 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Multimodal Models Actively Recognize Faulty Inputs? A Systematic Evaluation Framework of Their Input Scrutiny Ability
Aug 06, 2025
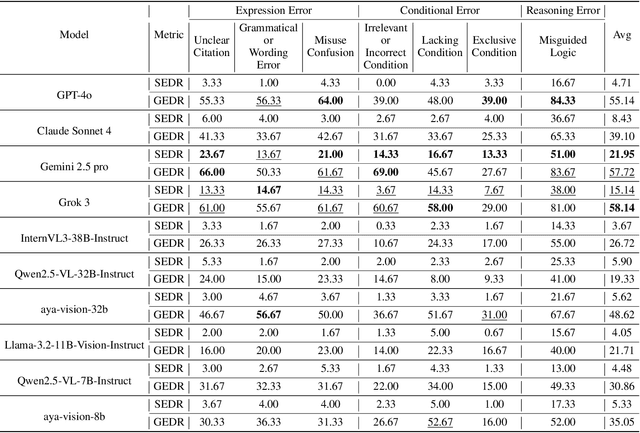
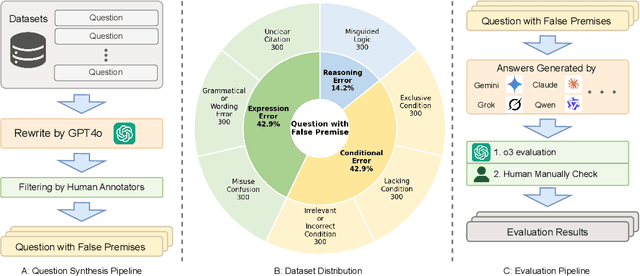
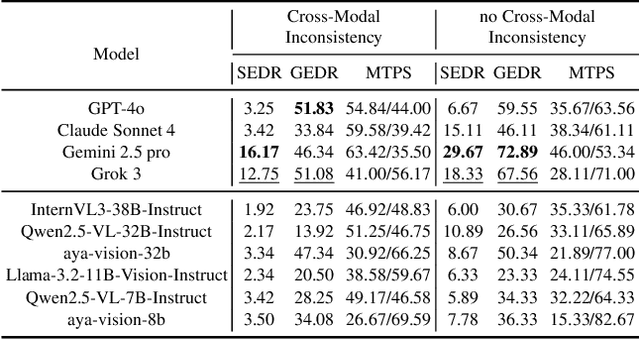
Large Multimodal Models (LMMs) have witnessed remarkable growth, showcasing formidable capabilities in handling intricate multimodal tasks with exceptional performance. Recent research has underscored the inclination of large language models to passively accept defective inputs, often resulting in futile reasoning on invalid prompts. However, the same critical question of whether LMMs can actively detect and scrutinize erroneous inputs still remains unexplored. To address this gap, we introduce the Input Scrutiny Ability Evaluation Framework (ISEval), which encompasses seven categories of flawed premises and three evaluation metrics. Our extensive evaluation of ten advanced LMMs has identified key findings. Most models struggle to actively detect flawed textual premises without guidance, which reflects a strong reliance on explicit prompts for premise error identification. Error type affects performance: models excel at identifying logical fallacies but struggle with surface-level linguistic errors and certain conditional flaws. Modality trust varies-Gemini 2.5 pro and Claude Sonnet 4 balance visual and textual info, while aya-vision-8b over-rely on text in conflicts. These insights underscore the urgent need to enhance LMMs' proactive verification of input validity and shed novel insights into mitigating the problem. The code is available at https://github.com/MLGroupJLU/LMM_ISEval.
Don't Take the Premise for Granted: Evaluating the Premise Critique Ability of Large Language Models
May 29, 2025Large language models (LLMs) have witnessed rapid advancements, demonstrating remarkable capabilities. However, a notable vulnerability persists: LLMs often uncritically accept flawed or contradictory premises, leading to inefficient reasoning and unreliable outputs. This emphasizes the significance of possessing the \textbf{Premise Critique Ability} for LLMs, defined as the capacity to proactively identify and articulate errors in input premises. Most existing studies assess LLMs' reasoning ability in ideal settings, largely ignoring their vulnerabilities when faced with flawed premises. Thus, we introduce the \textbf{Premise Critique Bench (PCBench)}, designed by incorporating four error types across three difficulty levels, paired with multi-faceted evaluation metrics. We conducted systematic evaluations of 15 representative LLMs. Our findings reveal: (1) Most models rely heavily on explicit prompts to detect errors, with limited autonomous critique; (2) Premise critique ability depends on question difficulty and error type, with direct contradictions being easier to detect than complex or procedural errors; (3) Reasoning ability does not consistently correlate with the premise critique ability; (4) Flawed premises trigger overthinking in reasoning models, markedly lengthening responses due to repeated attempts at resolving conflicts. These insights underscore the urgent need to enhance LLMs' proactive evaluation of input validity, positioning premise critique as a foundational capability for developing reliable, human-centric systems. The code is available at https://github.com/MLGroupJLU/Premise_Critique.
Asymmetric Co-Training for Source-Free Few-Shot Domain Adaptation
Feb 20, 2025


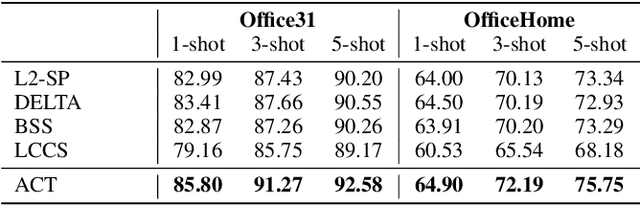
Source-free unsupervised domain adaptation (SFUDA) has gained significant attention as an alternative to traditional unsupervised domain adaptation (UDA), which relies on the constant availability of labeled source data. However, SFUDA approaches come with inherent limitations that are frequently overlooked. These challenges include performance degradation when the unlabeled target data fails to meet critical assumptions, such as having a closed-set label distribution identical to that of the source domain, or when sufficient unlabeled target data is unavailable-a common situation in real-world applications. To address these issues, we propose an asymmetric co-training (ACT) method specifically designed for the SFFSDA scenario. SFFSDA presents a more practical alternative to SFUDA, as gathering a few labeled target instances is more feasible than acquiring large volumes of unlabeled target data in many real-world contexts. Our ACT method begins by employing a weak-strong augmentation to enhance data diversity. Then we use a two-step optimization process to train the target model. In the first step, we optimize the label smoothing cross-entropy loss, the entropy of the class-conditional distribution, and the reverse-entropy loss to bolster the model's discriminative ability while mitigating overfitting. The second step focuses on reducing redundancy in the output space by minimizing classifier determinacy disparity. Extensive experiments across four benchmarks demonstrate the superiority of our ACT approach, which outperforms state-of-the-art SFUDA methods and transfer learning techniques. Our findings suggest that adapting a source pre-trained model using only a small amount of labeled target data offers a practical and dependable solution. The code is available at https://github.com/gengxuli/ACT.
Length-Controlled Margin-Based Preference Optimization without Reference Model
Feb 20, 2025Direct Preference Optimization (DPO) is a widely adopted offline algorithm for preference-based reinforcement learning from human feedback (RLHF), designed to improve training simplicity and stability by redefining reward functions. However, DPO is hindered by several limitations, including length bias, memory inefficiency, and probability degradation. To address these challenges, we propose Length-Controlled Margin-Based Preference Optimization (LMPO), a more efficient and robust alternative. LMPO introduces a uniform reference model as an upper bound for the DPO loss, enabling a more accurate approximation of the original optimization objective. Additionally, an average log-probability optimization strategy is employed to minimize discrepancies between training and inference phases. A key innovation of LMPO lies in its Length-Controlled Margin-Based loss function, integrated within the Bradley-Terry framework. This loss function regulates response length while simultaneously widening the margin between preferred and rejected outputs. By doing so, it mitigates probability degradation for both accepted and discarded responses, addressing a significant limitation of existing methods. We evaluate LMPO against state-of-the-art preference optimization techniques on two open-ended large language models, Mistral and LLaMA3, across six conditional benchmarks. Our experimental results demonstrate that LMPO effectively controls response length, reduces probability degradation, and outperforms existing approaches. The code is available at \url{https://github.com/gengxuli/LMPO}.