 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Prior Knowledge to Guide BERT's Attention in Semantic Textual Matching Tasks
Paper and Code
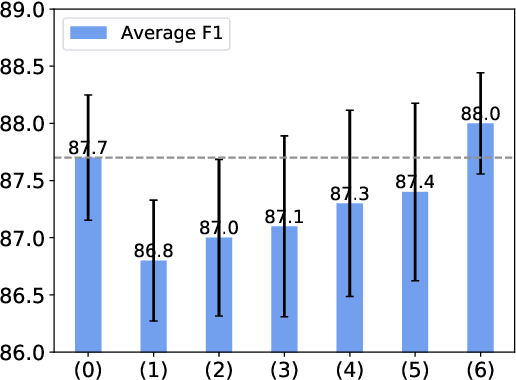



We study the problem of incorporating prior knowledge into a deep Transformer-based model,i.e.,Bidirectional Encoder Representations from Transformers (BERT), to enhance its performance on semantic textual matching tasks. By probing and analyzing what BERT has already known when solving this task, we obtain better understanding of what task-specific knowledge BERT needs the most and where it is most needed. The analysis further motivates us to take a different approach than most existing works. Instead of using prior knowledge to create a new training task for fine-tuning BERT, we directly inject knowledge into BERT's multi-head attention mechanism. This leads us to a simple yet effective approach that enjoys fast training stage as it saves the model from training on additional data or tasks other than the main task. Extensive experiments demonstrate that the proposed knowledge-enhanced BERT is able to consistently improve semantic textual matching performance over the original BERT model, and the performance benefit is most salient when training data is scarce.