 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Does Authorship Signal Emerge in Encoder-Based Language Models?
May 19, 2026Authorship attribution models fine-tuned with the same pretrained encoder, data, and loss can differ four-fold in performance depending only on their scoring mechanism. We use mechanistic interpretability tools to explain this gap. Stylistic features such as word length, punctuation density, and function-word frequency are equally available at every layer in every model, including in an off-the-shelf control encoder, hence the gap not coming from representation quality. Instead, causal intervention shows that the scorer determines where the encoder consolidates authorship signal. Mean pooling forces consolidation by early to mid layers, while late interaction defers it to later layers. We further derive this difference from the gradient structure of each scorer, and training dynamics reveal distinct learning trajectories that follow from that difference.
Timing In stand-up Comedy: Text, Audio, Laughter, Kinesics (TIC-TALK): Pipeline and Database for the Multimodal Study of Comedic Timing
Mar 23, 2026Stand-up comedy, and humor in general, are often studied through their verbal content. Yet live performance relies just as much on embodied presence and audience feedback. We introduce TIC-TALK, a multimodal resource with 5,400+ temporally aligned topic segments capturing language, gesture, and audience response across 90 professionally filmed stand-up comedy specials (2015-2024). The pipeline combines BERTopic for 60 s thematic segmentation with dense sentence embeddings, Whisper-AT for 0.8 s laughter detection, a fine-tuned YOLOv8-cls shot classifier, and YOLOv8s-pose for raw keypoint extraction at 1 fps. Raw 17-joint skeletal coordinates are retained without prior clustering, enabling the computation of continuous kinematic signals-arm spread, kinetic energy, and trunk lean-that serve as proxies for performance dynamics. All streams are aligned by hierarchical temporal containment without resampling, and each topic segment stores its sentence-BERT embedding for downstream similarity and clustering tasks. As a concrete use case, we study laughter dynamics across 24 thematic topics: kinetic energy negatively predicts audience laughter rate (r = -0.75, N = 24), consistent with a stillness-before-punchline pattern; personal and bodily content elicits more laughter than geopolitical themes; and shot close-up proportion correlates positively with laughter (r = +0.28), consistent with reactive montage.
Under-resourced studies of under-resourced languages: lemmatization and POS-tagging with LLM annotators for historical Armenian, Georgian, Greek and Syriac
Feb 17, 2026Low-resource languages pose persistent challenges for Natural Language Processing tasks such as lemmatization and part-of-speech (POS) tagging. This paper investigates the capacity of recent large language models (LLMs), including GPT-4 variants and open-weight Mistral models, to address these tasks in few-shot and zero-shot settings for four historically and linguistically diverse under-resourced languages: Ancient Greek, Classical Armenian, Old Georgian, and Syriac. Using a novel benchmark comprising aligned training and out-of-domain test corpora, we evaluate the performance of foundation models across lemmatization and POS-tagging, and compare them with PIE, a task-specific RNN baseline. Our results demonstrate that LLMs, even without fine-tuning, achieve competitive or superior performance in POS-tagging and lemmatization across most languages in few-shot settings. Significant challenges persist for languages characterized by complex morphology and non-Latin scripts, but we demonstrate that LLMs are a credible and relevant option for initiating linguistic annotation tasks in the absence of data, serving as an effective aid for annotation.
Diachronic Document Dataset for Semantic Layout Analysis
Nov 15, 2024



We present a novel, open-access dataset designed for semantic layout analysis, built to support document recreation workflows through mapping with the Text Encoding Initiative (TEI) standard. This dataset includes 7,254 annotated pages spanning a large temporal range (1600-2024) of digitised and born-digital materials across diverse document types (magazines, papers from sciences and humanities, PhD theses, monographs, plays, administrative reports, etc.) sorted into modular subsets. By incorporating content from different periods and genres, it addresses varying layout complexities and historical changes in document structure. The modular design allows domain-specific configurations. We evaluate object detection models on this dataset, examining the impact of input size and subset-based training. Results show that a 1280-pixel input size for YOLO is optimal and that training on subsets generally benefits from incorporating them into a generic model rather than fine-tuning pre-trained weights.
Who could be behind QAnon? Authorship attribution with supervised machine-learning
Mar 03, 2023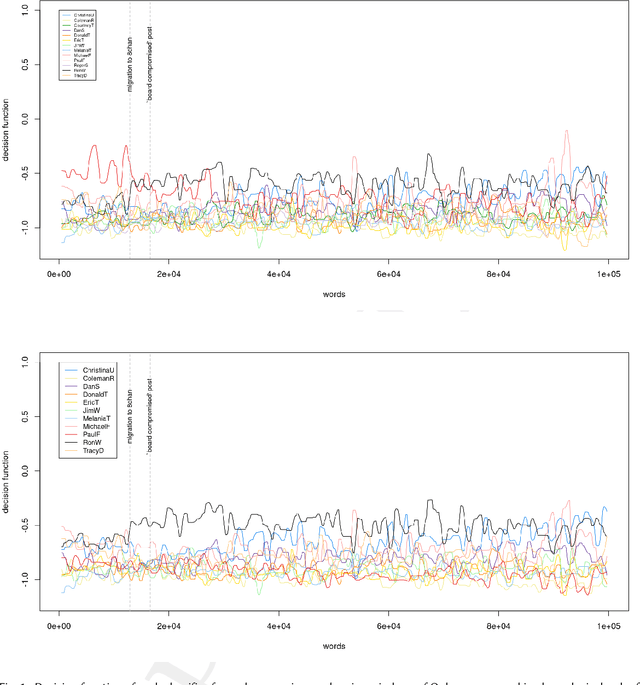


A series of social media posts signed under the pseudonym "Q", started a movement known as QAnon, which led some of its most radical supporters to violent and illegal actions. To identify the person(s) behind Q, we evaluate the coincidence between the linguistic properties of the texts written by Q and to those written by a list of suspects provided by journalistic investigation. To identify the authors of these posts, serious challenges have to be addressed. The "Q drops" are very short texts, written in a way that constitute a sort of literary genre in itself, with very peculiar features of style. These texts might have been written by different authors, whose other writings are often hard to find. After an online ethnology of the movement, necessary to collect enough material written by these thirteen potential authors, we use supervised machine learning to build stylistic profiles for each of them. We then performed a rolling analysis on Q's writings, to see if any of those linguistic profiles match the so-called 'QDrops' in part or entirety. We conclude that two different individuals, Paul F. and Ron W., are the closest match to Q's linguistic signature, and they could have successively written Q's texts. These potential authors are not high-ranked personality from the U.S. administration, but rather social media activists.
No comments: Addressing commentary sections in websites' analyses
Apr 19, 2021

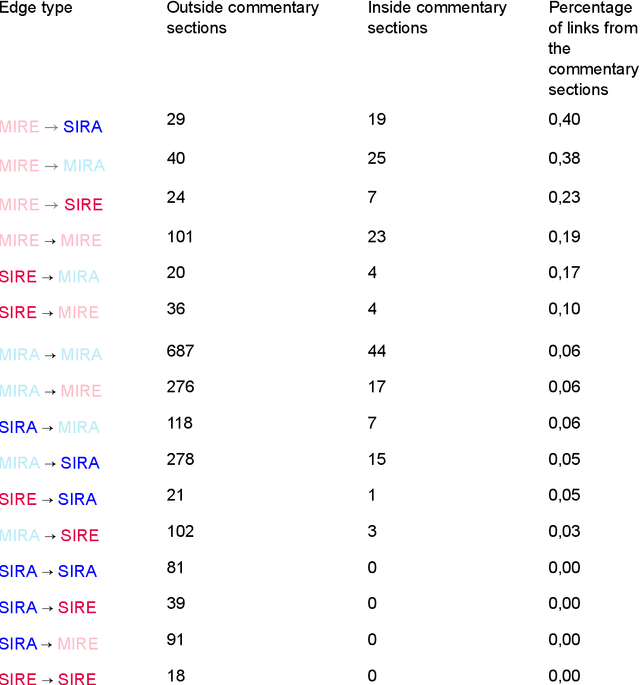
Removing or extracting the commentary sections from a series of websites is a tedious task, as no standard way to code them is widely adopted. This operation is thus very rarely performed. In this paper, we show that these commentary sections can induce significant biases in the analyses, especially in the case of controversial Highlights $\bullet$ Commentary sections can induce biases in the analysis of websites' contents $\bullet$ Analyzing these sections can be interesting per se. $\bullet$ We illustrate these points using a corpus of anti-vaccine websites. $\bullet$ We provide guidelines to remove or extract these sections.
Corpus and Models for Lemmatisation and POS-tagging of Classical French Theatre
May 15, 2020
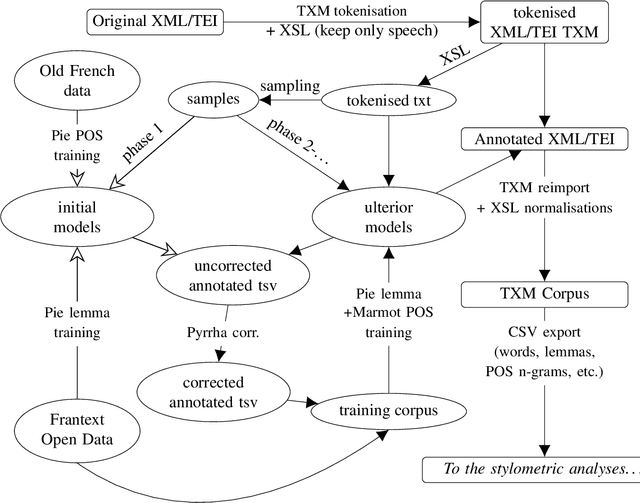
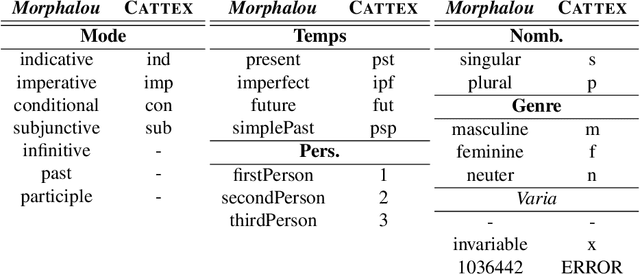
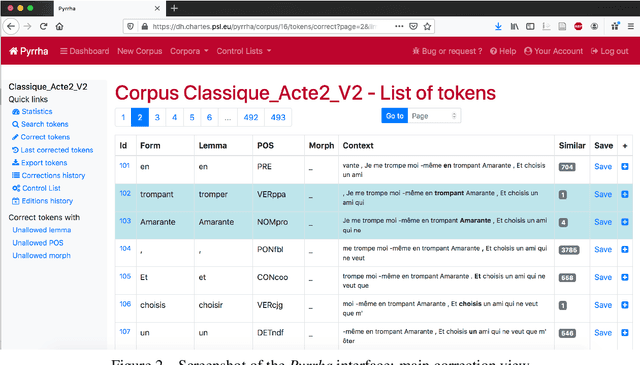
This paper describes the process of building an annotated corpus and training models for classical French literature, with a focus on theatre, and particularly comedies in verse. It was originally developed as a preliminary step to the stylometric analyses presented in Cafiero and Camps [2019]. The use of a recent lemmatiser based on neural networks and a CRF tagger allows to achieve accuracies beyond the current state-of-the art on the in-domain test, and proves to be robust during out-of-domain tests, i.e.up to 20th c.novels.
Why Molière most likely did write his plays
Jan 02, 2020As for Shakespeare, a hard-fought debate has emerged about Moli\`ere, a supposedly uneducated actor who, according to some, could not have written the masterpieces attributed to him. In the past decades, the century-old thesis according to which Pierre Corneille would be their actual author has become popular, mostly because of new works in computational linguistics. These results are reassessed here through state-of-the-art attribution methods. We study a corpus of comedies in verse by major authors of Moli\`ere and Corneille's time. Analysis of lexicon, rhymes, word forms, affixes, morphosyntactic sequences, and function words do not give any clue that another author among the major playwrights of the time would have written the plays signed under the name Moli\`ere.