 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Should I Trust a Model is Private? Using Shifts in Model Explanation for Evaluating Privacy-Preserving Emotion Recognition Model
Paper and Code
Apr 18, 2021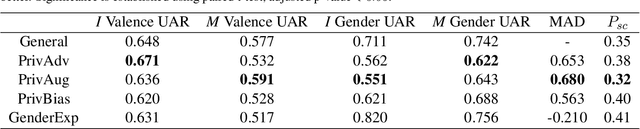
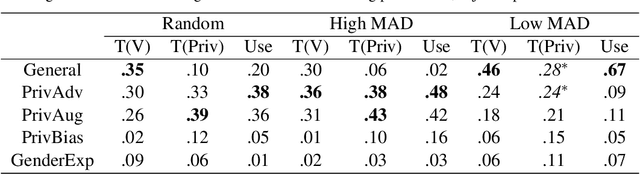
Privacy preservation is a crucial component of any real-world application. Yet, in applications relying on machine learning backends, this is challenging because models often capture more than a designer may have envisioned, resulting in the potential leakage of sensitive information. For example, emotion recognition models are susceptible to learning patterns between the target variable and other sensitive variables, patterns that can be maliciously re-purposed to obtain protected information. In this paper, we concentrate on using interpretable methods to evaluate a model's efficacy to preserve privacy with respect to sensitive variables. We focus on saliency-based explanations, explanations that highlight regions of the input text, which allows us to understand how model explanations shift when models are trained to preserve privacy. We show how certain commonly-used methods that seek to preserve privacy might not align with human perception of privacy preservation. We also show how some of these induce spurious correlations in the model between the input and the primary as well as secondary task, even if the improvement in evaluation metric is significant. Such correlations can hence lead to false assurances about the perceived privacy of the model because especially when used in cross corpus conditions. We conduct crowdsourcing experiments to evaluate the inclination of the evaluators to choose a particular model for a given task when model explanations are provided, and find that correlation of interpretation differences with sociolinguistic biases can be used as a proxy for user trust.