 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiming In stand-up Comedy: Text, Audio, Laughter, Kinesics (TIC-TALK): Pipeline and Database for the Multimodal Study of Comedic Timing
Mar 23, 2026Stand-up comedy, and humor in general, are often studied through their verbal content. Yet live performance relies just as much on embodied presence and audience feedback. We introduce TIC-TALK, a multimodal resource with 5,400+ temporally aligned topic segments capturing language, gesture, and audience response across 90 professionally filmed stand-up comedy specials (2015-2024). The pipeline combines BERTopic for 60 s thematic segmentation with dense sentence embeddings, Whisper-AT for 0.8 s laughter detection, a fine-tuned YOLOv8-cls shot classifier, and YOLOv8s-pose for raw keypoint extraction at 1 fps. Raw 17-joint skeletal coordinates are retained without prior clustering, enabling the computation of continuous kinematic signals-arm spread, kinetic energy, and trunk lean-that serve as proxies for performance dynamics. All streams are aligned by hierarchical temporal containment without resampling, and each topic segment stores its sentence-BERT embedding for downstream similarity and clustering tasks. As a concrete use case, we study laughter dynamics across 24 thematic topics: kinetic energy negatively predicts audience laughter rate (r = -0.75, N = 24), consistent with a stillness-before-punchline pattern; personal and bodily content elicits more laughter than geopolitical themes; and shot close-up proportion correlates positively with laughter (r = +0.28), consistent with reactive montage.
The Patrologia Graeca Corpus: OCR, Annotation, and Open Release of Noisy Nineteenth-Century Polytonic Greek Editions
Mar 10, 2026We present the Patrologia Graeca Corpus, the first large-scale open OCR and linguistic resource for nineteenthcentury editions of Ancient Greek. The collection covers the remaining undigitized volumes of the Patrologia Graeca (PG), printed in complex bilingual (Greek-Latin) layouts and characterized by highly degraded polytonic Greek typography. Through a dedicated pipeline combining YOLO-based layout detection and CRNN-based text recognition, we achieve a character error rate (CER) of 1.05% and a word error rate (WER) of 4.69%, largely outperforming existing OCR systems for polytonic Greek. The resulting corpus contains around six million lemmatized and part-of-speech tagged tokens, aligned with full OCR and layout annotations. Beyond its philological value, this corpus establishes a new benchmark for OCR on noisy polytonic Greek and provides training material for future models, including LLMs.
Under-resourced studies of under-resourced languages: lemmatization and POS-tagging with LLM annotators for historical Armenian, Georgian, Greek and Syriac
Feb 17, 2026Low-resource languages pose persistent challenges for Natural Language Processing tasks such as lemmatization and part-of-speech (POS) tagging. This paper investigates the capacity of recent large language models (LLMs), including GPT-4 variants and open-weight Mistral models, to address these tasks in few-shot and zero-shot settings for four historically and linguistically diverse under-resourced languages: Ancient Greek, Classical Armenian, Old Georgian, and Syriac. Using a novel benchmark comprising aligned training and out-of-domain test corpora, we evaluate the performance of foundation models across lemmatization and POS-tagging, and compare them with PIE, a task-specific RNN baseline. Our results demonstrate that LLMs, even without fine-tuning, achieve competitive or superior performance in POS-tagging and lemmatization across most languages in few-shot settings. Significant challenges persist for languages characterized by complex morphology and non-Latin scripts, but we demonstrate that LLMs are a credible and relevant option for initiating linguistic annotation tasks in the absence of data, serving as an effective aid for annotation.
New Results for the Text Recognition of Arabic Maghrib{ī} Manuscripts -- Managing an Under-resourced Script
Nov 29, 2022HTR models development has become a conventional step for digital humanities projects. The performance of these models, often quite high, relies on manual transcription and numerous handwritten documents. Although the method has proven successful for Latin scripts, a similar amount of data is not yet achievable for scripts considered poorly-endowed, like Arabic scripts. In that respect, we are introducing and assessing a new modus operandi for HTR models development and fine-tuning dedicated to the Arabic Maghrib{\=i} scripts. The comparison between several state-of-the-art HTR demonstrates the relevance of a word-based neural approach specialized for Arabic, capable to achieve an error rate below 5% with only 10 pages manually transcribed. These results open new perspectives for Arabic scripts processing and more generally for poorly-endowed languages processing. This research is part of the development of RASAM dataset in partnership with the GIS MOMM and the BULAC.
Handling Heavily Abbreviated Manuscripts: HTR engines vs text normalisation approaches
Jul 07, 2021
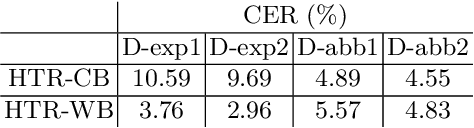
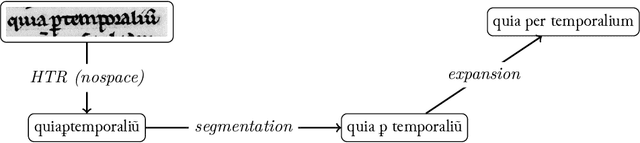

Although abbreviations are fairly common in handwritten sources, particularly in medieval and modern Western manuscripts, previous research dealing with computational approaches to their expansion is scarce. Yet abbreviations present particular challenges to computational approaches such as handwritten text recognition and natural language processing tasks. Often, pre-processing ultimately aims to lead from a digitised image of the source to a normalised text, which includes expansion of the abbreviations. We explore different setups to obtain such a normalised text, either directly, by training HTR engines on normalised (i.e., expanded, disabbreviated) text, or by decomposing the process into discrete steps, each making use of specialist models for recognition, word segmentation and normalisation. The case studies considered here are drawn from the medieval Latin tradition.