 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometrical portrait of Multipath error propagation in GNSS Direct Position Estimation
Jul 24, 2025Direct Position Estimation (DPE) is a method that directly estimate position, velocity, and time (PVT) information from cross ambiguity function (CAF) of the GNSS signals, significantly enhancing receiver robustness in urban environments. However, there is still a lack of theoretical characterization on multipath errors in the context of DPE theory. Geometric observations highlight the unique characteristics of DPE errors stemming from multipath and thermal noise as estimation bias and variance respectively. Expanding upon the theoretical framework of DPE noise variance through geometric analysis, this paper focuses on a geometric representation of multipath errors by quantifying the deviations in CAF and PVT solutions caused by off-centering bias relative to the azimuth and elevation angles. A satellite circular multipath bias (SCMB) model is introduced, amalgamating CAF and PVT errors from multiple satellite channels. The boundaries for maximum or minimum PVT bias are established through discussions encompassing various multipath conditions. The correctness of the multipath geometrical portrait is confirmed through both Monte Carlo simulations and urban canyon tests. The findings indicate that the maximum PVT bias depends on the largest multipath errors observed across various satellite channels. Additionally, the PVT bias increases with satellite elevation angles, influenced by the CAF multipath bias projection. This serves as a reference for selecting DPE satellites from a geometric standpoint, underscoring the importance of choosing a balanced combination of high and low elevation angles to achieve an optimal satellite geometry configuration.
Pre-training vs. Fine-tuning: A Reproducibility Study on Dense Retrieval Knowledge Acquisition
May 12, 2025Dense retrievers utilize pre-trained backbone language models (e.g., BERT, LLaMA) that are fine-tuned via contrastive learning to perform the task of encoding text into sense representations that can be then compared via a shallow similarity operation, e.g. inner product. Recent research has questioned the role of fine-tuning vs. that of pre-training within dense retrievers, specifically arguing that retrieval knowledge is primarily gained during pre-training, meaning knowledge not acquired during pre-training cannot be sub-sequentially acquired via fine-tuning. We revisit this idea here as the claim was only studied in the context of a BERT-based encoder using DPR as representative dense retriever. We extend the previous analysis by testing other representation approaches (comparing the use of CLS tokens with that of mean pooling), backbone architectures (encoder-only BERT vs. decoder-only LLaMA), and additional datasets (MSMARCO in addition to Natural Questions). Our study confirms that in DPR tuning, pre-trained knowledge underpins retrieval performance, with fine-tuning primarily adjusting neuron activation rather than reorganizing knowledge. However, this pattern does not hold universally, such as in mean-pooled (Contriever) and decoder-based (LLaMA) models. We ensure full reproducibility and make our implementation publicly available at https://github.com/ielab/DenseRetriever-Knowledge-Acquisition.
FineMath: A Fine-Grained Mathematical Evaluation Benchmark for Chinese Large Language Models
Mar 12, 2024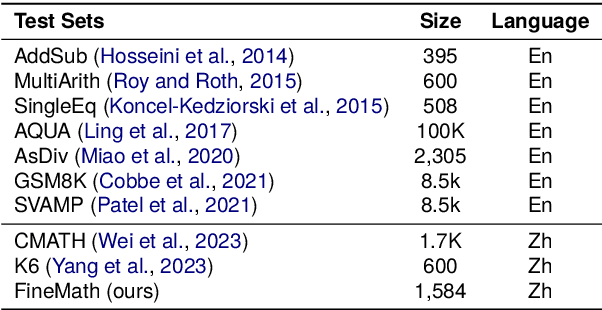
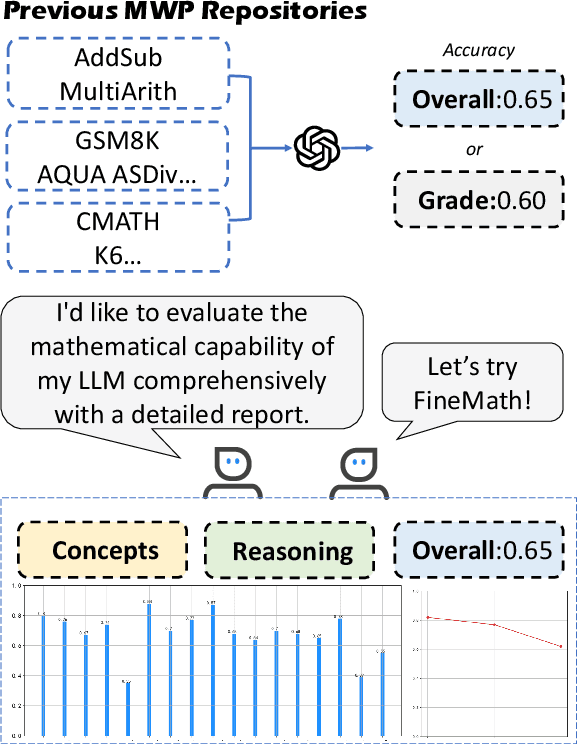


To thoroughly assess the mathematical reasoning abilities of Large Language Models (LLMs), we need to carefully curate evaluation datasets covering diverse mathematical concepts and mathematical problems at different difficulty levels. In pursuit of this objective, we propose FineMath in this paper, a fine-grained mathematical evaluation benchmark dataset for assessing Chinese LLMs. FineMath is created to cover the major key mathematical concepts taught in elementary school math, which are further divided into 17 categories of math word problems, enabling in-depth analysis of mathematical reasoning abilities of LLMs. All the 17 categories of math word problems are manually annotated with their difficulty levels according to the number of reasoning steps required to solve these problems. We conduct extensive experiments on a wide range of LLMs on FineMath and find that there is still considerable room for improvements in terms of mathematical reasoning capability of Chinese LLMs. We also carry out an in-depth analysis on the evaluation process and methods that have been overlooked previously. These two factors significantly influence the model results and our understanding of their mathematical reasoning capabilities. The dataset will be publicly available soon.
Associative Learning Mechanism for Drug-Target Interaction Prediction
Jun 01, 2022

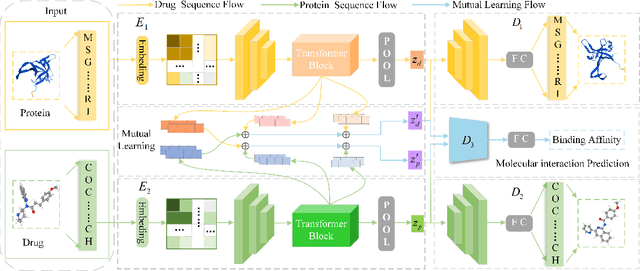
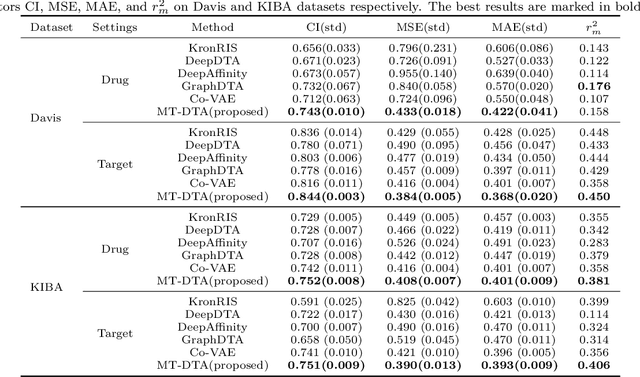
As a necessary process in drug development, finding a drug compound that can selectively bind to a specific protein is highly challenging and costly. Drug-target affinity (DTA), which represents the strength of drug-target interaction (DTI), has played an important role in the DTI prediction task over the past decade. Although deep learning has been applied to DTA-related research, existing solutions ignore fundamental correlations between molecular substructures in molecular representation learning of drug compound molecules/protein targets. Moreover, traditional methods lack the interpretability of the DTA prediction process. This results in missing feature information of intermolecular interactions, thereby affecting prediction performance. Therefore, this paper proposes a DTA prediction method with interactive learning and an autoencoder mechanism. The proposed model enhances the corresponding ability to capture the feature information of a single molecular sequence by the drug/protein molecular representation learning module and supplements the information interaction between molecular sequence pairs by the interactive information learning module. The DTA value prediction module fuses the drug-target pair interaction information to output the predicted value of DTA. Additionally, this paper theoretically proves that the proposed method maximizes evidence lower bound (ELBO) for the joint distribution of the DTA prediction model, which enhances the consistency of the probability distribution between the actual value and the predicted value. The experimental results confirm mutual transformer-drug target affinity (MT-DTA) achieves better performance than other comparative methods.
New Closed-form Joint Localization and Synchronization using Sequential TOAs in a Multi-agent System
Jan 30, 2021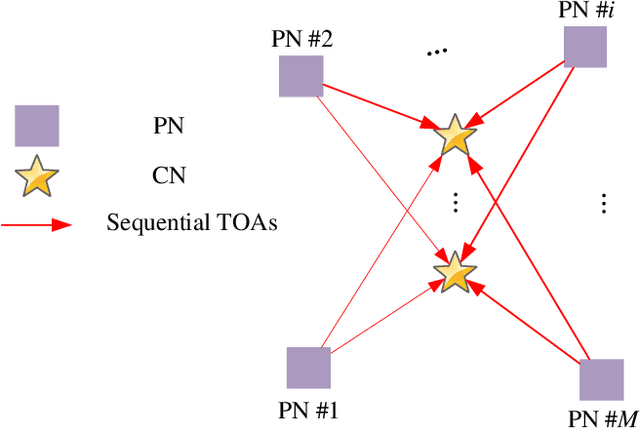
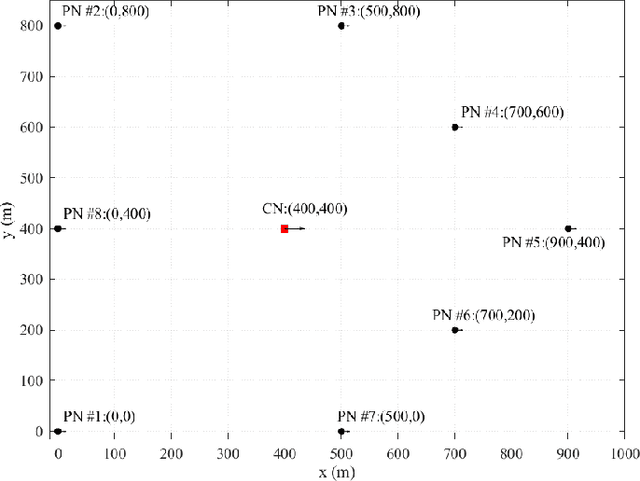
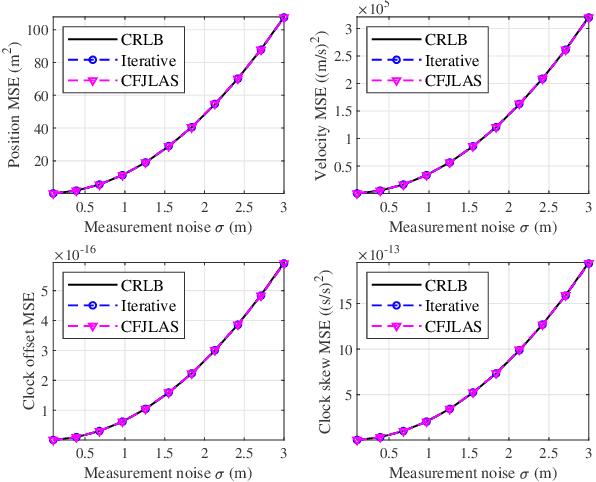
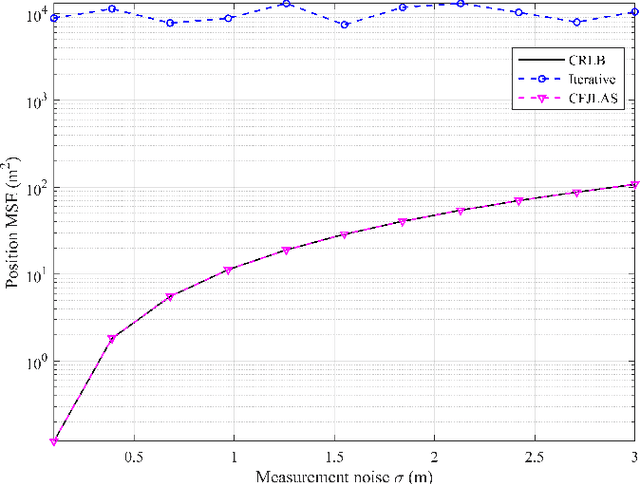
In a multi-agent system (MAS) comprised of parent nodes (PNs) and child nodes (CNs), a relative spatiotemporal coordinate is established by the PNs with known positions. It is an essential technique for the moving CNs to resolve the joint localization and synchronization (JLAS) problem in the MAS. Existing methods using sequential time-of-arrival (TOA) measurements from the PNs' broadcast signals either require a good initial guess or have high computational complexity. In this paper, we propose a new closed-form JLAS approach, namely CFJLAS, which achieves optimal solution without initialization, and has low computational complexity. We first linearize the relation between the estimated parameter and the sequential TOA measurement by squaring and differencing the TOA measurement equations. By devising two intermediate variables, we are able to simplify the problem to finding the solution of a quadratic equation set. Finally, we apply a weighted least squares (WLS) step using the residuals of all the measurements to optimize the estimation. We derive the Cramer-Rao lower bound (CRLB), analyze the estimation error, and show that the estimation accuracy of the CFJLAS reaches CRLB under small noise condition. The complexity of the CFJLAS is studied and compared with the iterative method. Simulations in the 2D scene verify that the estimation accuracy of the new CFJLAS method in position, velocity, clock offset, and clock skew all reaches CRLB. Compared with the conventional iterative method, which requires a good initial guess to converge to the correct estimation and has growing complexity with more iterations, the proposed new CFJLAS method does not require initialization, always obtains the optimal solution and has constant low computational complexity.