 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling Heavily Abbreviated Manuscripts: HTR engines vs text normalisation approaches
Paper and Code
Jul 07, 2021
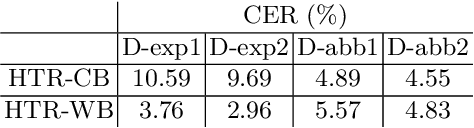
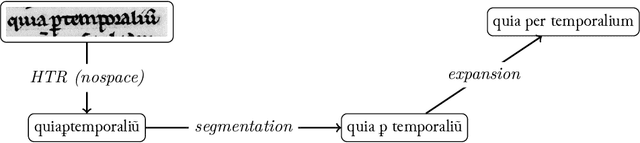

Although abbreviations are fairly common in handwritten sources, particularly in medieval and modern Western manuscripts, previous research dealing with computational approaches to their expansion is scarce. Yet abbreviations present particular challenges to computational approaches such as handwritten text recognition and natural language processing tasks. Often, pre-processing ultimately aims to lead from a digitised image of the source to a normalised text, which includes expansion of the abbreviations. We explore different setups to obtain such a normalised text, either directly, by training HTR engines on normalised (i.e., expanded, disabbreviated) text, or by decomposing the process into discrete steps, each making use of specialist models for recognition, word segmentation and normalisation. The case studies considered here are drawn from the medieval Latin tradition.