 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReading or Guessing? Visual Grounding Failures of Vision-Language Models for OCR in Ancient Greek Editions
May 26, 2026Recent work has shown that Vision-Language Models (VLMs) used for optical character recognition (OCR) can generate plausible but visually unsupported text, suggesting reliance on language priors. Comparing open-weight VLMs with traditional OCR baselines on low-resource Ancient Greek critical editions, we show that VLM errors often remain fluent even when wrong, producing plausible Greek substitutions where traditional engines produce local recognition noise. To analyze visual evidence during decoding, we introduce controlled image perturbations and token-level grounding measures based on conditional versus image-free decoding distributions. Under character-level perturbations, VLMs diverge sharply from the perturbed ground truth while traditional OCR remains comparatively faithful; however, token-level analysis shows that prior reliance is model-specific: in an OCR-specialist model, fluent lexical errors are produced with little reliance on the image, whereas general-purpose VLMs remain conditioned on the visual input even when wrong. Decode-time interventions fail to reliably restore grounding, while post-OCR language-model correction improves several systems only by repairing text after generation. Our results extend prior evidence of OCR language-prior reliance to low-resource historical documents and a broader set of models, showing that fluent output is not necessarily visually grounded and motivating interpretability-driven evaluation beyond aggregate accuracy.
Structure-Aware Text Recognition for Ancient Greek Critical Editions
Mar 03, 2026Recent advances in visual language models (VLMs) have transformed end-to-end document understanding. However, their ability to interpret the complex layout semantics of historical scholarly texts remains limited. This paper investigates structure-aware text recognition for Ancient Greek critical editions, which have dense reference hierarchies and extensive marginal annotations. We introduce two novel resources: (i) a large-scale synthetic corpus of 185,000 page images generated from TEI/XML sources with controlled typographic and layout variation, and (ii) a curated benchmark of real scanned editions spanning more than a century of editorial and typographic practices. Using these datasets, we evaluate three state-of-the-art VLMs under both zero-shot and fine-tuning regimes. Our experiments reveal substantial limitations in current VLM architectures when confronted with highly structured historical documents. In zero-shot settings, most models significantly underperform compared to established off-the-shelf software. Nevertheless, the Qwen3VL-8B model achieves state-of-the-art performance, reaching a median Character Error Rate of 1.0\% on real scans. These results highlight both the current shortcomings and the future potential of VLMs for structure-aware recognition of complex scholarly documents.
Pre-Editorial Normalization for Automatically Transcribed Medieval Manuscripts in Old French and Latin
Feb 14, 2026Recent advances in Automatic Text Recognition (ATR) have improved access to historical archives, yet a methodological divide persists between palaeographic transcriptions and normalized digital editions. While ATR models trained on more palaeographically-oriented datasets such as CATMuS have shown greater generalizability, their raw outputs remain poorly compatible with most readers and downstream NLP tools, thus creating a usability gap. On the other hand, ATR models trained to produce normalized outputs have been shown to struggle to adapt to new domains and tend to over-normalize and hallucinate. We introduce the task of Pre-Editorial Normalization (PEN), which consists in normalizing graphemic ATR output according to editorial conventions, which has the advantage of keeping an intermediate step with palaeographic fidelity while providing a normalized version for practical usability. We present a new dataset derived from the CoMMA corpus and aligned with digitized Old French and Latin editions using passim. We also produce a manually corrected gold-standard evaluation set. We benchmark this resource using ByT5-based sequence-to-sequence models on normalization and pre-annotation tasks. Our contributions include the formal definition of PEN, a 4.66M-sample silver training corpus, a 1.8k-sample gold evaluation set, and a normalization model achieving a 6.7% CER, substantially outperforming previous models for this task.
How Should We Model the Probability of a Language?
Feb 09, 2026Of the over 7,000 languages spoken in the world, commercial language identification (LID) systems only reliably identify a few hundred in written form. Research-grade systems extend this coverage under certain circumstances, but for most languages coverage remains patchy or nonexistent. This position paper argues that this situation is largely self-imposed. In particular, it arises from a persistent framing of LID as decontextualized text classification, which obscures the central role of prior probability estimation and is reinforced by institutional incentives that favor global, fixed-prior models. We argue that improving coverage for tail languages requires rethinking LID as a routing problem and developing principled ways to incorporate environmental cues that make languages locally plausible.
CommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
KréyoLID From Language Identification Towards Language Mining
Mar 09, 2025

Automatic language identification is frequently framed as a multi-class classification problem. However, when creating digital corpora for less commonly written languages, it may be more appropriate to consider it a data mining problem. For these varieties, one knows ahead of time that the vast majority of documents are of little interest. By minimizing resources spent on classifying such documents, we can create corpora much faster and with better coverage than using established pipelines. To demonstrate the effectiveness of the language mining perspective, we introduce a new pipeline and corpora for several French-based Creoles.
Diachronic Document Dataset for Semantic Layout Analysis
Nov 15, 2024



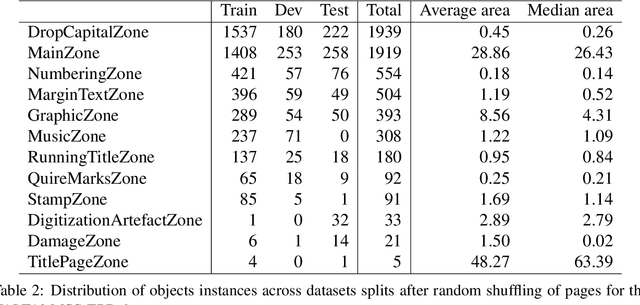
We present a novel, open-access dataset designed for semantic layout analysis, built to support document recreation workflows through mapping with the Text Encoding Initiative (TEI) standard. This dataset includes 7,254 annotated pages spanning a large temporal range (1600-2024) of digitised and born-digital materials across diverse document types (magazines, papers from sciences and humanities, PhD theses, monographs, plays, administrative reports, etc.) sorted into modular subsets. By incorporating content from different periods and genres, it addresses varying layout complexities and historical changes in document structure. The modular design allows domain-specific configurations. We evaluate object detection models on this dataset, examining the impact of input size and subset-based training. Results show that a 1280-pixel input size for YOLO is optimal and that training on subsets generally benefits from incorporating them into a generic model rather than fine-tuning pre-trained weights.
Molyé: A Corpus-based Approach to Language Contact in Colonial France
Aug 08, 2024



Whether or not several Creole languages which developed during the early modern period can be considered genetic descendants of European languages has been the subject of intense debate. This is in large part due to the absence of evidence of intermediate forms. This work introduces a new open corpus, the Moly\'e corpus, which combines stereotypical representations of three kinds of language variation in Europe with early attestations of French-based Creole languages across a period of 400 years. It is intended to facilitate future research on the continuity between contact situations in Europe and Creolophone (former) colonies.
Detecting Sexual Content at the Sentence Level in First Millennium Latin Texts
Sep 25, 2023In this study, we propose to evaluate the use of deep learning methods for semantic classification at the sentence level to accelerate the process of corpus building in the field of humanities and linguistics, a traditional and time-consuming task. We introduce a novel corpus comprising around 2500 sentences spanning from 300 BCE to 900 CE including sexual semantics (medical, erotica, etc.). We evaluate various sentence classification approaches and different input embedding layers, and show that all consistently outperform simple token-based searches. We explore the integration of idiolectal and sociolectal metadata embeddings (centuries, author, type of writing), but find that it leads to overfitting. Our results demonstrate the effectiveness of this approach, achieving high precision and true positive rates (TPR) of respectively 70.60% and 86.33% using HAN. We evaluate the impact of the dataset size on the model performances (420 instead of 2013), and show that, while our models perform worse, they still offer a high enough precision and TPR, even without MLM, respectively 69% and 51%. Given the result, we provide an analysis of the attention mechanism as a supporting added value for humanists in order to produce more data.
You Actually Look Twice At it : using an object detection approach instead of region segmentation within the Kraken engine
Jul 19, 2022

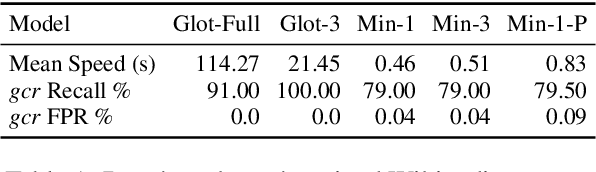
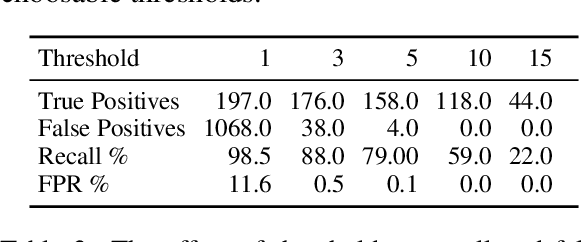
Layout Analysis (the identification of zones and their classification) is the first step along line segmentation in Optical Character Recognition and similar tasks. The ability of identifying main body of text from marginal text or running titles makes the difference between extracting the work full text of a digitized book and noisy outputs. We show that most segmenters focus on pixel classification and that polygonization of this output has not been used as a target for the latest competition on historical document (ICDAR 2017 and onwards), despite being the focus in the early 2010s. We propose to shift, for efficiency, the task from a pixel classification-based polygonization to an object detection using isothetic rectangles. We compare the output of Kraken and YOLOv5 in terms of segmentation and show that the later severely outperforms the first on small datasets (1110 samples and below). We release two datasets for training and evaluation on historical documents as well as a new package, YALTAi, which injects YOLOv5 in the segmentation pipeline of Kraken 4.1.