 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSRS: Training Multimodal Speech Recognition Models from Scratch with Sparse Mask Optimization
Paper and Code
Jun 25, 2024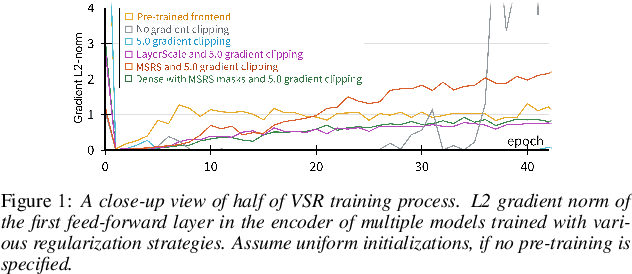
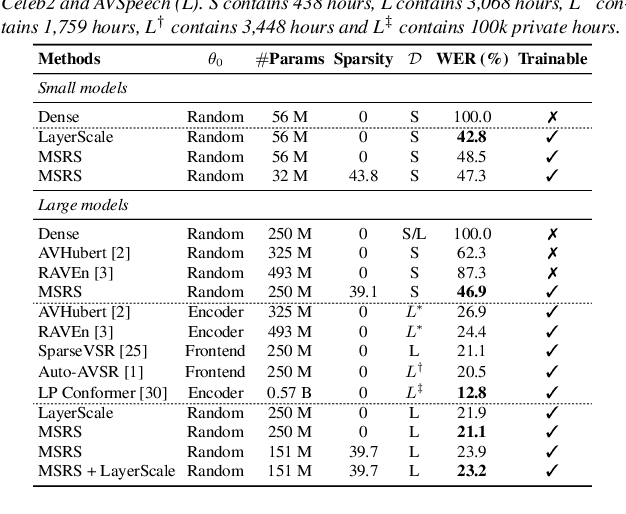
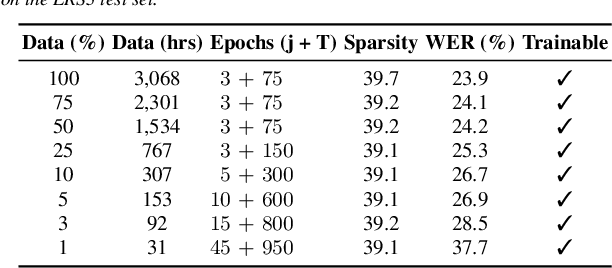
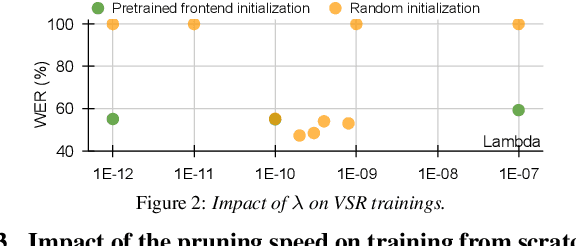
Pre-trained models have been a foundational approach in speech recognition, albeit with associated additional costs. In this study, we propose a regularization technique that facilitates the training of visual and audio-visual speech recognition models (VSR and AVSR) from scratch. This approach, abbreviated as \textbf{MSRS} (Multimodal Speech Recognition from Scratch), introduces a sparse regularization that rapidly learns sparse structures within the dense model at the very beginning of training, which receives healthier gradient flow than the dense equivalent. Once the sparse mask stabilizes, our method allows transitioning to a dense model or keeping a sparse model by updating non-zero values. MSRS achieves competitive results in VSR and AVSR with 21.1% and 0.9% WER on the LRS3 benchmark, while reducing training time by at least 2x. We explore other sparse approaches and show that only MSRS enables training from scratch by implicitly masking the weights affected by vanishing gradients.