 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-Editorial Normalization for Automatically Transcribed Medieval Manuscripts in Old French and Latin
Feb 14, 2026Recent advances in Automatic Text Recognition (ATR) have improved access to historical archives, yet a methodological divide persists between palaeographic transcriptions and normalized digital editions. While ATR models trained on more palaeographically-oriented datasets such as CATMuS have shown greater generalizability, their raw outputs remain poorly compatible with most readers and downstream NLP tools, thus creating a usability gap. On the other hand, ATR models trained to produce normalized outputs have been shown to struggle to adapt to new domains and tend to over-normalize and hallucinate. We introduce the task of Pre-Editorial Normalization (PEN), which consists in normalizing graphemic ATR output according to editorial conventions, which has the advantage of keeping an intermediate step with palaeographic fidelity while providing a normalized version for practical usability. We present a new dataset derived from the CoMMA corpus and aligned with digitized Old French and Latin editions using passim. We also produce a manually corrected gold-standard evaluation set. We benchmark this resource using ByT5-based sequence-to-sequence models on normalization and pre-annotation tasks. Our contributions include the formal definition of PEN, a 4.66M-sample silver training corpus, a 1.8k-sample gold evaluation set, and a normalization model achieving a 6.7% CER, substantially outperforming previous models for this task.
Corpus and Models for Lemmatisation and POS-tagging of Old French
Sep 23, 2021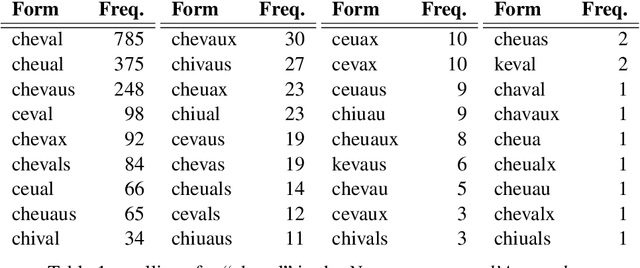
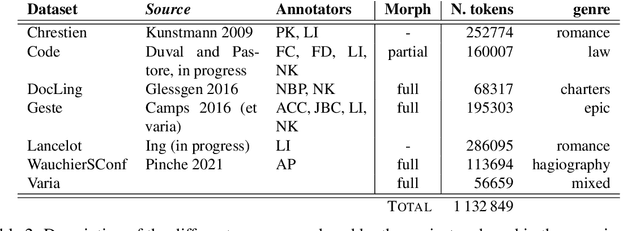
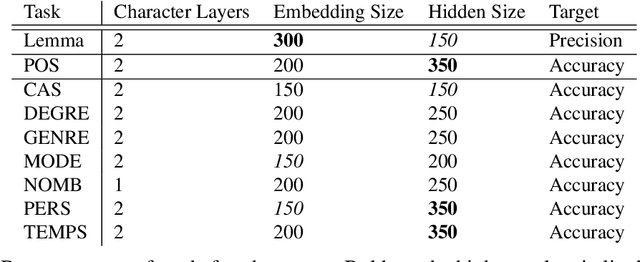
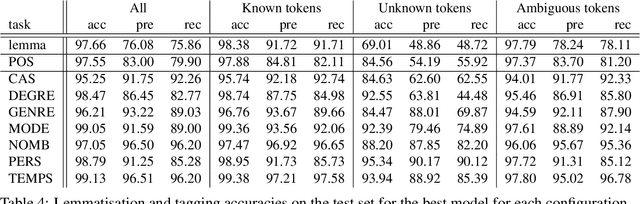
Old French is a typical example of an under-resourced historic languages, that furtherly displays animportant amount of linguistic variation. In this paper, we present the current results of a long going project (2015-...) and describe how we broached the difficult question of providing lemmatisation andPOS models for Old French with the help of neural taggers and the progressive constitution of dedicated corpora.
Stylometry for Noisy Medieval Data: Evaluating Paul Meyer's Hagiographic Hypothesis
Dec 07, 2020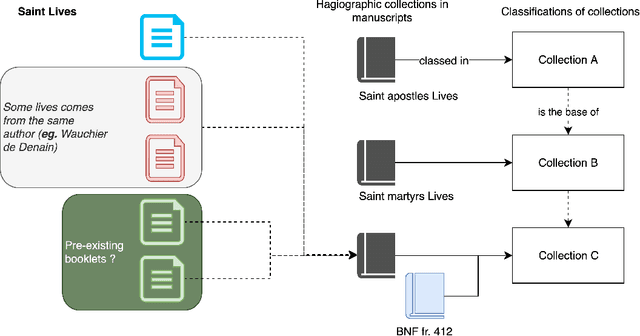


Stylometric analysis of medieval vernacular texts is still a significant challenge: the importance of scribal variation, be it spelling or more substantial, as well as the variants and errors introduced in the tradition, complicate the task of the would-be stylometrist. Basing the analysis on the study of the copy from a single hand of several texts can partially mitigate these issues (Camps and Cafiero, 2013), but the limited availability of complete diplomatic transcriptions might make this difficult. In this paper, we use a workflow combining handwritten text recognition and stylometric analysis, applied to the case of the hagiographic works contained in MS BnF, fr. 412. We seek to evaluate Paul Meyer's hypothesis about the constitution of groups of hagiographic works, as well as to examine potential authorial groupings in a vastly anonymous corpus.