Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKréyoLID From Language Identification Towards Language Mining
Paper and Code

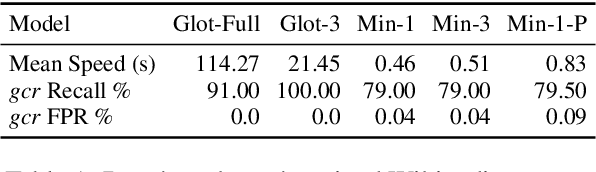
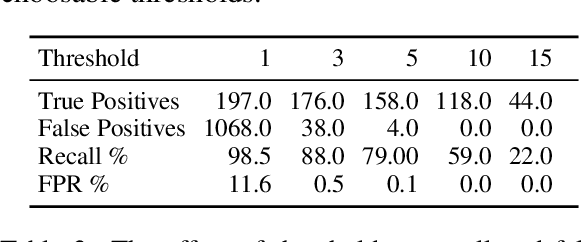

Automatic language identification is frequently framed as a multi-class classification problem. However, when creating digital corpora for less commonly written languages, it may be more appropriate to consider it a data mining problem. For these varieties, one knows ahead of time that the vast majority of documents are of little interest. By minimizing resources spent on classifying such documents, we can create corpora much faster and with better coverage than using established pipelines. To demonstrate the effectiveness of the language mining perspective, we introduce a new pipeline and corpora for several French-based Creoles.
* 8 main pages
View paper on