 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Multilingual ASR in the Wild Using Simple N-best Re-ranking
Paper and Code
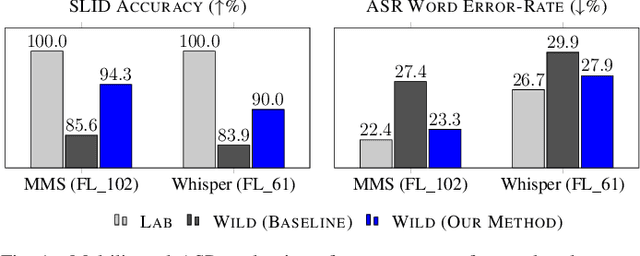
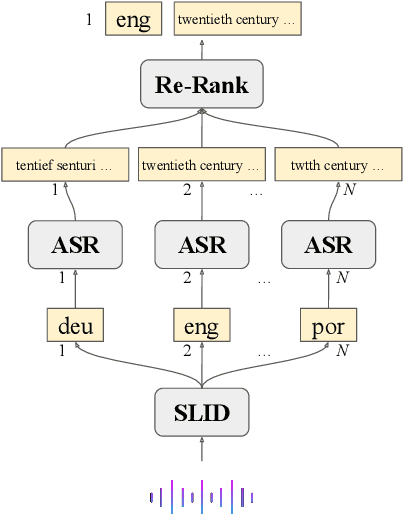
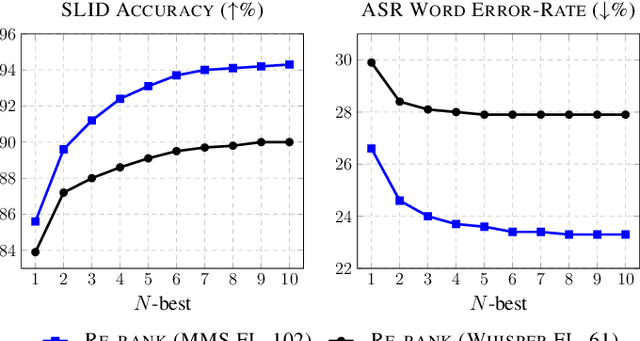

Multilingual Automatic Speech Recognition (ASR) models are typically evaluated in a setting where the ground-truth language of the speech utterance is known, however, this is often not the case for most practical settings. Automatic Spoken Language Identification (SLID) models are not perfect and misclassifications have a substantial impact on the final ASR accuracy. In this paper, we present a simple and effective N-best re-ranking approach to improve multilingual ASR accuracy for several prominent acoustic models by employing external features such as language models and text-based language identification models. Our results on FLEURS using the MMS and Whisper models show spoken language identification accuracy improvements of 8.7% and 6.1%, respectively and word error rates which are 3.3% and 2.0% lower on these benchmarks.