 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWACO: Word-Aligned Contrastive Learning for Speech Translation
Paper and Code
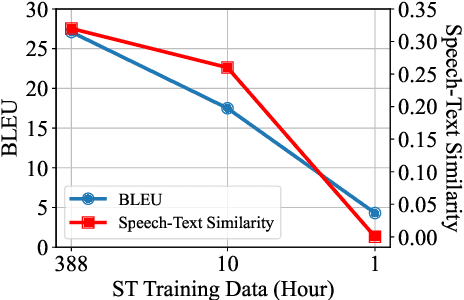



End-to-end Speech Translation (E2E ST) aims to translate source speech into target translation without generating the intermediate transcript. However, existing approaches for E2E ST degrade considerably when only limited ST data are available. We observe that an ST model's performance strongly correlates with its embedding similarity from speech and transcript. In this paper, we propose Word-Aligned COntrastive learning (WACO), a novel method for few-shot speech-to-text translation. Our key idea is bridging word-level representations for both modalities via contrastive learning. We evaluate WACO and other methods on the MuST-C dataset, a widely used ST benchmark. Our experiments demonstrate that WACO outperforms the best baseline methods by 0.7-8.5 BLEU points with only 1-hour parallel data. Code is available at https://anonymous.4open.science/r/WACO .