 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatSchema: A pipeline of extracting structured information with Large Multimodal Models based on schema
Jul 26, 2024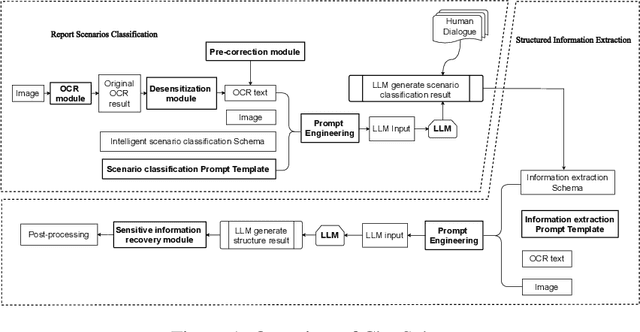

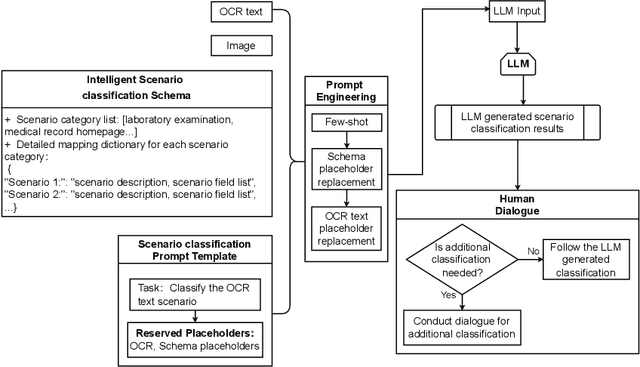

Objective: This study introduces ChatSchema, an effective method for extracting and structuring information from unstructured data in medical paper reports using a combination of Large Multimodal Models (LMMs) and Optical Character Recognition (OCR) based on the schema. By integrating predefined schema, we intend to enable LMMs to directly extract and standardize information according to the schema specifications, facilitating further data entry. Method: Our approach involves a two-stage process, including classification and extraction for categorizing report scenarios and structuring information. We established and annotated a dataset to verify the effectiveness of ChatSchema, and evaluated key extraction using precision, recall, F1-score, and accuracy metrics. Based on key extraction, we further assessed value extraction. We conducted ablation studies on two LMMs to illustrate the improvement of structured information extraction with different input modals and methods. Result: We analyzed 100 medical reports from Peking University First Hospital and established a ground truth dataset with 2,945 key-value pairs. We evaluated ChatSchema using GPT-4o and Gemini 1.5 Pro and found a higher overall performance of GPT-4o. The results are as follows: For the result of key extraction, key-precision was 98.6%, key-recall was 98.5%, key-F1-score was 98.6%. For the result of value extraction based on correct key extraction, the overall accuracy was 97.2%, precision was 95.8%, recall was 95.8%, and F1-score was 95.8%. An ablation study demonstrated that ChatSchema achieved significantly higher overall accuracy and overall F1-score of key-value extraction, compared to the Baseline, with increases of 26.9% overall accuracy and 27.4% overall F1-score, respectively.