 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAE: Target-aware enhancer for nighttime UAV tracking
May 28, 2026Severe image degradation under low-light nighttime conditions constitutes a core bottleneck preventing all-day applications for UAV-based single object tracking. Existing image enhancement methods often struggle to distinguish between target and background regions, which can easily lead to amplified background noise or compromise target features. To overcome this limitation, we propose TAE, a target-aware low-light enhancement framework tailored for nighttime object tracking. Guided explicitly by weak supervisory signals from tracking bounding boxes, the framework performs region-aware enhancement to ensure operations focus on the target area. It further adopts an adaptive RGB multi-curve fusion mechanism to achieve refined modeling and adaptive adjustment across different regions. To facilitate research in this domain, we also contribute DarkSOT, a new benchmark for nighttime UAV tracking, comprising 268 sequences across 9 target categories. Experimental results on the DarkSOT and UAVDark135 demonstrate that TAE significantly improves tracking performance in low-light nighttime scenarios, exhibiting strong robustness and generalization. The DarkSOT dataset is available at https://github.com/Fu0511/DarkSOT-Dataset.
Lighten CARAFE: Dynamic Lightweight Upsampling with Guided Reassemble Kernels
Oct 29, 2024As a fundamental operation in modern machine vision models, feature upsampling has been widely used and investigated in the literatures. An ideal upsampling operation should be lightweight, with low computational complexity. That is, it can not only improve the overall performance but also not affect the model complexity. Content-aware Reassembly of Features (CARAFE) is a well-designed learnable operation to achieve feature upsampling. Albeit encouraging performance achieved, this method requires generating large-scale kernels, which brings a mass of extra redundant parameters, and inherently has limited scalability. To this end, we propose a lightweight upsampling operation, termed Dynamic Lightweight Upsampling (DLU) in this paper. In particular, it first constructs a small-scale source kernel space, and then samples the large-scale kernels from the kernel space by introducing learnable guidance offsets, hence avoiding introducing a large collection of trainable parameters in upsampling. Experiments on several mainstream vision tasks show that our DLU achieves comparable and even better performance to the original CARAFE, but with much lower complexity, e.g., DLU requires 91% fewer parameters and at least 63% fewer FLOPs (Floating Point Operations) than CARAFE in the case of 16x upsampling, but outperforms the CARAFE by 0.3% mAP in object detection. Code is available at https://github.com/Fu0511/Dynamic-Lightweight-Upsampling.
A Dual Neighborhood Hypergraph Neural Network for Change Detection in VHR Remote Sensing Images
Feb 27, 2022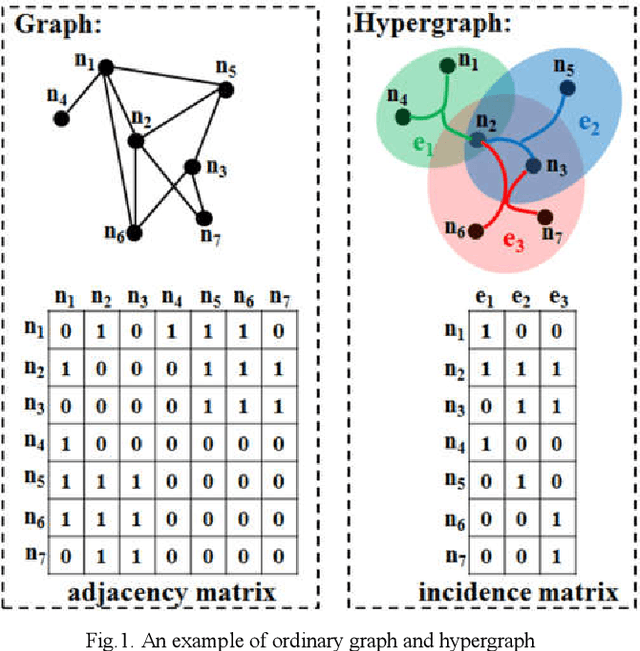
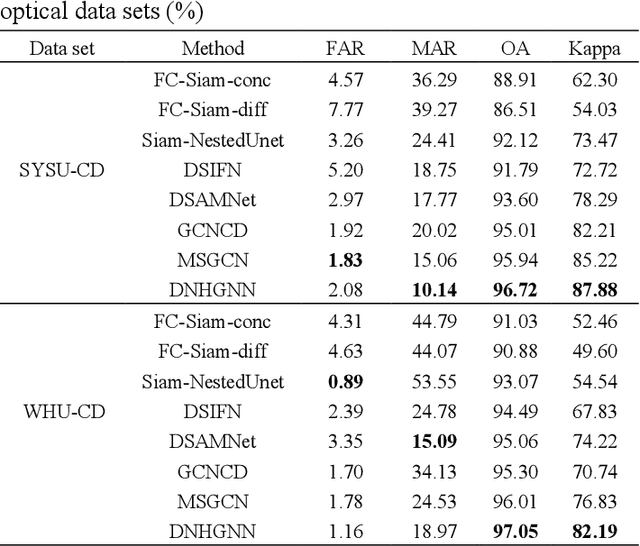
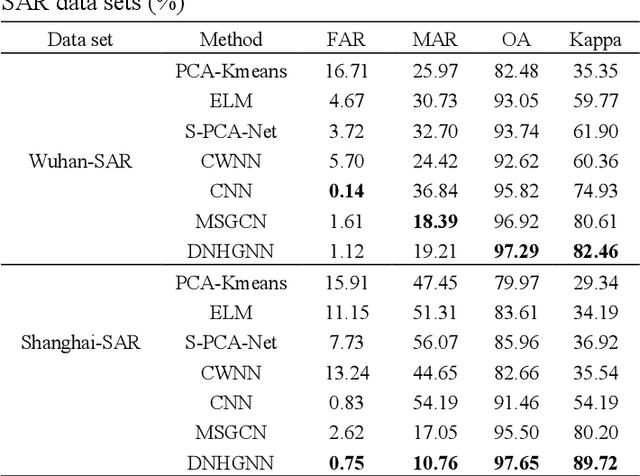
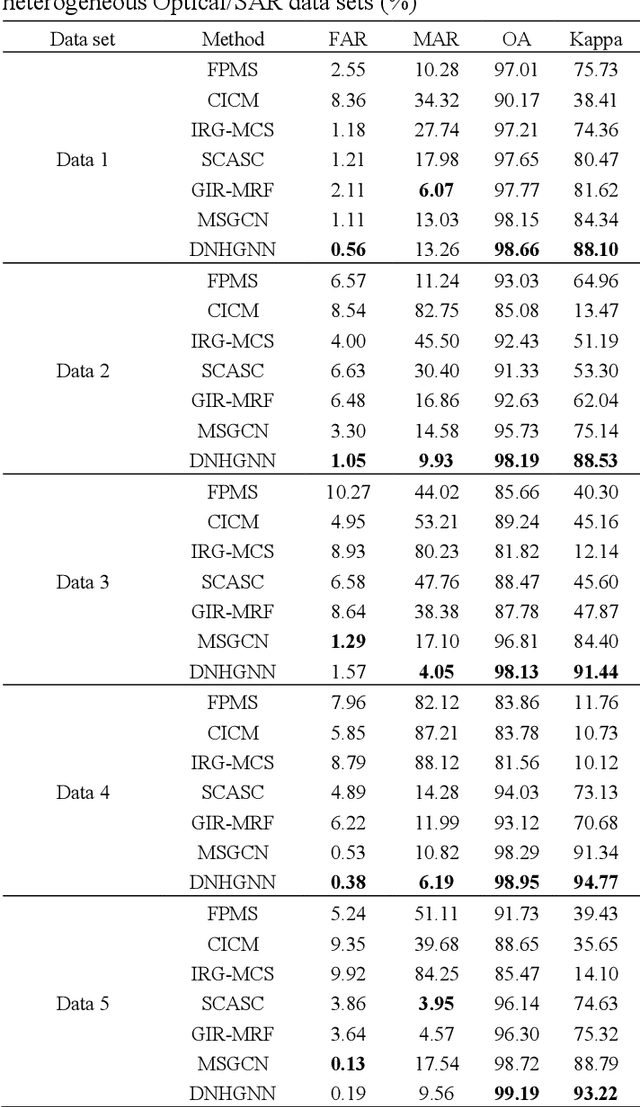
The very high spatial resolution (VHR) remote sensing images have been an extremely valuable source for monitoring changes occurred on the earth surface. However, precisely detecting relevant changes in VHR images still remains a challenge, due to the complexity of the relationships among ground objects. To address this limitation, a dual neighborhood hypergraph neural network is proposed in this article, which combines the multiscale superpixel segmentation and hypergraph convolution to model and exploit the complex relationships. First, the bi-temporal image pairs are segmented under two scales and fed to a pre-trained U-net to obtain node features by treating each object under the fine scale as a node. The dual neighborhood is then defined using the father-child and adjacent relationships of the segmented objects to construct the hypergraph, which permits models to represent the higher-order structured information far more complex than just pairwise relationships. The hypergraph convolutions are conducted on the constructed hypergraph to propagate the label information from a small amount of labeled nodes to the other unlabeled ones by the node-edge-node transform. Moreover, to alleviate the problem of imbalanced sample, the focal loss function is adopted to train the hypergraph neural network. The experimental results on optical, SAR and heterogeneous optical/SAR data sets demonstrate that the proposed method comprises better effectiveness and robustness compared to many state-of-the-art methods.
An Improved Discriminative Optimization for 3D Rigid Point Cloud Registration
Apr 18, 2021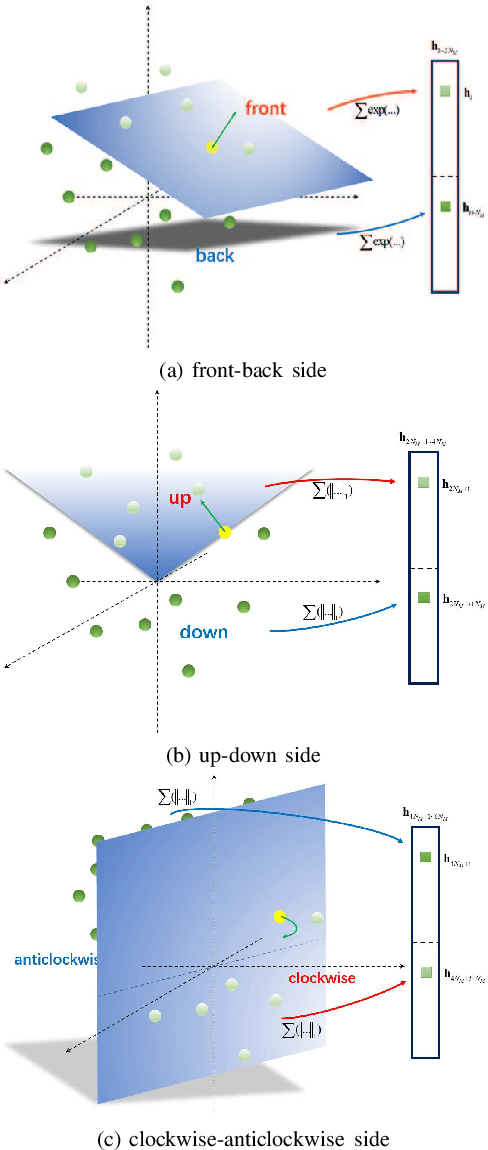
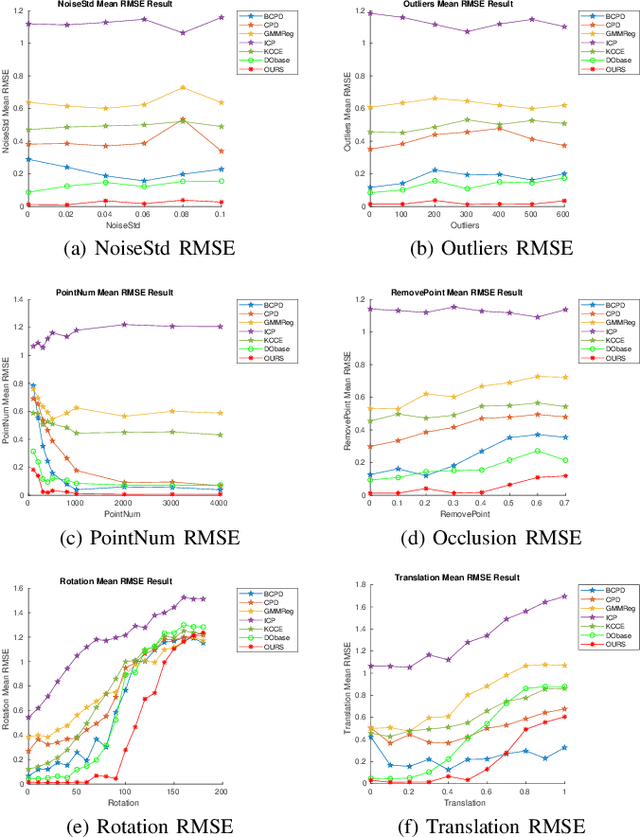
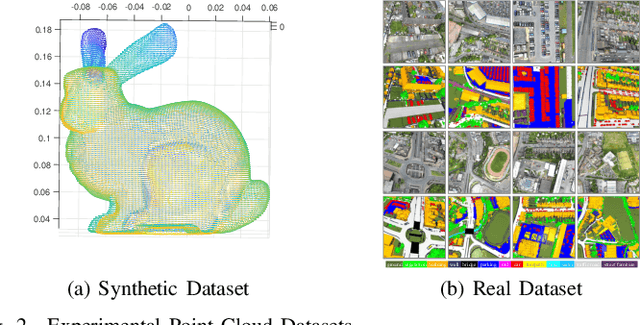
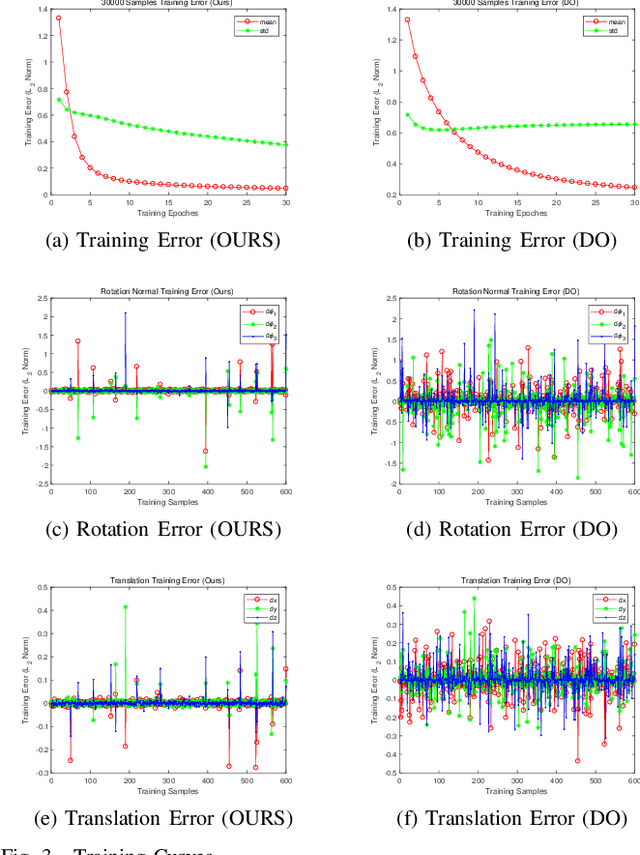
The Discriminative Optimization (DO) algorithm has been proved much successful in 3D point cloud registration. In the original DO, the feature (descriptor) of two point cloud was defined as a histogram, and the element of histogram indicates the weights of scene points in "front" or "back" side of a model point. In this paper, we extended the histogram which indicate the sides from "front-back" to "front-back", "up-down", and "clockwise-anticlockwise". In addition, we reweighted the extended histogram according to the model points' distribution. We evaluated the proposed Improved DO on the Stanford Bunny and Oxford SensatUrban dataset, and compared it with six classical State-Of-The-Art point cloud registration algorithms. The experimental result demonstrates our algorithm achieves comparable performance in point registration accuracy and root-mean-sqart-error.
Axiom-based Grad-CAM: Towards Accurate Visualization and Explanation of CNNs
Aug 19, 2020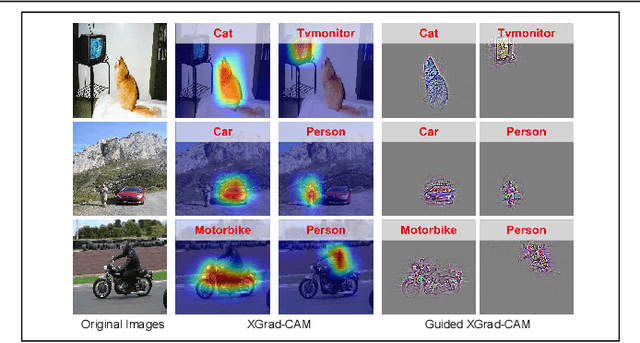
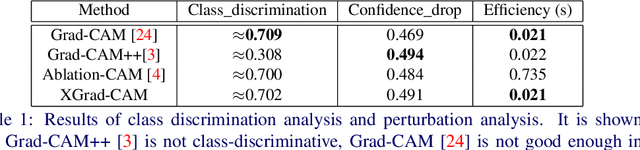
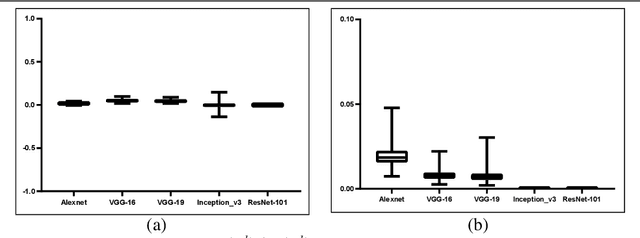
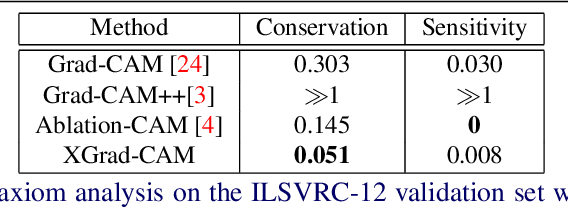
To have a better understanding and usage of Convolution Neural Networks (CNNs), the visualization and interpretation of CNNs has attracted increasing attention in recent years. In particular, several Class Activation Mapping (CAM) methods have been proposed to discover the connection between CNN's decision and image regions. In spite of the reasonable visualization, lack of clear and sufficient theoretical support is the main limitation of these methods. In this paper, we introduce two axioms -- Conservation and Sensitivity -- to the visualization paradigm of the CAM methods. Meanwhile, a dedicated Axiom-based Grad-CAM (XGrad-CAM) is proposed to satisfy these axioms as much as possible. Experiments demonstrate that XGrad-CAM is an enhanced version of Grad-CAM in terms of conservation and sensitivity. It is able to achieve better visualization performance than Grad-CAM, while also be class-discriminative and easy-to-implement compared with Grad-CAM++ and Ablation-CAM. The code is available at https://github.com/Fu0511/XGrad-CAM.