Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Contrastive Learning for Definition Generation
Paper and Code

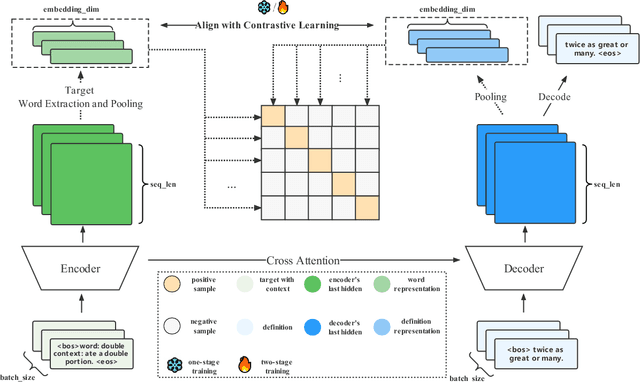

Recently, pre-trained transformer-based models have achieved great success in the task of definition generation (DG). However, previous encoder-decoder models lack effective representation learning to contain full semantic components of the given word, which leads to generating under-specific definitions. To address this problem, we propose a novel contrastive learning method, encouraging the model to capture more detailed semantic representations from the definition sequence encoding. According to both automatic and manual evaluation, the experimental results on three mainstream benchmarks demonstrate that the proposed method could generate more specific and high-quality definitions compared with several state-of-the-art models.
* Accepted by AACL-IJCNLP Main Conference 2022
View paper on