 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVL-NMS: Breaking Proposal Bottlenecks in Two-Stage Visual-Language Matching
Paper and Code


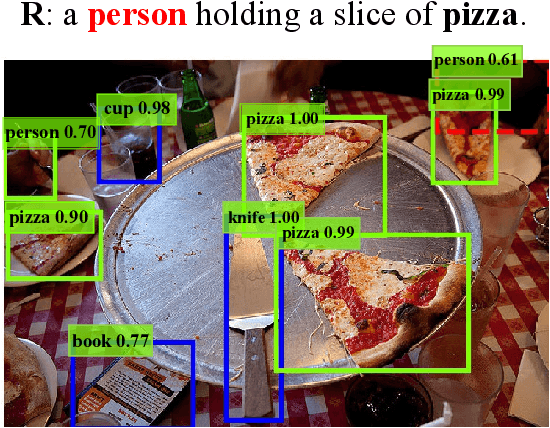
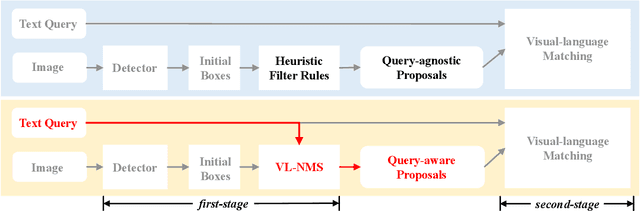
The prevailing framework for matching multimodal inputs is based on a two-stage process: 1) detecting proposals with an object detector and 2) matching text queries with proposals. Existing two-stage solutions mostly focus on the matching step. In this paper, we argue that these methods overlook an obvious \emph{mismatch} between the roles of proposals in the two stages: they generate proposals solely based on the detection confidence (i.e., query-agnostic), hoping that the proposals contain all instances mentioned in the text query (i.e., query-aware). Due to this mismatch, chances are that proposals relevant to the text query are suppressed during the filtering process, which in turn bounds the matching performance. To this end, we propose VL-NMS, which is the first method to yield query-aware proposals at the first stage. VL-NMS regards all mentioned instances as critical objects, and introduces a lightweight module to predict a score for aligning each proposal with a critical object. These scores can guide the NMS operation to filter out proposals irrelevant to the text query, increasing the recall of critical objects, resulting in a significantly improved matching performance. Since VL-NMS is agnostic to the matching step, it can be easily integrated into any state-of-the-art two-stage matching methods. We validate the effectiveness of VL-NMS on two multimodal matching tasks, namely referring expression grounding and image-text matching. Extensive ablation studies on several baselines and benchmarks consistently demonstrate the superiority of VL-NMS.