 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive high-precision sound source localization at low frequencies based on convolutional neural network
Sep 30, 2024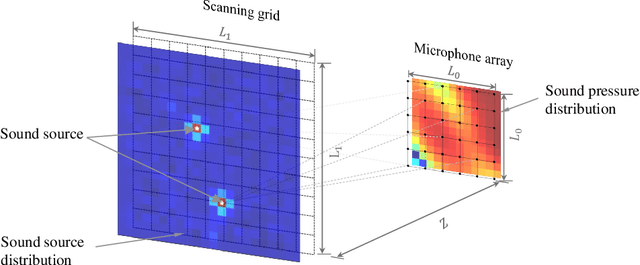


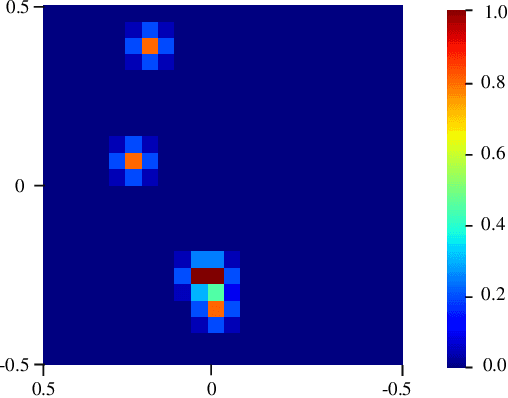
Sound source localization (SSL) technology plays a crucial role in various application areas such as fault diagnosis, speech separation, and vibration noise reduction. Although beamforming algorithms are widely used in SSL, their resolution at low frequencies is limited. In recent years, deep learning-based SSL methods have significantly improved their accuracy by employing large microphone arrays and training case specific neural networks, however, this could lead to narrow applicability. To address these issues, this paper proposes a convolutional neural network-based method for high-precision SSL, which is adaptive in the lower frequency range under 1kHz with varying numbers of sound sources and microphone array-to-scanning grid distances. It takes the pressure distribution on a relatively small microphone array as input to the neural network, and employs customized training labels and loss function to train the model. Prediction accuracy, adaptability and robustness of the trained model under certain signal-to-noise ratio (SNR) are evaluated using randomly generated test datasets, and compared with classical beamforming algorithms, CLEAN-SC and DAMAS. Results of both planar and spatial sound source distributions show that the proposed neural network model significantly improves low-frequency localization accuracy, demonstrating its effectiveness and potential in SSL.
Integrating Object-aware and Interaction-aware Knowledge for Weakly Supervised Scene Graph Generation
Aug 03, 2022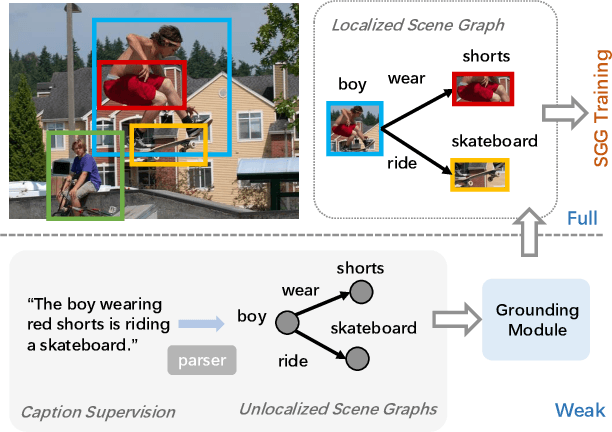

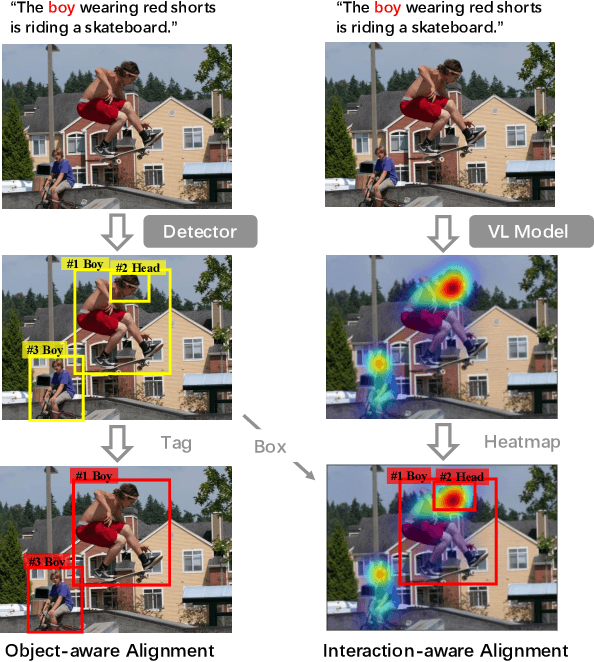
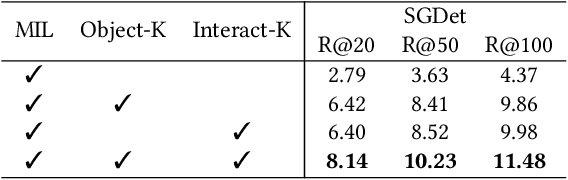
Recently, increasing efforts have been focused on Weakly Supervised Scene Graph Generation (WSSGG). The mainstream solution for WSSGG typically follows the same pipeline: they first align text entities in the weak image-level supervisions (e.g., unlocalized relation triplets or captions) with image regions, and then train SGG models in a fully-supervised manner with aligned instance-level "pseudo" labels. However, we argue that most existing WSSGG works only focus on object-consistency, which means the grounded regions should have the same object category label as text entities. While they neglect another basic requirement for an ideal alignment: interaction-consistency, which means the grounded region pairs should have the same interactions (i.e., visual relations) as text entity pairs. Hence, in this paper, we propose to enhance a simple grounding module with both object-aware and interaction-aware knowledge to acquire more reliable pseudo labels. To better leverage these two types of knowledge, we regard them as two teachers and fuse their generated targets to guide the training process of our grounding module. Specifically, we design two different strategies to adaptively assign weights to different teachers by assessing their reliability on each training sample. Extensive experiments have demonstrated that our method consistently improves WSSGG performance on various kinds of weak supervision.
Explicit Image Caption Editing
Jul 20, 2022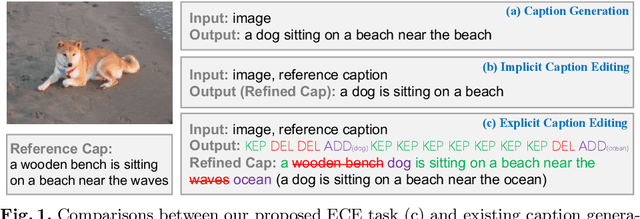
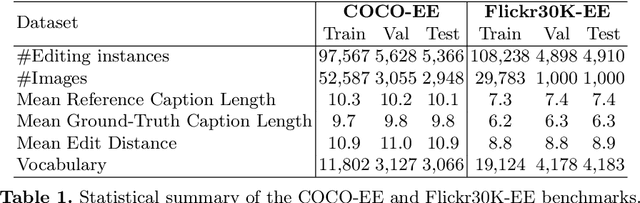

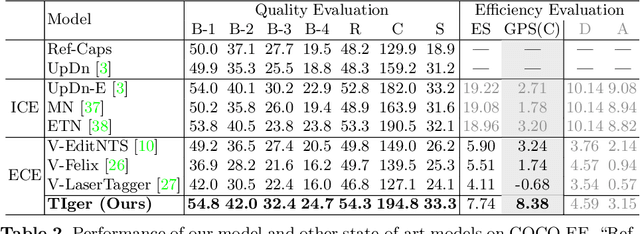
Given an image and a reference caption, the image caption editing task aims to correct the misalignment errors and generate a refined caption. However, all existing caption editing works are implicit models, ie, they directly produce the refined captions without explicit connections to the reference captions. In this paper, we introduce a new task: Explicit Caption Editing (ECE). ECE models explicitly generate a sequence of edit operations, and this edit operation sequence can translate the reference caption into a refined one. Compared to the implicit editing, ECE has multiple advantages: 1) Explainable: it can trace the whole editing path. 2) Editing Efficient: it only needs to modify a few words. 3) Human-like: it resembles the way that humans perform caption editing, and tries to keep original sentence structures. To solve this new task, we propose the first ECE model: TIger. TIger is a non-autoregressive transformer-based model, consisting of three modules: Tagger_del, Tagger_add, and Inserter. Specifically, Tagger_del decides whether each word should be preserved or not, Tagger_add decides where to add new words, and Inserter predicts the specific word for adding. To further facilitate ECE research, we propose two new ECE benchmarks by re-organizing two existing datasets, dubbed COCO-EE and Flickr30K-EE, respectively. Extensive ablations on both two benchmarks have demonstrated the effectiveness of TIger.
VL-NMS: Breaking Proposal Bottlenecks in Two-Stage Visual-Language Matching
May 12, 2021

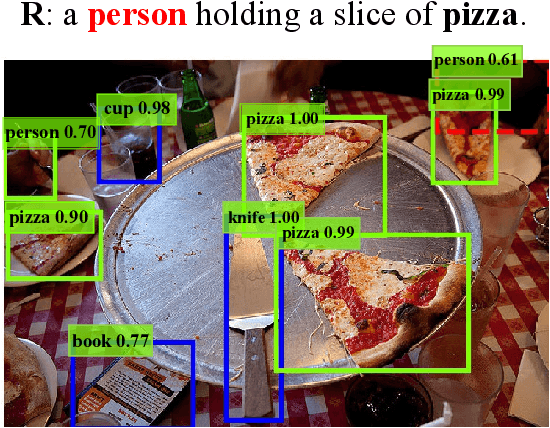
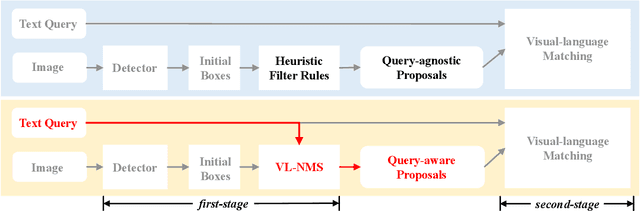
The prevailing framework for matching multimodal inputs is based on a two-stage process: 1) detecting proposals with an object detector and 2) matching text queries with proposals. Existing two-stage solutions mostly focus on the matching step. In this paper, we argue that these methods overlook an obvious \emph{mismatch} between the roles of proposals in the two stages: they generate proposals solely based on the detection confidence (i.e., query-agnostic), hoping that the proposals contain all instances mentioned in the text query (i.e., query-aware). Due to this mismatch, chances are that proposals relevant to the text query are suppressed during the filtering process, which in turn bounds the matching performance. To this end, we propose VL-NMS, which is the first method to yield query-aware proposals at the first stage. VL-NMS regards all mentioned instances as critical objects, and introduces a lightweight module to predict a score for aligning each proposal with a critical object. These scores can guide the NMS operation to filter out proposals irrelevant to the text query, increasing the recall of critical objects, resulting in a significantly improved matching performance. Since VL-NMS is agnostic to the matching step, it can be easily integrated into any state-of-the-art two-stage matching methods. We validate the effectiveness of VL-NMS on two multimodal matching tasks, namely referring expression grounding and image-text matching. Extensive ablation studies on several baselines and benchmarks consistently demonstrate the superiority of VL-NMS.
Ref-NMS: Breaking Proposal Bottlenecks in Two-Stage Referring Expression Grounding
Sep 03, 2020

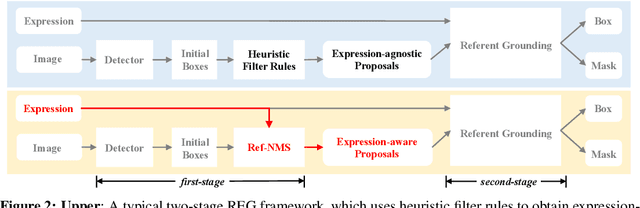

The prevailing framework for solving referring expression grounding is based on a two-stage process: 1) detecting proposals with an object detector and 2) grounding the referent to one of the proposals. Existing two-stage solutions mostly focus on the grounding step, which aims to align the expressions with the proposals. In this paper, we argue that these methods overlook an obvious mismatch between the roles of proposals in the two stages: they generate proposals solely based on the detection confidence (i.e., expression-agnostic), hoping that the proposals contain all right instances in the expression (i.e., expression-aware). Due to this mismatch, current two-stage methods suffer from a severe performance drop between detected and ground-truth proposals. To this end, we propose Ref-NMS, which is the first method to yield expression-aware proposals at the first stage. Ref-NMS regards all nouns in the expression as critical objects, and introduces a lightweight module to predict a score for aligning each box with a critical object. These scores can guide the NMSoperation to filter out the boxes irrelevant to the expression, increasing the recall of critical objects, resulting in a significantly improved grounding performance. Since Ref-NMS is agnostic to the grounding step, it can be easily integrated into any state-of-the-art two-stage method. Extensive ablation studies on several backbones, benchmarks, and tasks consistently demonstrate the superiority of Ref-NMS.
A Distributionally Robust Area Under Curve Maximization Model
Feb 18, 2020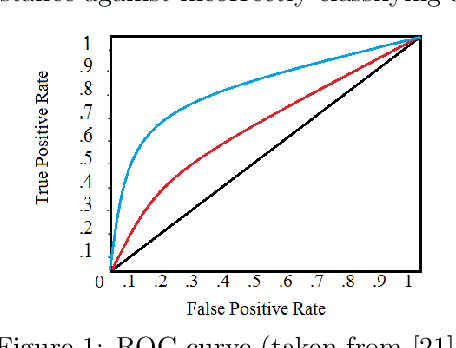
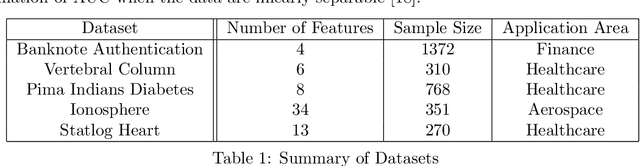
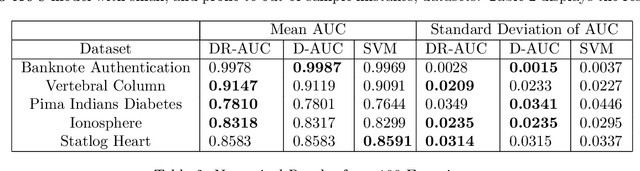
Area under ROC curve (AUC) is a widely used performance measure for classification models. We propose a new distributionally robust AUC maximization model (DR-AUC) that relies on the Kantorovich metric and approximates the AUC with the hinge loss function. We use duality theory to reformulate the DR-AUC model as a tractable convex quadratic optimization problem. The numerical experiments show that the proposed DR-AUC model -- benchmarked with the standard deterministic AUC and the support vector machine models - improves the out-of-sample performance over the majority of the considered datasets. The results are particularly encouraging since our numerical experiments are conducted with training sets of small size which have been known to be conducive to low out-of-sample performance.