 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiachronic Document Dataset for Semantic Layout Analysis
Nov 15, 2024



We present a novel, open-access dataset designed for semantic layout analysis, built to support document recreation workflows through mapping with the Text Encoding Initiative (TEI) standard. This dataset includes 7,254 annotated pages spanning a large temporal range (1600-2024) of digitised and born-digital materials across diverse document types (magazines, papers from sciences and humanities, PhD theses, monographs, plays, administrative reports, etc.) sorted into modular subsets. By incorporating content from different periods and genres, it addresses varying layout complexities and historical changes in document structure. The modular design allows domain-specific configurations. We evaluate object detection models on this dataset, examining the impact of input size and subset-based training. Results show that a 1280-pixel input size for YOLO is optimal and that training on subsets generally benefits from incorporating them into a generic model rather than fine-tuning pre-trained weights.
From FreEM to D'AlemBERT: a Large Corpus and a Language Model for Early Modern French
Feb 18, 2022
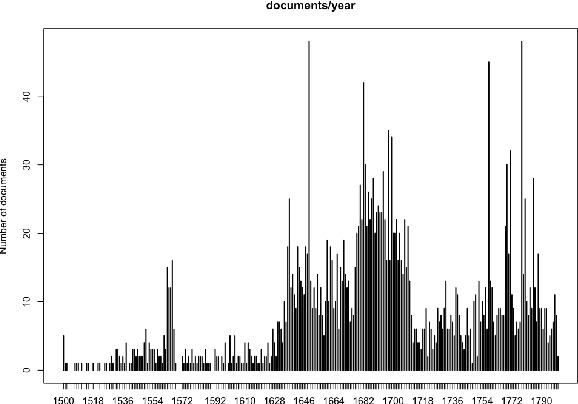
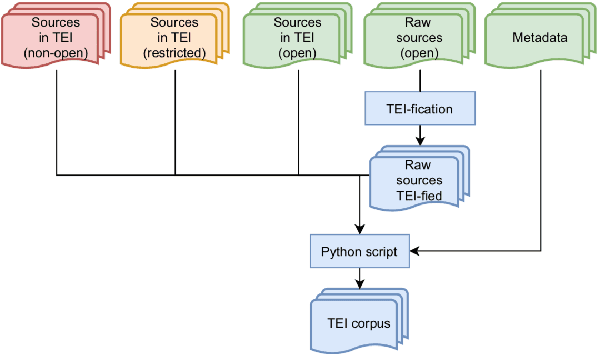
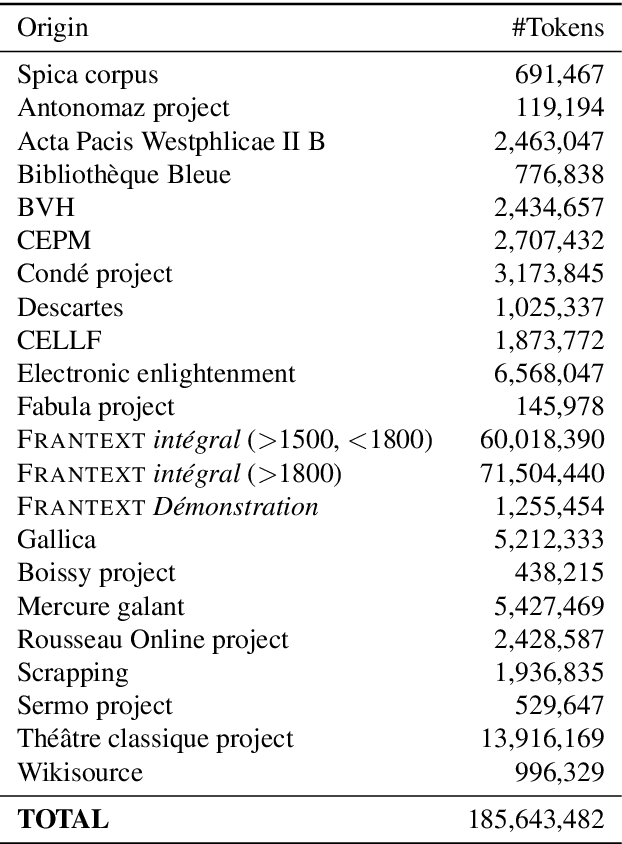
Language models for historical states of language are becoming increasingly important to allow the optimal digitisation and analysis of old textual sources. Because these historical states are at the same time more complex to process and more scarce in the corpora available, specific efforts are necessary to train natural language processing (NLP) tools adapted to the data. In this paper, we present our efforts to develop NLP tools for Early Modern French (historical French from the 16$^\text{th}$ to the 18$^\text{th}$ centuries). We present the $\text{FreEM}_{\text{max}}$ corpus of Early Modern French and D'AlemBERT, a RoBERTa-based language model trained on $\text{FreEM}_{\text{max}}$. We evaluate the usefulness of D'AlemBERT by fine-tuning it on a part-of-speech tagging task, outperforming previous work on the test set. Importantly, we find evidence for the transfer learning capacity of the language model, since its performance on lesser-resourced time periods appears to have been boosted by the more resourced ones. We release D'AlemBERT and the open-sourced subpart of the $\text{FreEM}_{\text{max}}$ corpus.
Standardizing linguistic data: method and tools for annotating (pre-orthographic) French
Nov 22, 2020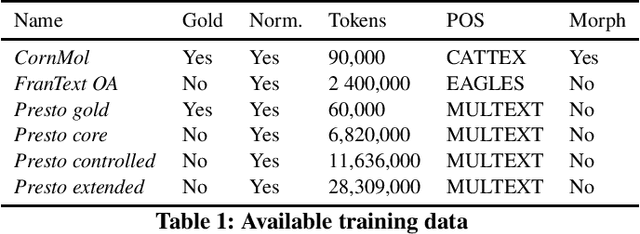
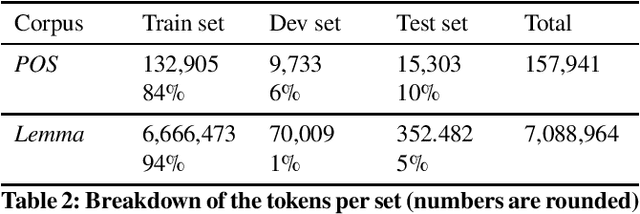
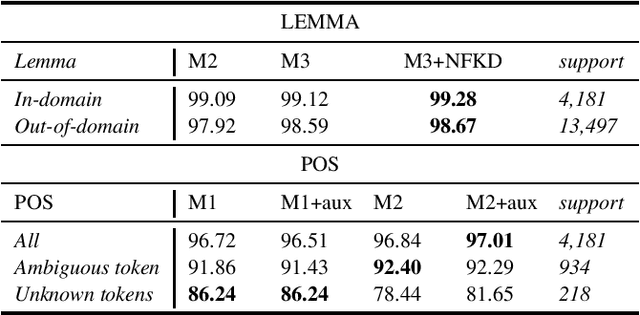
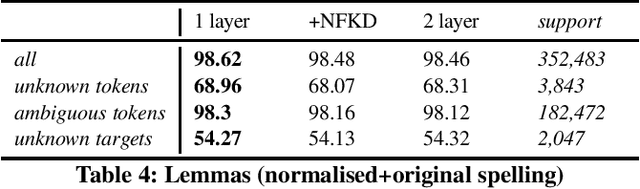
With the development of big corpora of various periods, it becomes crucial to standardise linguistic annotation (e.g. lemmas, POS tags, morphological annotation) to increase the interoperability of the data produced, despite diachronic variations. In the present paper, we describe both methodologically (by proposing annotation principles) and technically (by creating the required training data and the relevant models) the production of a linguistic tagger for (early) modern French (16-18th c.), taking as much as possible into account already existing standards for contemporary and, especially, medieval French.
Corpus and Models for Lemmatisation and POS-tagging of Classical French Theatre
May 15, 2020
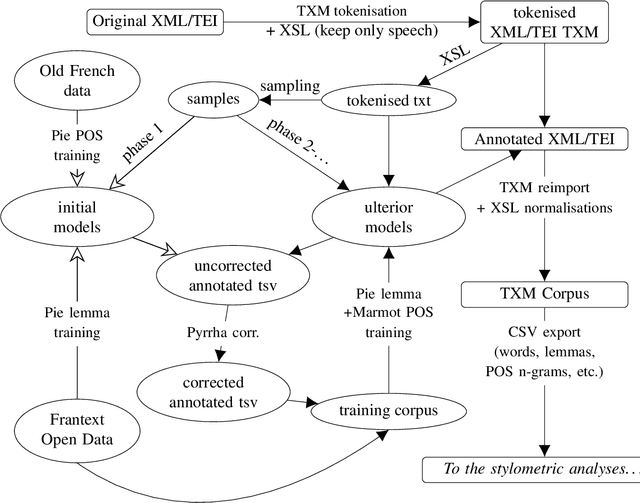
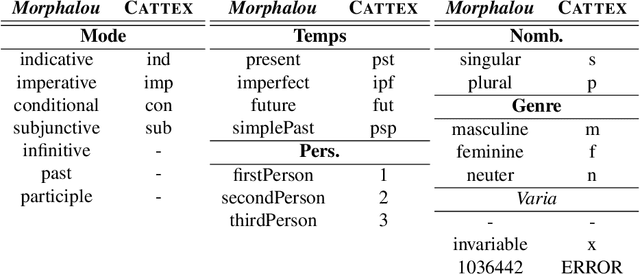
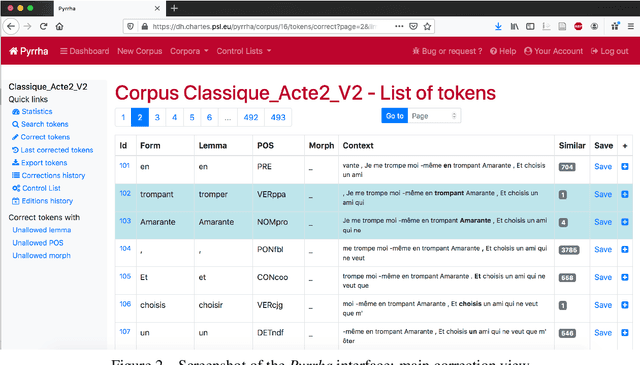
This paper describes the process of building an annotated corpus and training models for classical French literature, with a focus on theatre, and particularly comedies in verse. It was originally developed as a preliminary step to the stylometric analyses presented in Cafiero and Camps [2019]. The use of a recent lemmatiser based on neural networks and a CRF tagger allows to achieve accuracies beyond the current state-of-the art on the in-domain test, and proves to be robust during out-of-domain tests, i.e.up to 20th c.novels.