 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoinformatics-Guided Machine Learning for Power Plant Classification
Feb 03, 2025



This paper proposes an approach in the area of Knowledge-Guided Machine Learning (KGML) via a novel integrated framework comprising CNN (Convolutional Neural Networks) and ViT (Vision Transformers) along with GIS (Geographic Information Systems) to enhance power plant classification in the context of energy management. Knowledge from geoinformatics derived through Spatial Masks (SM) in GIS is infused into an architecture of CNN and ViT, in this proposed KGML approach. It is found to provide much better performance compared to the baseline of CNN and ViT only in the classification of multiple types of power plants from real satellite imagery, hence emphasizing the vital role of the geoinformatics-guided approach. This work makes a contribution to the main theme of KGML that can be beneficial in many AI systems today. It makes broader impacts on AI in Smart Cities, and Environmental Computing.
Power Plant Detection for Energy Estimation using GIS with Remote Sensing, CNN & Vision Transformers
Dec 06, 2024In this research, we propose a hybrid model for power plant detection to assist energy estimation applications, by pipelining GIS (Geographical Information Systems) having Remote Sensing capabilities with CNN (Convolutional Neural Networks) and ViT (Vision Transformers). Our proposed approach enables real-time analysis with multiple data types on a common map via the GIS, entails feature-extraction abilities due to the CNN, and captures long-range dependencies through the ViT. This hybrid approach is found to enhance classification, thus helping in the monitoring and operational management of power plants; hence assisting energy estimation and sustainable energy planning in the future. It exemplifies adequate deployment of machine learning methods in conjunction with domain-specific approaches to enhance performance.
Robo-CSK-Organizer: Commonsense Knowledge to Organize Detected Objects for Multipurpose Robots
Sep 27, 2024This paper presents a system called Robo-CSK-Organizer that infuses commonsense knowledge from a classical knowledge based to enhance the context recognition capabilities of robots so as to facilitate the organization of detected objects by classifying them in a task-relevant manner. It is particularly useful in multipurpose robotics. Unlike systems relying solely on deep learning tools such as ChatGPT, the Robo-CSK-Organizer system stands out in multiple avenues as follows. It resolves ambiguities well, and maintains consistency in object placement. Moreover, it adapts to diverse task-based classifications. Furthermore, it contributes to explainable AI, hence helping to improve trust and human-robot collaboration. Controlled experiments performed in our work, simulating domestic robotics settings, make Robo-CSK-Organizer demonstrate superior performance while placing objects in contextually relevant locations. This work highlights the capacity of an AI-based system to conduct commonsense-guided decision-making in robotics closer to the thresholds of human cognition. Hence, Robo-CSK-Organizer makes positive impacts on AI and robotics.
Opinion Mining on Offshore Wind Energy for Environmental Engineering
Sep 22, 2024In this paper, we conduct sentiment analysis on social media data to study mass opinion about offshore wind energy. We adapt three machine learning models, namely, TextBlob, VADER, and SentiWordNet because different functions are provided by each model. TextBlob provides subjectivity analysis as well as polarity classification. VADER offers cumulative sentiment scores. SentiWordNet considers sentiments with reference to context and performs classification accordingly. Techniques in NLP are harnessed to gather meaning from the textual data in social media. Data visualization tools are suitably deployed to display the overall results. This work is much in line with citizen science and smart governance via involvement of mass opinion to guide decision support. It exemplifies the role of Machine Learning and NLP here.
Optical Character Recognition and Transcription of Berber Signs from Images in a Low-Resource Language Amazigh
Mar 21, 2023


The Berber, or Amazigh language family is a low-resource North African vernacular language spoken by the indigenous Berber ethnic group. It has its own unique alphabet called Tifinagh used across Berber communities in Morocco, Algeria, and others. The Afroasiatic language Berber is spoken by 14 million people, yet lacks adequate representation in education, research, web applications etc. For instance, there is no option of translation to or from Amazigh / Berber on Google Translate, which hosts over 100 languages today. Consequently, we do not find specialized educational apps, L2 (2nd language learner) acquisition, automated language translation, and remote-access facilities enabled in Berber. Motivated by this background, we propose a supervised approach called DaToBS for Detection and Transcription of Berber Signs. The DaToBS approach entails the automatic recognition and transcription of Tifinagh characters from signs in photographs of natural environments. This is achieved by self-creating a corpus of 1862 pre-processed character images; curating the corpus with human-guided annotation; and feeding it into an OCR model via the deployment of CNN for deep learning based on computer vision models. We deploy computer vision modeling (rather than language models) because there are pictorial symbols in this alphabet, this deployment being a novel aspect of our work. The DaToBS experimentation and analyses yield over 92 percent accuracy in our research. To the best of our knowledge, ours is among the first few works in the automated transcription of Berber signs from roadside images with deep learning, yielding high accuracy. This can pave the way for developing pedagogical applications in the Berber language, thereby addressing an important goal of outreach to underrepresented communities via AI in education.
Hey Dona! Can you help me with student course registration?
Mar 21, 2023In this paper, we present a demo of an intelligent personal agent called Hey Dona (or just Dona) with virtual voice assistance in student course registration. It is a deployed project in the theme of AI for education. In this digital age with a myriad of smart devices, users often delegate tasks to agents. While pointing and clicking supersedes the erstwhile command-typing, modern devices allow users to speak commands for agents to execute tasks, enhancing speed and convenience. In line with this progress, Dona is an intelligent agent catering to student needs by automated, voice-operated course registration, spanning a multitude of accents, entailing task planning optimization, with some language translation as needed. Dona accepts voice input by microphone (Bluetooth, wired microphone), converts human voice to computer understandable language, performs query processing as per user commands, connects with the Web to search for answers, models task dependencies, imbibes quality control, and conveys output by speaking to users as well as displaying text, thus enabling human-AI interaction by speech cum text. It is meant to work seamlessly on desktops, smartphones etc. and in indoor as well as outdoor settings. To the best of our knowledge, Dona is among the first of its kind as an intelligent personal agent for voice assistance in student course registration. Due to its ubiquitous access for educational needs, Dona directly impacts AI for education. It makes a broader impact on smart city characteristics of smart living and smart people due to its contributions to providing benefits for new ways of living and assisting 21st century education, respectively.
Linking Alternative Fuel Vehicles Adoption with Socioeconomic Status and Air Quality Index
Mar 15, 2023
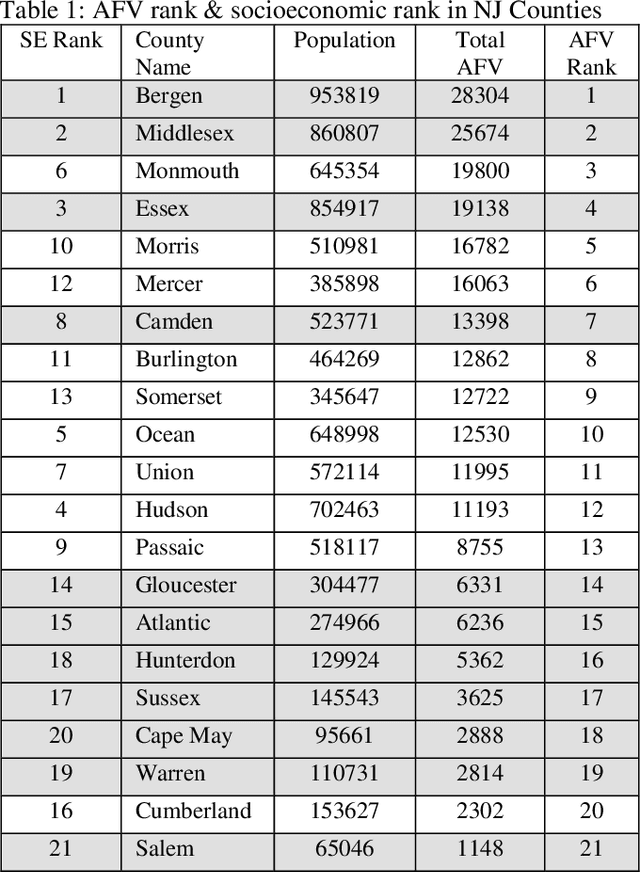
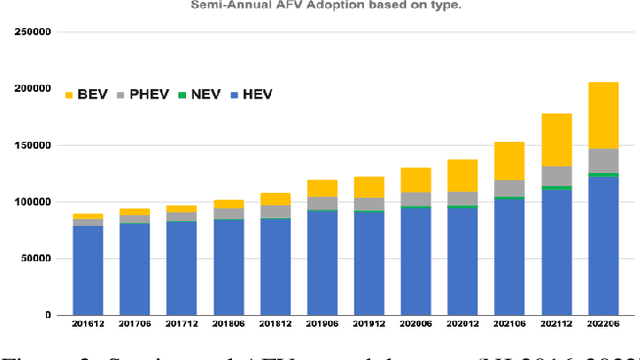
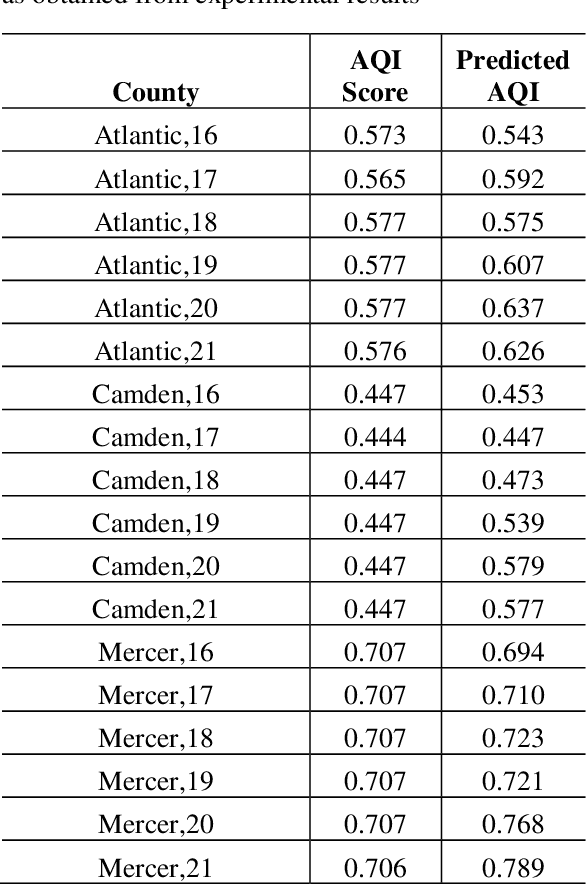
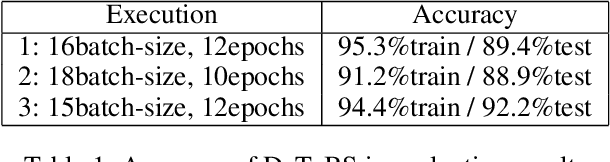
This is a study on the potential widespread usage of alternative fuel vehicles, linking them with the socio-economic status of the respective consumers as well as the impact on the resulting air quality index. Research in this area aims to leverage machine learning techniques in order to promote appropriate policies for the proliferation of alternative fuel vehicles such as electric vehicles with due justice to different population groups. Pearson correlation coefficient is deployed in the modeling the relationships between socio-economic data, air quality index and data on alternative fuel vehicles. Linear regression is used to conduct predictive modeling on air quality index as per the adoption of alternative fuel vehicles, based on socio-economic factors. This work exemplifies artificial intelligence for social good.
Machine Learning Approaches in Agile Manufacturing with Recycled Materials for Sustainability
Mar 15, 2023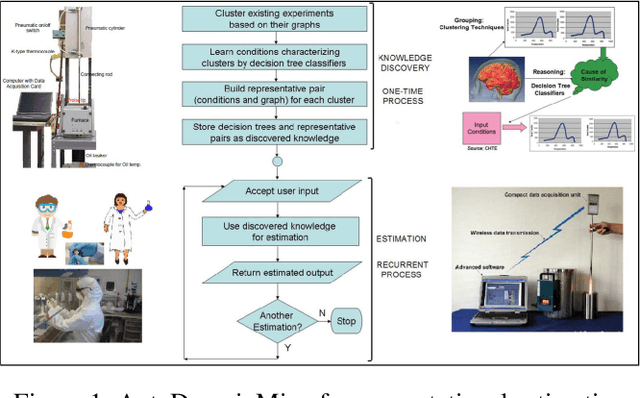

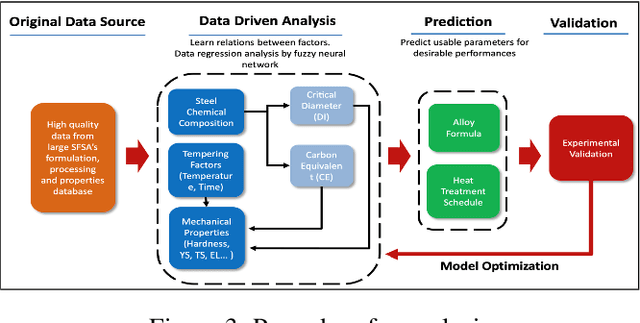
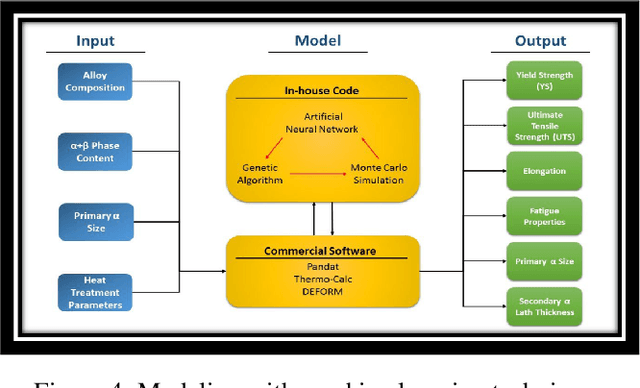
It is important to develop sustainable processes in materials science and manufacturing that are environmentally friendly. AI can play a significant role in decision support here as evident from our earlier research leading to tools developed using our proposed machine learning based approaches. Such tools served the purpose of computational estimation and expert systems. This research addresses environmental sustainability in materials science via decision support in agile manufacturing using recycled and reclaimed materials. It is a safe and responsible way to turn a specific waste stream to value-added products. We propose to use data-driven methods in AI by applying machine learning models for predictive analysis to guide decision support in manufacturing. This includes harnessing artificial neural networks to study parameters affecting heat treatment of materials and impacts on their properties; deep learning via advances such as convolutional neural networks to explore grain size detection; and other classifiers such as Random Forests to analyze phrase fraction detection. Results with all these methods seem promising to embark on further work, e.g. ANN yields accuracy around 90\% for predicting micro-structure development as per quench tempering, a heat treatment process. Future work entails several challenges: investigating various computer vision models (VGG, ResNet etc.) to find optimal accuracy, efficiency and robustness adequate for sustainable processes; creating domain-specific tools using machine learning for decision support in agile manufacturing; and assessing impacts on sustainability with metrics incorporating the appropriate use of recycled materials as well as the effectiveness of developed products. Our work makes impacts on green technology for smart manufacturing, and is motivated by related work in the highly interesting realm of AI for materials science.
Mining GIS Data to Predict Urban Sprawl
Mar 21, 2021



This paper addresses the interesting problem of processing and analyzing data in geographic information systems (GIS) to achieve a clear perspective on urban sprawl. The term urban sprawl refers to overgrowth and expansion of low-density areas with issues such as car dependency and segregation between residential versus commercial use. Sprawl has impacts on the environment and public health. In our work, spatiotemporal features related to real GIS data on urban sprawl such as population growth and demographics are mined to discover knowledge for decision support. We adapt data mining algorithms, Apriori for association rule mining and J4.8 for decision tree classification to geospatial analysis, deploying the ArcGIS tool for mapping. Knowledge discovered by mining this spatiotemporal data is used to implement a prototype spatial decision support system (SDSS). This SDSS predicts whether urban sprawl is likely to occur. Further, it estimates the values of pertinent variables to understand how the variables impact each other. The SDSS can help decision-makers identify problems and create solutions for avoiding future sprawl occurrence and conducting urban planning where sprawl already occurs, thus aiding sustainable development. This work falls in the broad realm of geospatial intelligence and sets the stage for designing a large scale SDSS to process big data in complex environments, which constitutes part of our future work.
Common Sense Knowledge, Ontology and Text Mining for Implicit Requirements
Mar 21, 2021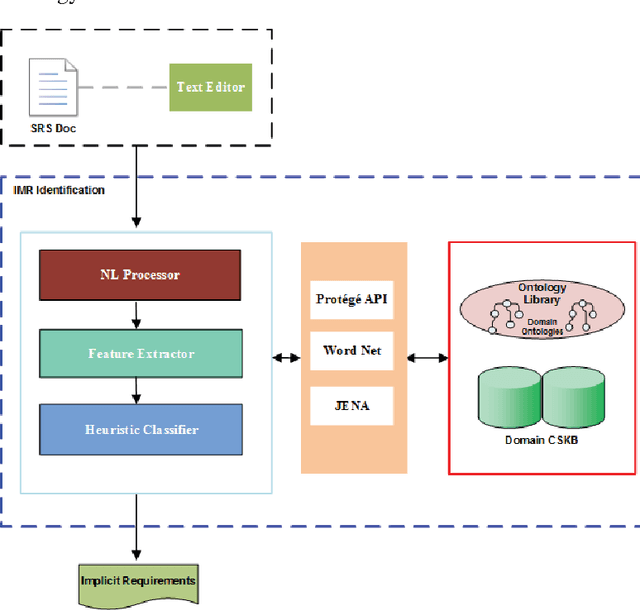



The ability of a system to meet its requirements is a strong determinant of success. Thus effective requirements specification is crucial. Explicit Requirements are well-defined needs for a system to execute. IMplicit Requirements (IMRs) are assumed needs that a system is expected to fulfill though not elicited during requirements gathering. Studies have shown that a major factor in the failure of software systems is the presence of unhandled IMRs. Since relevance of IMRs is important for efficient system functionality, there are methods developed to aid the identification and management of IMRs. In this paper, we emphasize that Common Sense Knowledge, in the field of Knowledge Representation in AI, would be useful to automatically identify and manage IMRs. This paper is aimed at identifying the sources of IMRs and also proposing an automated support tool for managing IMRs within an organizational context. Since this is found to be a present gap in practice, our work makes a contribution here. We propose a novel approach for identifying and managing IMRs based on combining three core technologies: common sense knowledge, text mining and ontology. We claim that discovery and handling of unknown and non-elicited requirements would reduce risks and costs in software development.