 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho could be behind QAnon? Authorship attribution with supervised machine-learning
Mar 03, 2023A series of social media posts signed under the pseudonym "Q", started a movement known as QAnon, which led some of its most radical supporters to violent and illegal actions. To identify the person(s) behind Q, we evaluate the coincidence between the linguistic properties of the texts written by Q and to those written by a list of suspects provided by journalistic investigation. To identify the authors of these posts, serious challenges have to be addressed. The "Q drops" are very short texts, written in a way that constitute a sort of literary genre in itself, with very peculiar features of style. These texts might have been written by different authors, whose other writings are often hard to find. After an online ethnology of the movement, necessary to collect enough material written by these thirteen potential authors, we use supervised machine learning to build stylistic profiles for each of them. We then performed a rolling analysis on Q's writings, to see if any of those linguistic profiles match the so-called 'QDrops' in part or entirety. We conclude that two different individuals, Paul F. and Ron W., are the closest match to Q's linguistic signature, and they could have successively written Q's texts. These potential authors are not high-ranked personality from the U.S. administration, but rather social media activists.
Corpus and Models for Lemmatisation and POS-tagging of Old French
Sep 23, 2021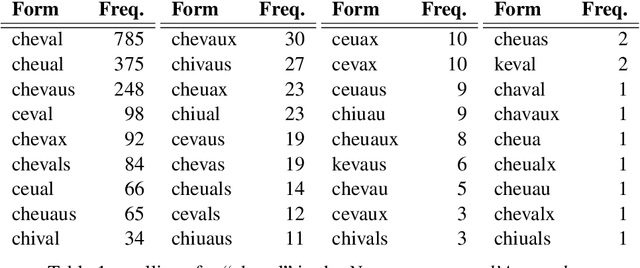
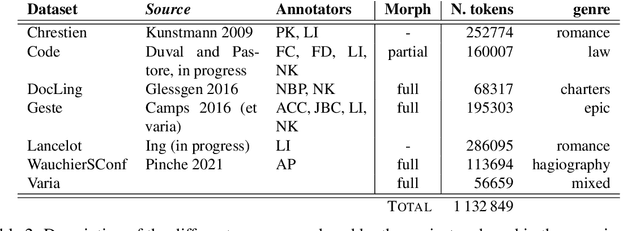
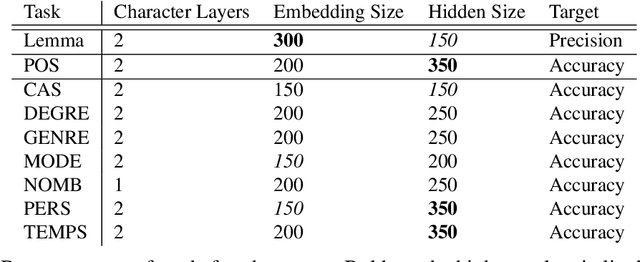
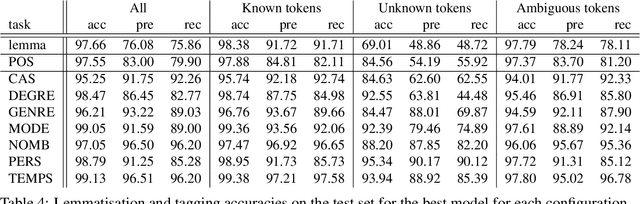
Old French is a typical example of an under-resourced historic languages, that furtherly displays animportant amount of linguistic variation. In this paper, we present the current results of a long going project (2015-...) and describe how we broached the difficult question of providing lemmatisation andPOS models for Old French with the help of neural taggers and the progressive constitution of dedicated corpora.
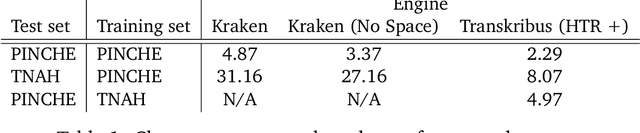
Handling Heavily Abbreviated Manuscripts: HTR engines vs text normalisation approaches
Jul 07, 2021
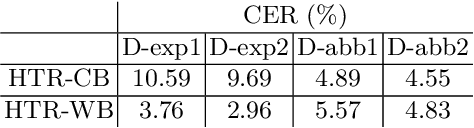
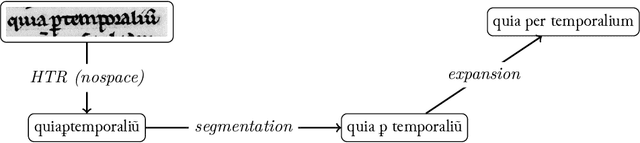

Although abbreviations are fairly common in handwritten sources, particularly in medieval and modern Western manuscripts, previous research dealing with computational approaches to their expansion is scarce. Yet abbreviations present particular challenges to computational approaches such as handwritten text recognition and natural language processing tasks. Often, pre-processing ultimately aims to lead from a digitised image of the source to a normalised text, which includes expansion of the abbreviations. We explore different setups to obtain such a normalised text, either directly, by training HTR engines on normalised (i.e., expanded, disabbreviated) text, or by decomposing the process into discrete steps, each making use of specialist models for recognition, word segmentation and normalisation. The case studies considered here are drawn from the medieval Latin tradition.
Stylometry for Noisy Medieval Data: Evaluating Paul Meyer's Hagiographic Hypothesis
Dec 07, 2020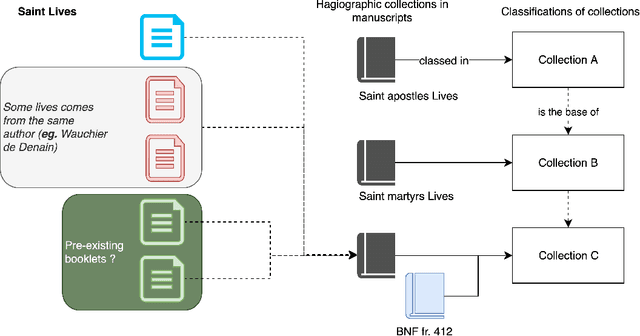


Stylometric analysis of medieval vernacular texts is still a significant challenge: the importance of scribal variation, be it spelling or more substantial, as well as the variants and errors introduced in the tradition, complicate the task of the would-be stylometrist. Basing the analysis on the study of the copy from a single hand of several texts can partially mitigate these issues (Camps and Cafiero, 2013), but the limited availability of complete diplomatic transcriptions might make this difficult. In this paper, we use a workflow combining handwritten text recognition and stylometric analysis, applied to the case of the hagiographic works contained in MS BnF, fr. 412. We seek to evaluate Paul Meyer's hypothesis about the constitution of groups of hagiographic works, as well as to examine potential authorial groupings in a vastly anonymous corpus.
Standardizing linguistic data: method and tools for annotating (pre-orthographic) French
Nov 22, 2020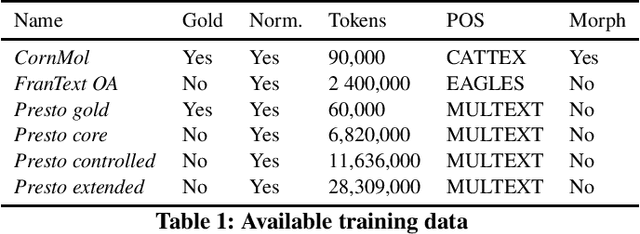
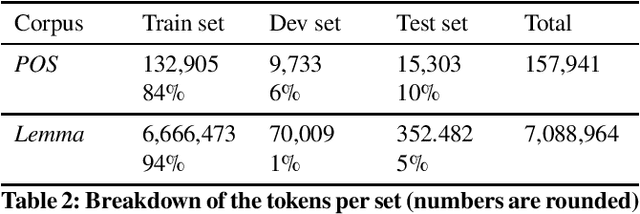
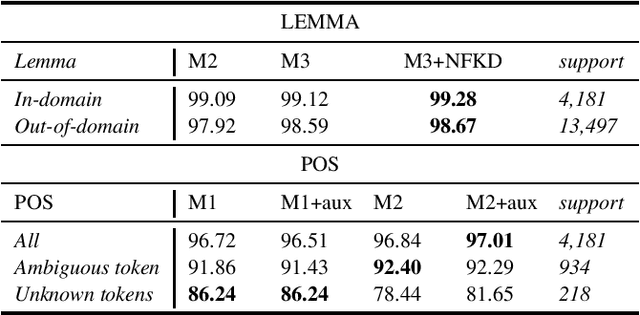
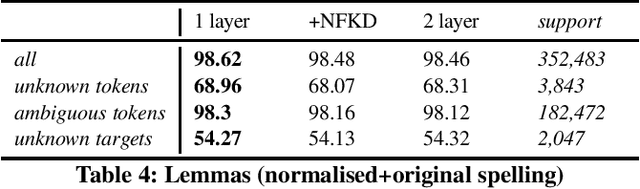
With the development of big corpora of various periods, it becomes crucial to standardise linguistic annotation (e.g. lemmas, POS tags, morphological annotation) to increase the interoperability of the data produced, despite diachronic variations. In the present paper, we describe both methodologically (by proposing annotation principles) and technically (by creating the required training data and the relevant models) the production of a linguistic tagger for (early) modern French (16-18th c.), taking as much as possible into account already existing standards for contemporary and, especially, medieval French.
Corpus and Models for Lemmatisation and POS-tagging of Classical French Theatre
May 15, 2020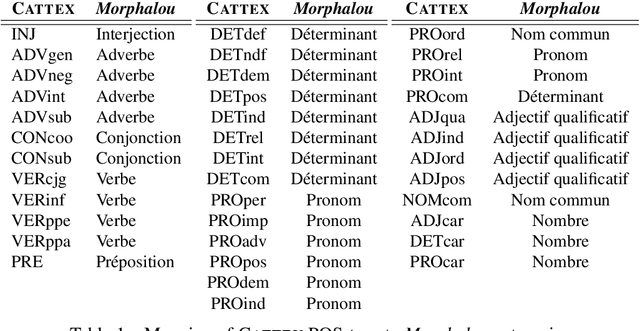
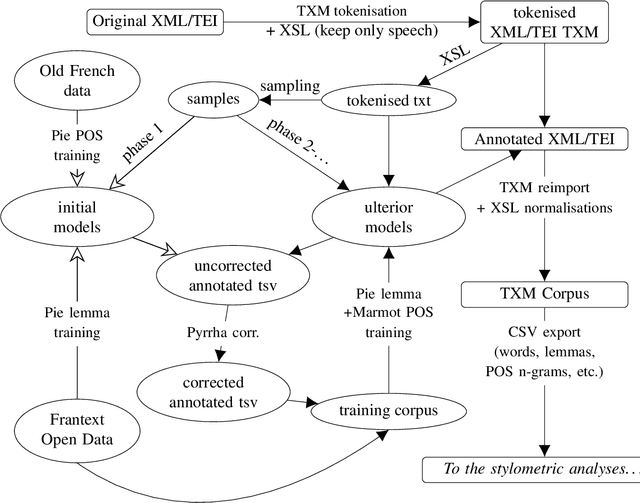
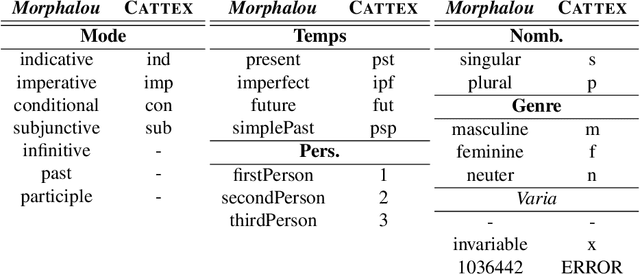
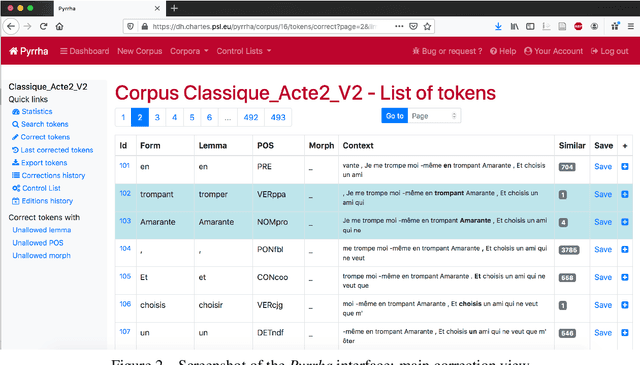
This paper describes the process of building an annotated corpus and training models for classical French literature, with a focus on theatre, and particularly comedies in verse. It was originally developed as a preliminary step to the stylometric analyses presented in Cafiero and Camps [2019]. The use of a recent lemmatiser based on neural networks and a CRF tagger allows to achieve accuracies beyond the current state-of-the art on the in-domain test, and proves to be robust during out-of-domain tests, i.e.up to 20th c.novels.
Why Molière most likely did write his plays
Jan 02, 2020As for Shakespeare, a hard-fought debate has emerged about Moli\`ere, a supposedly uneducated actor who, according to some, could not have written the masterpieces attributed to him. In the past decades, the century-old thesis according to which Pierre Corneille would be their actual author has become popular, mostly because of new works in computational linguistics. These results are reassessed here through state-of-the-art attribution methods. We study a corpus of comedies in verse by major authors of Moli\`ere and Corneille's time. Analysis of lexicon, rhymes, word forms, affixes, morphosyntactic sequences, and function words do not give any clue that another author among the major playwrights of the time would have written the plays signed under the name Moli\`ere.
Producing Corpora of Medieval and Premodern Occitan
Apr 26, 2019



At a time when the quantity of - more or less freely - available data is increasing significantly, thanks to digital corpora, editions or libraries, the development of data mining tools or deep learning methods allows researchers to build a corpus of study tailored for their research, to enrich their data and to exploit them.Open optical character recognition (OCR) tools can be adapted to old prints, incunabula or even manuscripts, with usable results, allowing the rapid creation of textual corpora. The alternation of training and correction phases makes it possible to improve the quality of the results by rapidly accumulating raw text data. These can then be structured, for example in XML/TEI, and enriched.The enrichment of the texts with graphic or linguistic annotations can also be automated. These processes, known to linguists and functional for modern languages, present difficulties for languages such as Medieval Occitan, due in part to the absence of big enough lemmatized corpora. Suggestions for the creation of tools adapted to the considerable spelling variation of ancient languages will be presented, as well as experiments for the lemmatization of Medieval and Premodern Occitan.These techniques open the way for many exploitations. The much desired increase in the amount of available quality texts and data makes it possible to improve digital philology methods, if everyone takes the trouble to make their data freely available online and reusable.By exposing different technical solutions and some micro-analyses as examples, this paper aims to show part of what digital philology can offer to researchers in the Occitan domain, while recalling the ethical issues on which such practices are based.
Manuscripts in Time and Space: Experiments in Scriptometrics on an Old French Corpus
Jan 30, 2018
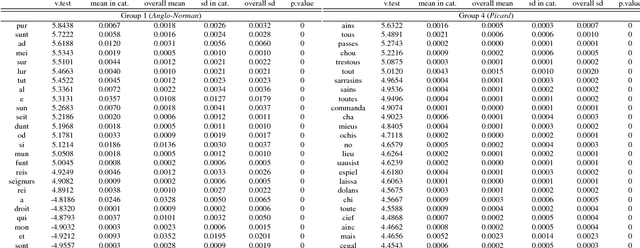
Witnesses of medieval literary texts, preserved in manuscript, are layered objects , being almost exclusively copies of copies. This results in multiple and hard to distinguish linguistic strata -- the author's scripta interacting with the scriptae of the various scribes -- in a context where literary written language is already a dialectal hybrid. Moreover, no single linguistic phenomenon allows to distinguish between different scriptae, and only the combination of multiple characteristics is likely to be significant [9] -- but which ones? The most common approach is to search for these features in a set of previously selected texts, that are supposed to be representative of a given scripta. This can induce a circularity, in which texts are used to select features that in turn characterise them as belonging to a linguistic area. To counter this issue, this paper offers an unsupervised and corpus-based approach, in which clustering methods are applied to an Old French corpus to identify main divisions and groups. Ultimately, scriptometric profiles are built for each of them.
* Andrew U. Frank; Christine Ivanovic; Francesco Mambrini; Marco Passarotti; Caroline Sporleder. Corpus-Based Research in the Humanities CRH-2, Jan 2018, Vienna, Austria. Available, online: https://www.oeaw.ac.at/fileadmin/subsites/academiaecorpora/PDF/CRH2.pdf