 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManuscripts in Time and Space: Experiments in Scriptometrics on an Old French Corpus
Paper and Code
Jan 30, 2018
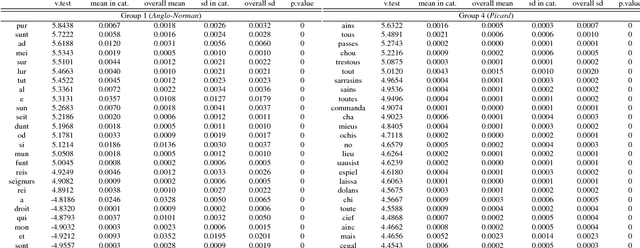
Witnesses of medieval literary texts, preserved in manuscript, are layered objects , being almost exclusively copies of copies. This results in multiple and hard to distinguish linguistic strata -- the author's scripta interacting with the scriptae of the various scribes -- in a context where literary written language is already a dialectal hybrid. Moreover, no single linguistic phenomenon allows to distinguish between different scriptae, and only the combination of multiple characteristics is likely to be significant [9] -- but which ones? The most common approach is to search for these features in a set of previously selected texts, that are supposed to be representative of a given scripta. This can induce a circularity, in which texts are used to select features that in turn characterise them as belonging to a linguistic area. To counter this issue, this paper offers an unsupervised and corpus-based approach, in which clustering methods are applied to an Old French corpus to identify main divisions and groups. Ultimately, scriptometric profiles are built for each of them.