 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstablishing a New State-of-the-Art for French Named Entity Recognition
May 27, 2020
The French TreeBank developed at the University Paris 7 is the main source of morphosyntactic and syntactic annotations for French. However, it does not include explicit information related to named entities, which are among the most useful information for several natural language processing tasks and applications. Moreover, no large-scale French corpus with named entity annotations contain referential information, which complement the type and the span of each mention with an indication of the entity it refers to. We have manually annotated the French TreeBank with such information, after an automatic pre-annotation step. We sketch the underlying annotation guidelines and we provide a few figures about the resulting annotations.
CamemBERT: a Tasty French Language Model
Nov 10, 2019



Pretrained language models are now ubiquitous in Natural Language Processing. Despite their success, most available models have either been trained on English data or on the concatenation of data in multiple languages. This makes practical use of such models --in all languages except English-- very limited. Aiming to address this issue for French, we release CamemBERT, a French version of the Bi-directional Encoders for Transformers (BERT). We measure the performance of CamemBERT compared to multilingual models in multiple downstream tasks, namely part-of-speech tagging, dependency parsing, named-entity recognition, and natural language inference. CamemBERT improves the state of the art for most of the tasks considered. We release the pretrained model for CamemBERT hoping to foster research and downstream applications for French NLP.
Effective Spoken Language Labeling with Deep Recurrent Neural Networks
Jun 20, 2017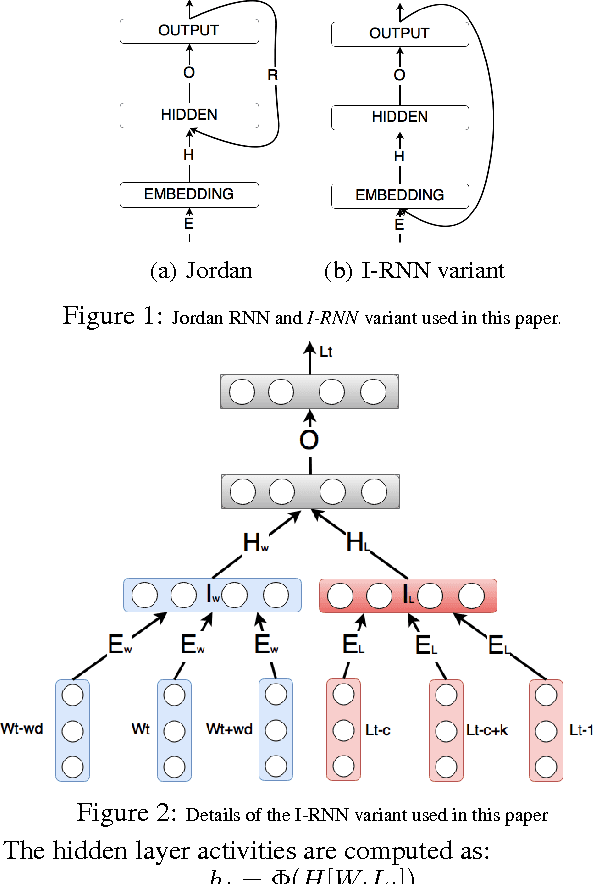
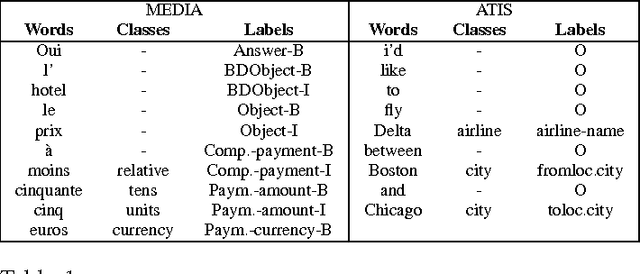
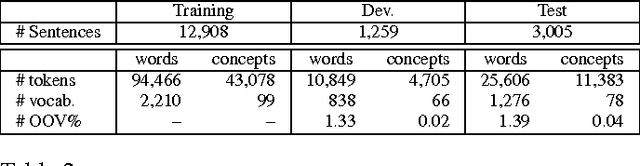
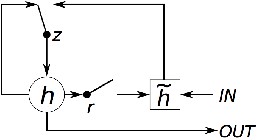
Understanding spoken language is a highly complex problem, which can be decomposed into several simpler tasks. In this paper, we focus on Spoken Language Understanding (SLU), the module of spoken dialog systems responsible for extracting a semantic interpretation from the user utterance. The task is treated as a labeling problem. In the past, SLU has been performed with a wide variety of probabilistic models. The rise of neural networks, in the last couple of years, has opened new interesting research directions in this domain. Recurrent Neural Networks (RNNs) in particular are able not only to represent several pieces of information as embeddings but also, thanks to their recurrent architecture, to encode as embeddings relatively long contexts. Such long contexts are in general out of reach for models previously used for SLU. In this paper we propose novel RNNs architectures for SLU which outperform previous ones. Starting from a published idea as base block, we design new deep RNNs achieving state-of-the-art results on two widely used corpora for SLU: ATIS (Air Traveling Information System), in English, and MEDIA (Hotel information and reservation in France), in French.
Label-Dependencies Aware Recurrent Neural Networks
Jun 06, 2017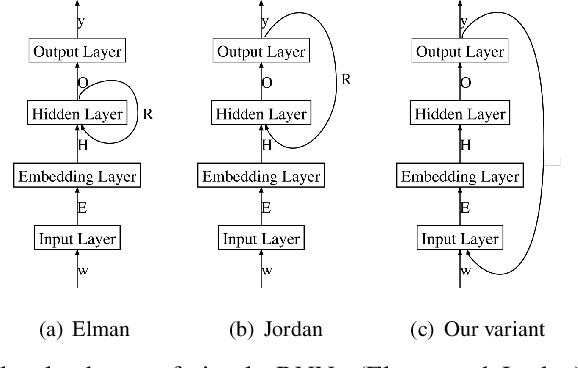
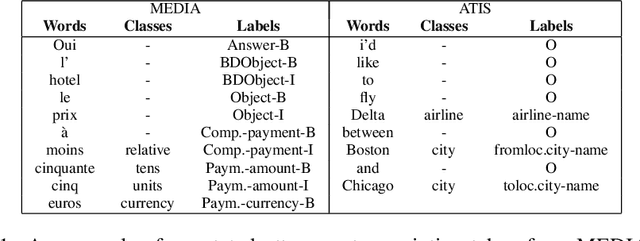
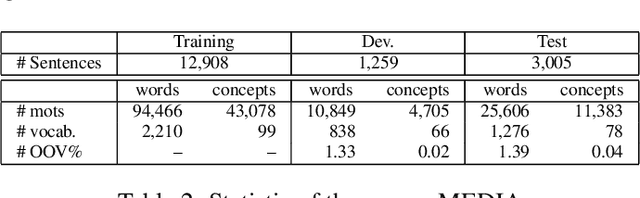
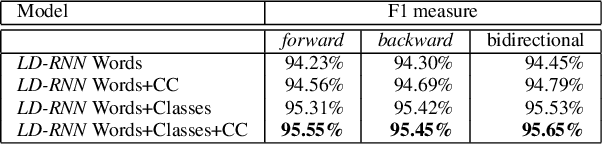
In the last few years, Recurrent Neural Networks (RNNs) have proved effective on several NLP tasks. Despite such great success, their ability to model \emph{sequence labeling} is still limited. This lead research toward solutions where RNNs are combined with models which already proved effective in this domain, such as CRFs. In this work we propose a solution far simpler but very effective: an evolution of the simple Jordan RNN, where labels are re-injected as input into the network, and converted into embeddings, in the same way as words. We compare this RNN variant to all the other RNN models, Elman and Jordan RNN, LSTM and GRU, on two well-known tasks of Spoken Language Understanding (SLU). Thanks to label embeddings and their combination at the hidden layer, the proposed variant, which uses more parameters than Elman and Jordan RNNs, but far fewer than LSTM and GRU, is more effective than other RNNs, but also outperforms sophisticated CRF models.