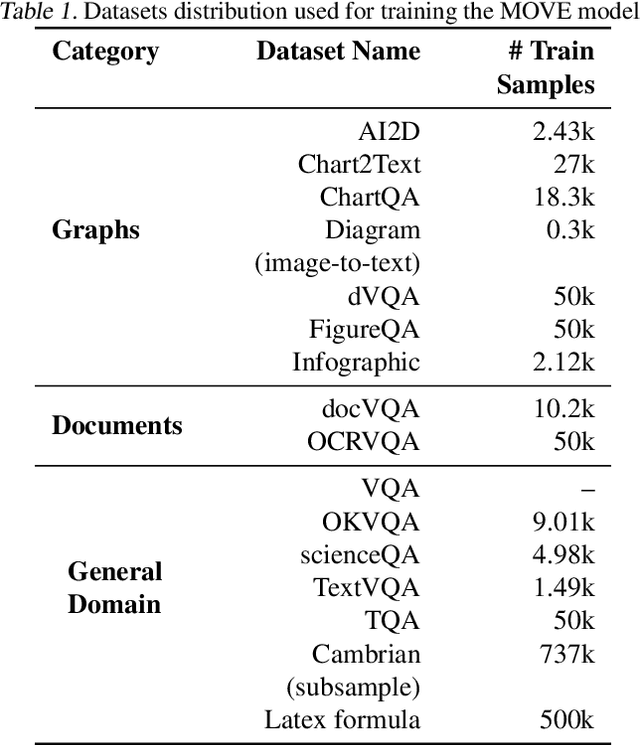


Multimodal language models (MLMs) integrate visual and textual information by coupling a vision encoder with a large language model through the specific adapter. While existing approaches commonly rely on a single pre-trained vision encoder, there is a great variability of specialized encoders that can boost model's performance in distinct domains. In this work, we propose MOVE (Mixture of Vision Encoders) a simple yet effective approach to leverage multiple pre-trained encoders for specialized multimodal tasks. MOVE automatically routes inputs to the most appropriate encoder among candidates such as Unichat, InternViT, and Texify, thereby enhancing performance across a diverse set of benchmarks, including ChartQA, MMBench, and MMMU. Experimental results demonstrate that MOVE achieves competitive accuracy without incurring the complexities of image slicing for high-resolution images.