 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Decode in Parallel: Self-Coordinating Neural Network for Real-Time Quantum Error Correction
Jan 14, 2026Fast, reliable decoders are pivotal components for enabling fault-tolerant quantum computation (FTQC). Neural network decoders like AlphaQubit have demonstrated potential, achieving higher accuracy than traditional human-designed decoding algorithms. However, existing implementations of neural network decoders lack the parallelism required to decode the syndrome stream generated by a superconducting logical qubit in real time. Moreover, integrating AlphaQubit with sliding window-based parallel decoding schemes presents non-trivial challenges: AlphaQubit is trained solely to output a single bit corresponding to the global logical correction for an entire memory experiment, rather than local physical corrections that can be easily integrated. We address this issue by training a recurrent, transformer-based neural network specifically tailored for parallel window decoding. While it still outputs a single bit, we derive training labels from a consistent set of local corrections and train on various types of decoding windows simultaneously. This approach enables the network to self-coordinate across neighboring windows, facilitating high-accuracy parallel decoding of arbitrarily long memory experiments. As a result, we overcome the throughput bottleneck that previously precluded the use of AlphaQubit-type decoders in FTQC. Our work presents the first scalable, neural-network-based parallel decoding framework that simultaneously achieves SOTA accuracy and the stringent throughput required for real-time quantum error correction. Using an end-to-end experimental workflow, we benchmark our decoder on the Zuchongzhi 3.2 superconducting quantum processor on surface codes with distances up to 7, demonstrating its superior accuracy. Moreover, we demonstrate that, using our approach, a single TPU v6e is capable of decoding surface codes with distances up to 25 within 1us per decoding round.
Integrating Quantum Processor Device and Control Optimization in a Gradient-based Framework
Dec 23, 2021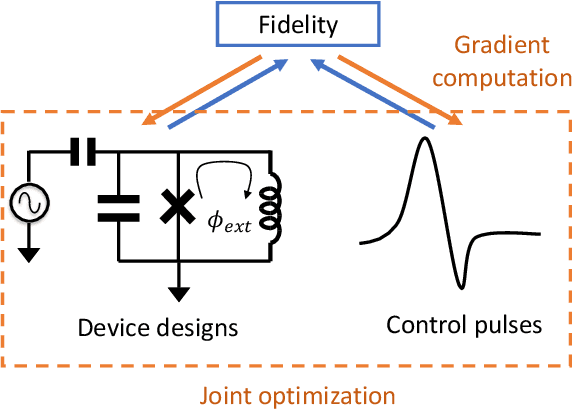
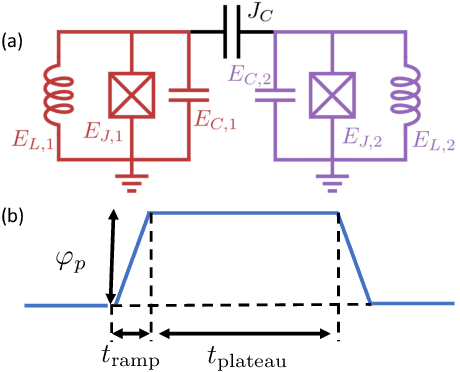
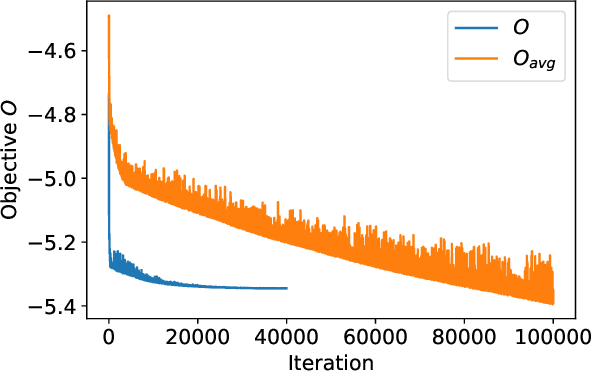
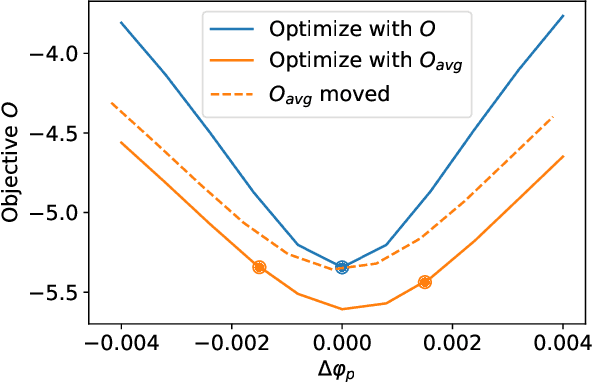
In a quantum processor, the device design and external controls together contribute to the quality of the target quantum operations. As we continuously seek better alternative qubit platforms, we explore the increasingly large device and control design space. Thus, optimization becomes more and more challenging. In this work, we demonstrate that the figure of merit reflecting a design goal can be made differentiable with respect to the device and control parameters. In addition, we can compute the gradient of the design objective efficiently in a similar manner to the back-propagation algorithm and then utilize the gradient to optimize the device and the control parameters jointly and efficiently. This extends the scope of the quantum optimal control to superconducting device design. We also demonstrate the viability of gradient-based joint optimization over the device and control parameters through a few examples.
Background-Click Supervision for Temporal Action Localization
Nov 24, 2021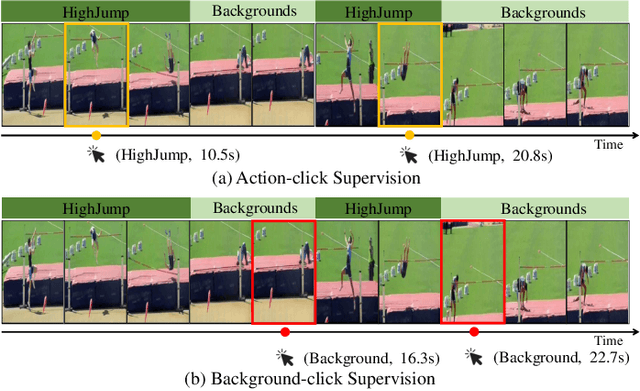
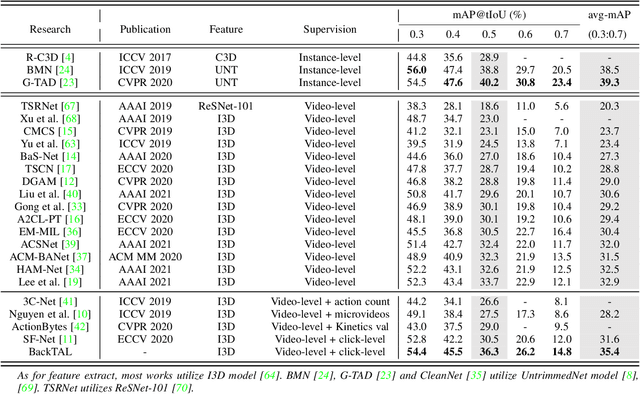
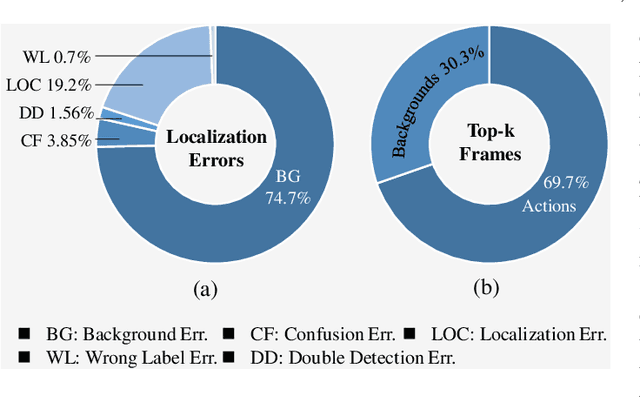
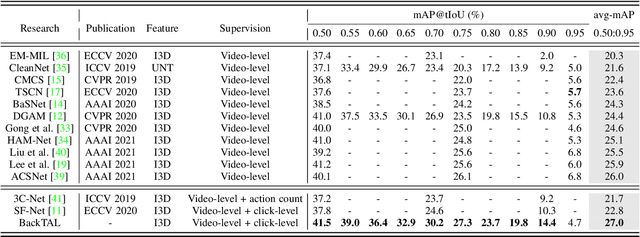
Weakly supervised temporal action localization aims at learning the instance-level action pattern from the video-level labels, where a significant challenge is action-context confusion. To overcome this challenge, one recent work builds an action-click supervision framework. It requires similar annotation costs but can steadily improve the localization performance when compared to the conventional weakly supervised methods. In this paper, by revealing that the performance bottleneck of the existing approaches mainly comes from the background errors, we find that a stronger action localizer can be trained with labels on the background video frames rather than those on the action frames. To this end, we convert the action-click supervision to the background-click supervision and develop a novel method, called BackTAL. Specifically, BackTAL implements two-fold modeling on the background video frames, i.e. the position modeling and the feature modeling. In position modeling, we not only conduct supervised learning on the annotated video frames but also design a score separation module to enlarge the score differences between the potential action frames and backgrounds. In feature modeling, we propose an affinity module to measure frame-specific similarities among neighboring frames and dynamically attend to informative neighbors when calculating temporal convolution. Extensive experiments on three benchmarks are conducted, which demonstrate the high performance of the established BackTAL and the rationality of the proposed background-click supervision. Code is available at https://github.com/VividLe/BackTAL.
Graph-FCN for image semantic segmentation
Jan 02, 2020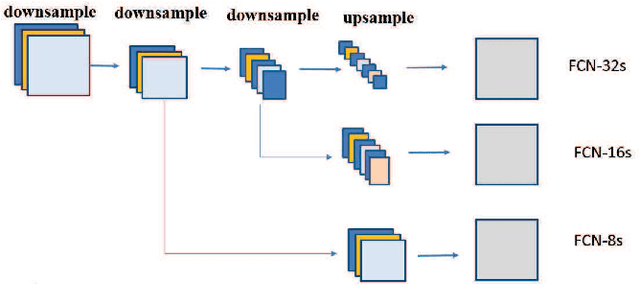
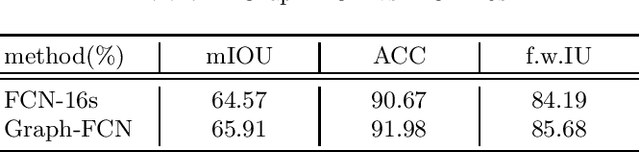
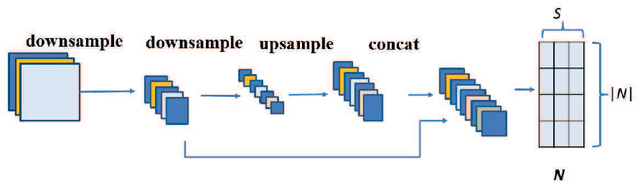
Semantic segmentation with deep learning has achieved great progress in classifying the pixels in the image. However, the local location information is usually ignored in the high-level feature extraction by the deep learning, which is important for image semantic segmentation. To avoid this problem, we propose a graph model initialized by a fully convolutional network (FCN) named Graph-FCN for image semantic segmentation. Firstly, the image grid data is extended to graph structure data by a convolutional network, which transforms the semantic segmentation problem into a graph node classification problem. Then we apply graph convolutional network to solve this graph node classification problem. As far as we know, it is the first time that we apply the graph convolutional network in image semantic segmentation. Our method achieves competitive performance in mean intersection over union (mIOU) on the VOC dataset(about 1.34% improvement), compared to the original FCN model.