 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat You Feel Is Not What They See: On Predicting Self-Reported Emotion from Third-Party Observer Labels
Jan 29, 2026Self-reported emotion labels capture internal experience, while third-party labels reflect external perception. These perspectives often diverge, limiting the applicability of third-party-trained models to self-report contexts. This gap is critical in mental health, where accurate self-report modeling is essential for guiding intervention. We present the first cross-corpus evaluation of third-party-trained models on self-reports. We find activation unpredictable (CCC approximately 0) and valence moderately predictable (CCC approximately 0.3). Crucially, when content is personally significant to the speaker, models achieve high performance for valence (CCC approximately 0.6-0.8). Our findings point to personal significance as a key pathway for aligning external perception with internal experience and underscore the challenge of self-report activation modeling.
Rethinking Emotion Annotations in the Era of Large Language Models
Dec 10, 2024
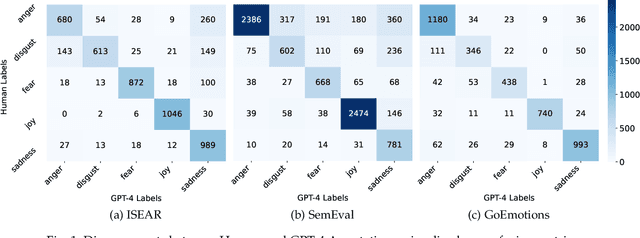
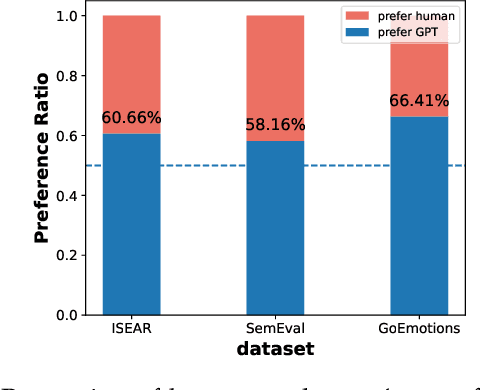
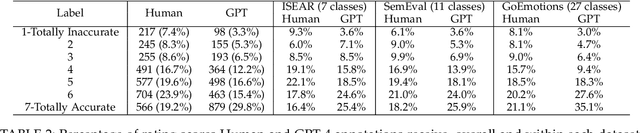
Modern affective computing systems rely heavily on datasets with human-annotated emotion labels, for training and evaluation. However, human annotations are expensive to obtain, sensitive to study design, and difficult to quality control, because of the subjective nature of emotions. Meanwhile, Large Language Models (LLMs) have shown remarkable performance on many Natural Language Understanding tasks, emerging as a promising tool for text annotation. In this work, we analyze the complexities of emotion annotation in the context of LLMs, focusing on GPT-4 as a leading model. In our experiments, GPT-4 achieves high ratings in a human evaluation study, painting a more positive picture than previous work, in which human labels served as the only ground truth. On the other hand, we observe differences between human and GPT-4 emotion perception, underscoring the importance of human input in annotation studies. To harness GPT-4's strength while preserving human perspective, we explore two ways of integrating GPT-4 into emotion annotation pipelines, showing its potential to flag low-quality labels, reduce the workload of human annotators, and improve downstream model learning performance and efficiency. Together, our findings highlight opportunities for new emotion labeling practices and suggest the use of LLMs as a promising tool to aid human annotation.
The Whole Is Bigger Than the Sum of Its Parts: Modeling Individual Annotators to Capture Emotional Variability
Aug 21, 2024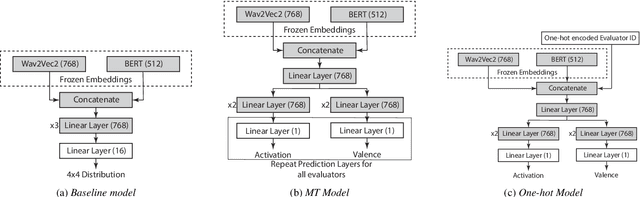

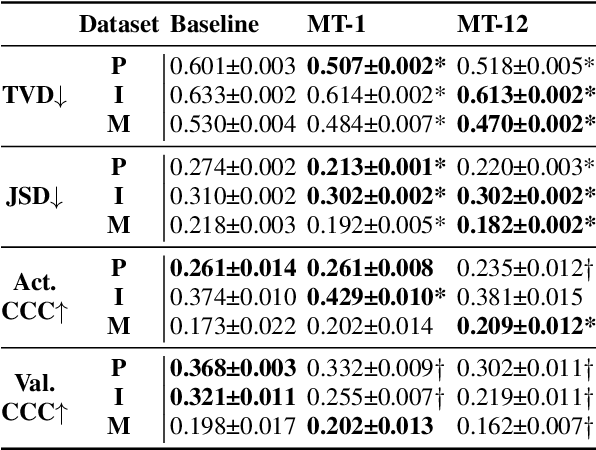
Emotion expression and perception are nuanced, complex, and highly subjective processes. When multiple annotators label emotional data, the resulting labels contain high variability. Most speech emotion recognition tasks address this by averaging annotator labels as ground truth. However, this process omits the nuance of emotion and inter-annotator variability, which are important signals to capture. Previous work has attempted to learn distributions to capture emotion variability, but these methods also lose information about the individual annotators. We address these limitations by learning to predict individual annotators and by introducing a novel method to create distributions from continuous model outputs that permit the learning of emotion distributions during model training. We show that this combined approach can result in emotion distributions that are more accurate than those seen in prior work, in both within- and cross-corpus settings.