 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen3Guard Technical Report
Oct 16, 2025As large language models (LLMs) become more capable and widely used, ensuring the safety of their outputs is increasingly critical. Existing guardrail models, though useful in static evaluation settings, face two major limitations in real-world applications: (1) they typically output only binary "safe/unsafe" labels, which can be interpreted inconsistently across diverse safety policies, rendering them incapable of accommodating varying safety tolerances across domains; and (2) they require complete model outputs before performing safety checks, making them fundamentally incompatible with streaming LLM inference, thereby preventing timely intervention during generation and increasing exposure to harmful partial outputs. To address these challenges, we present Qwen3Guard, a series of multilingual safety guardrail models with two specialized variants: Generative Qwen3Guard, which casts safety classification as an instruction-following task to enable fine-grained tri-class judgments (safe, controversial, unsafe); and Stream Qwen3Guard, which introduces a token-level classification head for real-time safety monitoring during incremental text generation. Both variants are available in three sizes (0.6B, 4B, and 8B parameters) and support up to 119 languages and dialects, providing comprehensive, scalable, and low-latency safety moderation for global LLM deployments. Evaluated across English, Chinese, and multilingual benchmarks, Qwen3Guard achieves state-of-the-art performance in both prompt and response safety classification. All models are released under the Apache 2.0 license for public use.
Length-Controlled Margin-Based Preference Optimization without Reference Model
Feb 20, 2025Direct Preference Optimization (DPO) is a widely adopted offline algorithm for preference-based reinforcement learning from human feedback (RLHF), designed to improve training simplicity and stability by redefining reward functions. However, DPO is hindered by several limitations, including length bias, memory inefficiency, and probability degradation. To address these challenges, we propose Length-Controlled Margin-Based Preference Optimization (LMPO), a more efficient and robust alternative. LMPO introduces a uniform reference model as an upper bound for the DPO loss, enabling a more accurate approximation of the original optimization objective. Additionally, an average log-probability optimization strategy is employed to minimize discrepancies between training and inference phases. A key innovation of LMPO lies in its Length-Controlled Margin-Based loss function, integrated within the Bradley-Terry framework. This loss function regulates response length while simultaneously widening the margin between preferred and rejected outputs. By doing so, it mitigates probability degradation for both accepted and discarded responses, addressing a significant limitation of existing methods. We evaluate LMPO against state-of-the-art preference optimization techniques on two open-ended large language models, Mistral and LLaMA3, across six conditional benchmarks. Our experimental results demonstrate that LMPO effectively controls response length, reduces probability degradation, and outperforms existing approaches. The code is available at \url{https://github.com/gengxuli/LMPO}.
Qwen2.5 Technical Report
Dec 19, 2024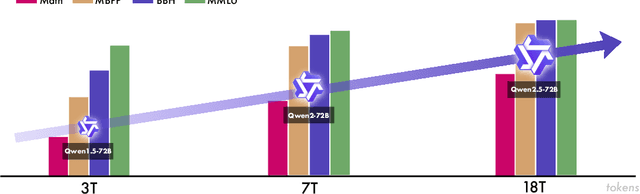

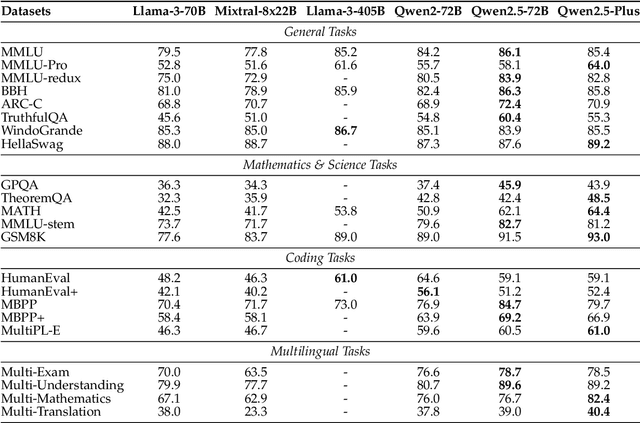
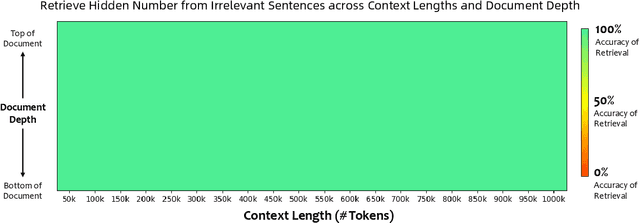
In this report, we introduce Qwen2.5, a comprehensive series of large language models (LLMs) designed to meet diverse needs. Compared to previous iterations, Qwen 2.5 has been significantly improved during both the pre-training and post-training stages. In terms of pre-training, we have scaled the high-quality pre-training datasets from the previous 7 trillion tokens to 18 trillion tokens. This provides a strong foundation for common sense, expert knowledge, and reasoning capabilities. In terms of post-training, we implement intricate supervised finetuning with over 1 million samples, as well as multistage reinforcement learning. Post-training techniques enhance human preference, and notably improve long text generation, structural data analysis, and instruction following. To handle diverse and varied use cases effectively, we present Qwen2.5 LLM series in rich sizes. Open-weight offerings include base and instruction-tuned models, with quantized versions available. In addition, for hosted solutions, the proprietary models currently include two mixture-of-experts (MoE) variants: Qwen2.5-Turbo and Qwen2.5-Plus, both available from Alibaba Cloud Model Studio. Qwen2.5 has demonstrated top-tier performance on a wide range of benchmarks evaluating language understanding, reasoning, mathematics, coding, human preference alignment, etc. Specifically, the open-weight flagship Qwen2.5-72B-Instruct outperforms a number of open and proprietary models and demonstrates competitive performance to the state-of-the-art open-weight model, Llama-3-405B-Instruct, which is around 5 times larger. Qwen2.5-Turbo and Qwen2.5-Plus offer superior cost-effectiveness while performing competitively against GPT-4o-mini and GPT-4o respectively. Additionally, as the foundation, Qwen2.5 models have been instrumental in training specialized models such as Qwen2.5-Math, Qwen2.5-Coder, QwQ, and multimodal models.
A Survey of RWKV
Dec 19, 2024The Receptance Weighted Key Value (RWKV) model offers a novel alternative to the Transformer architecture, merging the benefits of recurrent and attention-based systems. Unlike conventional Transformers, which depend heavily on self-attention, RWKV adeptly captures long-range dependencies with minimal computational demands. By utilizing a recurrent framework, RWKV addresses some computational inefficiencies found in Transformers, particularly in tasks with long sequences. RWKV has recently drawn considerable attention for its robust performance across multiple domains. Despite its growing popularity, no systematic review of the RWKV model exists. This paper seeks to fill this gap as the first comprehensive review of the RWKV architecture, its core principles, and its varied applications, such as natural language generation, natural language understanding, and computer vision. We assess how RWKV compares to traditional Transformer models, highlighting its capability to manage long sequences efficiently and lower computational costs. Furthermore, we explore the challenges RWKV encounters and propose potential directions for future research and advancement. We consistently maintain the related open-source materials at: https://github.com/MLGroupJLU/RWKV-Survey.
Rethinking Data Selection at Scale: Random Selection is Almost All You Need
Oct 12, 2024Supervised fine-tuning (SFT) is crucial for aligning Large Language Models (LLMs) with human instructions. The primary goal during SFT is to select a small yet representative subset of training data from the larger pool, such that fine-tuning with this subset achieves results comparable to or even exceeding those obtained using the entire dataset. However, most existing data selection techniques are designed for small-scale data pools, which fail to meet the demands of real-world SFT scenarios. In this paper, we replicated several self-scoring methods those that do not rely on external model assistance on two million scale datasets, and found that nearly all methods struggled to significantly outperform random selection when dealing with such large-scale data pools. Moreover, our comparisons suggest that, during SFT, diversity in data selection is more critical than simply focusing on high quality data. We also analyzed the limitations of several current approaches, explaining why they perform poorly on large-scale datasets and why they are unsuitable for such contexts. Finally, we found that filtering data by token length offers a stable and efficient method for improving results. This approach, particularly when training on long text data, proves highly beneficial for relatively weaker base models, such as Llama3.
Self-play with Execution Feedback: Improving Instruction-following Capabilities of Large Language Models
Jun 19, 2024



One core capability of large language models (LLMs) is to follow natural language instructions. However, the issue of automatically constructing high-quality training data to enhance the complex instruction-following abilities of LLMs without manual annotation remains unresolved. In this paper, we introduce AutoIF, the first scalable and reliable method for automatically generating instruction-following training data. AutoIF transforms the validation of instruction-following data quality into code verification, requiring LLMs to generate instructions, the corresponding code to check the correctness of the instruction responses, and unit test samples to verify the code's correctness. Then, execution feedback-based rejection sampling can generate data for Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) training. AutoIF achieves significant improvements across three training algorithms, SFT, Offline DPO, and Online DPO, when applied to the top open-source LLMs, Qwen2 and LLaMA3, in self-alignment and strong-to-weak distillation settings. Our code is publicly available at https://github.com/QwenLM/AutoIF.
Language Models can Evaluate Themselves via Probability Discrepancy
May 17, 2024In this paper, we initiate our discussion by demonstrating how Large Language Models (LLMs), when tasked with responding to queries, display a more even probability distribution in their answers if they are more adept, as opposed to their less skilled counterparts. Expanding on this foundational insight, we propose a new self-evaluation method ProbDiff for assessing the efficacy of various LLMs. This approach obviates the necessity for an additional evaluation model or the dependence on external, proprietary models like GPT-4 for judgment. It uniquely utilizes the LLMs being tested to compute the probability discrepancy between the initial response and its revised versions. A higher discrepancy for a given query between two LLMs indicates a relatively weaker capability. Our findings reveal that ProbDiff achieves results on par with those obtained from evaluations based on GPT-4, spanning a range of scenarios that include natural language generation (NLG) tasks such as translation, summarization, and our proposed Xiaohongshu blog writing task, and benchmarks for LLM evaluation like AlignBench, MT-Bench, and AlpacaEval, across LLMs of varying magnitudes.
FastClass: A Time-Efficient Approach to Weakly-Supervised Text Classification
Dec 15, 2022



Weakly-supervised text classification aims to train a classifier using only class descriptions and unlabeled data. Recent research shows that keyword-driven methods can achieve state-of-the-art performance on various tasks. However, these methods not only rely on carefully-crafted class descriptions to obtain class-specific keywords but also require substantial amount of unlabeled data and takes a long time to train. This paper proposes FastClass, an efficient weakly-supervised classification approach. It uses dense text representation to retrieve class-relevant documents from external unlabeled corpus and selects an optimal subset to train a classifier. Compared to keyword-driven methods, our approach is less reliant on initial class descriptions as it no longer needs to expand each class description into a set of class-specific keywords. Experiments on a wide range of classification tasks show that the proposed approach frequently outperforms keyword-driven models in terms of classification accuracy and often enjoys orders-of-magnitude faster training speed.
Using Prior Knowledge to Guide BERT's Attention in Semantic Textual Matching Tasks
Feb 22, 2021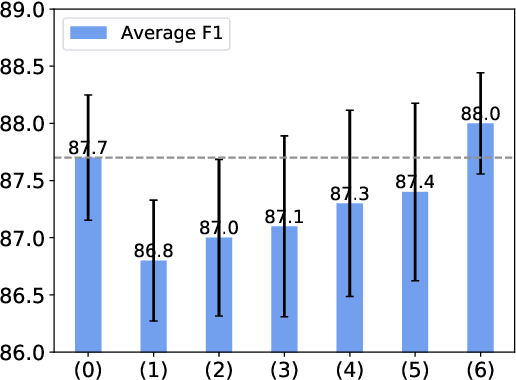



We study the problem of incorporating prior knowledge into a deep Transformer-based model,i.e.,Bidirectional Encoder Representations from Transformers (BERT), to enhance its performance on semantic textual matching tasks. By probing and analyzing what BERT has already known when solving this task, we obtain better understanding of what task-specific knowledge BERT needs the most and where it is most needed. The analysis further motivates us to take a different approach than most existing works. Instead of using prior knowledge to create a new training task for fine-tuning BERT, we directly inject knowledge into BERT's multi-head attention mechanism. This leads us to a simple yet effective approach that enjoys fast training stage as it saves the model from training on additional data or tasks other than the main task. Extensive experiments demonstrate that the proposed knowledge-enhanced BERT is able to consistently improve semantic textual matching performance over the original BERT model, and the performance benefit is most salient when training data is scarce.