 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommon Sense Knowledge, Ontology and Text Mining for Implicit Requirements
Mar 21, 2021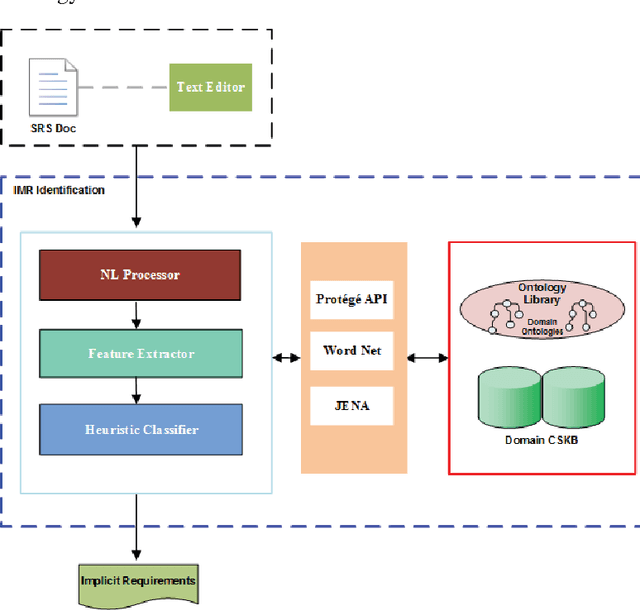



The ability of a system to meet its requirements is a strong determinant of success. Thus effective requirements specification is crucial. Explicit Requirements are well-defined needs for a system to execute. IMplicit Requirements (IMRs) are assumed needs that a system is expected to fulfill though not elicited during requirements gathering. Studies have shown that a major factor in the failure of software systems is the presence of unhandled IMRs. Since relevance of IMRs is important for efficient system functionality, there are methods developed to aid the identification and management of IMRs. In this paper, we emphasize that Common Sense Knowledge, in the field of Knowledge Representation in AI, would be useful to automatically identify and manage IMRs. This paper is aimed at identifying the sources of IMRs and also proposing an automated support tool for managing IMRs within an organizational context. Since this is found to be a present gap in practice, our work makes a contribution here. We propose a novel approach for identifying and managing IMRs based on combining three core technologies: common sense knowledge, text mining and ontology. We claim that discovery and handling of unknown and non-elicited requirements would reduce risks and costs in software development.
A Framework for Pre-processing of Social Media Feeds based on Integrated Local Knowledge Base
Jun 29, 2020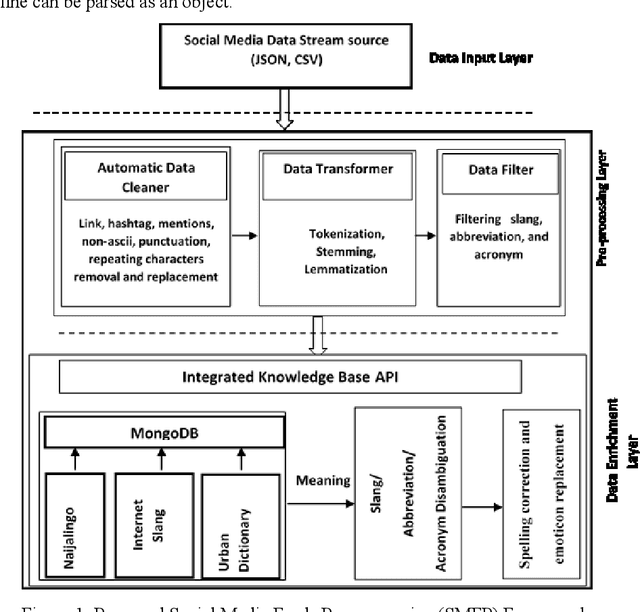
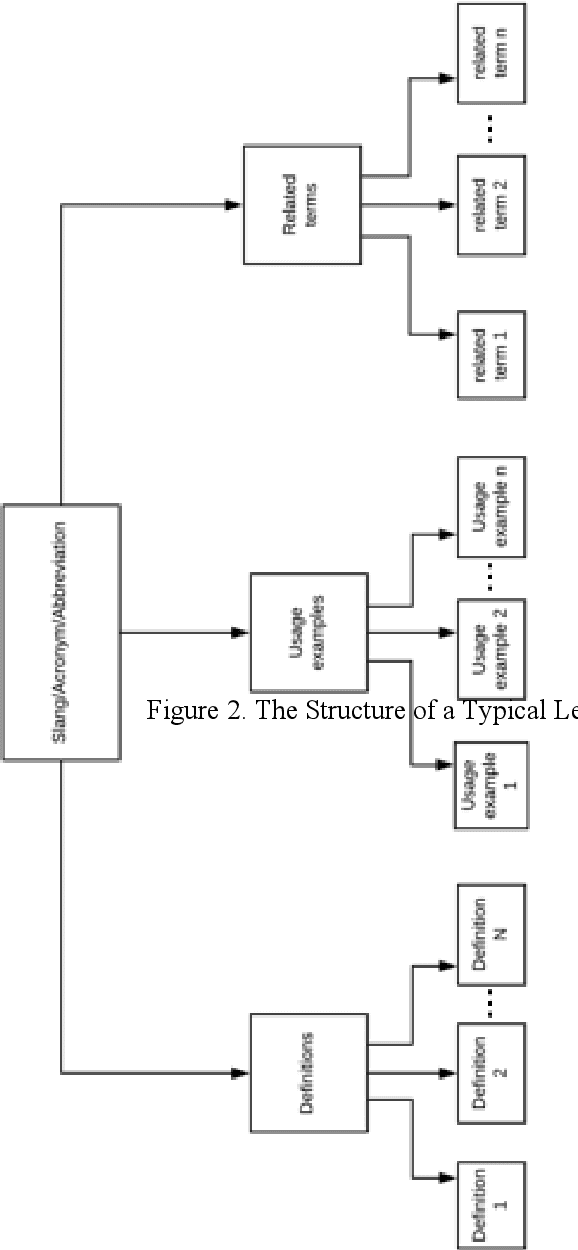

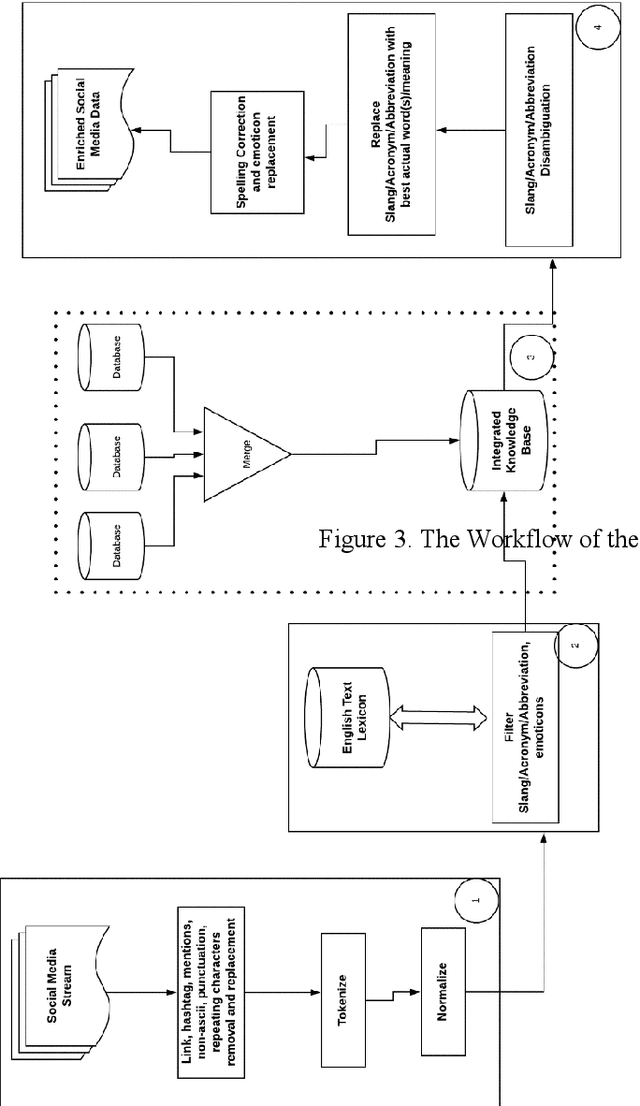
Most of the previous studies on the semantic analysis of social media feeds have not considered the issue of ambiguity that is associated with slangs, abbreviations, and acronyms that are embedded in social media posts. These noisy terms have implicit meanings and form part of the rich semantic context that must be analysed to gain complete insights from social media feeds. This paper proposes an improved framework for pre-processing of social media feeds for better performance. To do this, the use of an integrated knowledge base (ikb) which comprises a local knowledge source (Naijalingo), urban dictionary and internet slang was combined with the adapted Lesk algorithm to facilitate semantic analysis of social media feeds. Experimental results showed that the proposed approach performed better than existing methods when it was tested on three machine learning models, which are support vector machines, multilayer perceptron, and convolutional neural networks. The framework had an accuracy of 94.07% on a standardized dataset, and 99.78% on localised dataset when used to extract sentiments from tweets. The improved performance on the localised dataset reveals the advantage of integrating the use of local knowledge sources into the process of analysing social media feeds particularly in interpreting slangs/acronyms/abbreviations that have contextually rooted meanings.