 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLighten CARAFE: Dynamic Lightweight Upsampling with Guided Reassemble Kernels
Oct 29, 2024As a fundamental operation in modern machine vision models, feature upsampling has been widely used and investigated in the literatures. An ideal upsampling operation should be lightweight, with low computational complexity. That is, it can not only improve the overall performance but also not affect the model complexity. Content-aware Reassembly of Features (CARAFE) is a well-designed learnable operation to achieve feature upsampling. Albeit encouraging performance achieved, this method requires generating large-scale kernels, which brings a mass of extra redundant parameters, and inherently has limited scalability. To this end, we propose a lightweight upsampling operation, termed Dynamic Lightweight Upsampling (DLU) in this paper. In particular, it first constructs a small-scale source kernel space, and then samples the large-scale kernels from the kernel space by introducing learnable guidance offsets, hence avoiding introducing a large collection of trainable parameters in upsampling. Experiments on several mainstream vision tasks show that our DLU achieves comparable and even better performance to the original CARAFE, but with much lower complexity, e.g., DLU requires 91% fewer parameters and at least 63% fewer FLOPs (Floating Point Operations) than CARAFE in the case of 16x upsampling, but outperforms the CARAFE by 0.3% mAP in object detection. Code is available at https://github.com/Fu0511/Dynamic-Lightweight-Upsampling.
Axiom-based Grad-CAM: Towards Accurate Visualization and Explanation of CNNs
Aug 19, 2020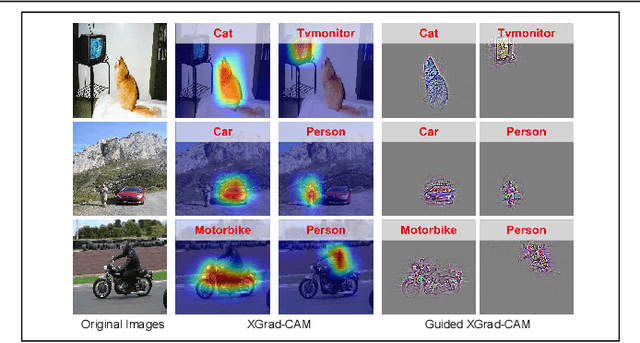
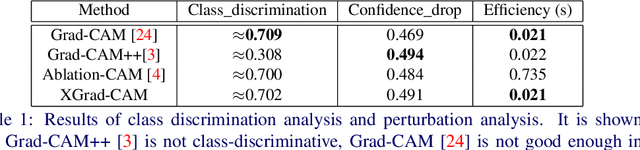
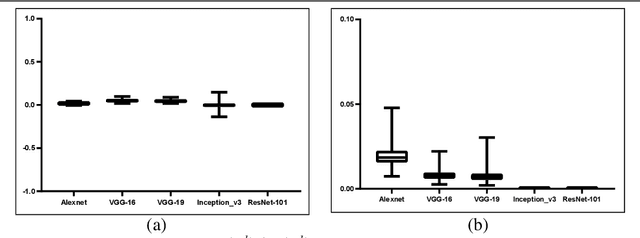
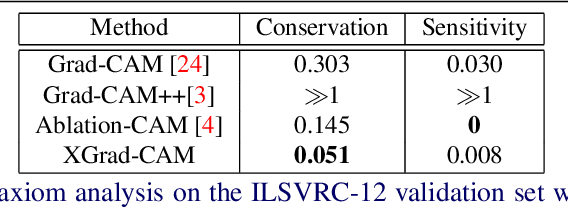
To have a better understanding and usage of Convolution Neural Networks (CNNs), the visualization and interpretation of CNNs has attracted increasing attention in recent years. In particular, several Class Activation Mapping (CAM) methods have been proposed to discover the connection between CNN's decision and image regions. In spite of the reasonable visualization, lack of clear and sufficient theoretical support is the main limitation of these methods. In this paper, we introduce two axioms -- Conservation and Sensitivity -- to the visualization paradigm of the CAM methods. Meanwhile, a dedicated Axiom-based Grad-CAM (XGrad-CAM) is proposed to satisfy these axioms as much as possible. Experiments demonstrate that XGrad-CAM is an enhanced version of Grad-CAM in terms of conservation and sensitivity. It is able to achieve better visualization performance than Grad-CAM, while also be class-discriminative and easy-to-implement compared with Grad-CAM++ and Ablation-CAM. The code is available at https://github.com/Fu0511/XGrad-CAM.