 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Image Editing Detection in the Era of Generative AI Revolution
Paper and Code
Nov 29, 2023
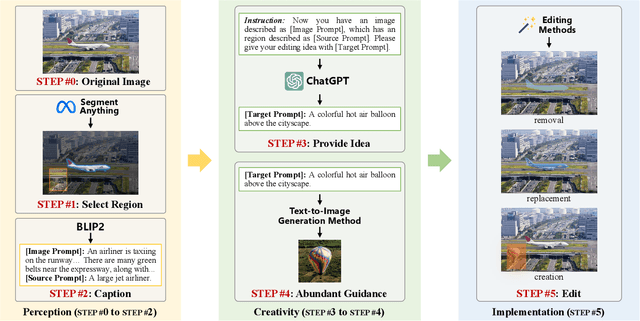


The accelerated advancement of generative AI significantly enhance the viability and effectiveness of generative regional editing methods. This evolution render the image manipulation more accessible, thereby intensifying the risk of altering the conveyed information within original images and even propagating misinformation. Consequently, there exists a critical demand for robust capable of detecting the edited images. However, the lack of comprehensive dataset containing images edited with abundant and advanced generative regional editing methods poses a substantial obstacle to the advancement of corresponding detection methods. We endeavor to fill the vacancy by constructing the GRE dataset, a large-scale generative regional editing dataset with the following advantages: 1) Collection of real-world original images, focusing on two frequently edited scenarios. 2) Integration of a logical and simulated editing pipeline, leveraging multiple large models in various modalities. 3) Inclusion of various editing approaches with distinct architectures. 4) Provision of comprehensive analysis tasks. We perform comprehensive experiments with proposed three tasks: edited image classification, edited method attribution and edited region localization, providing analysis of distinct editing methods and evaluation of detection methods in related fields. We expect that the GRE dataset can promote further research and exploration in the field of generative region editing detection.