 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Dependencies Aware Recurrent Neural Networks
Paper and Code
Jun 06, 2017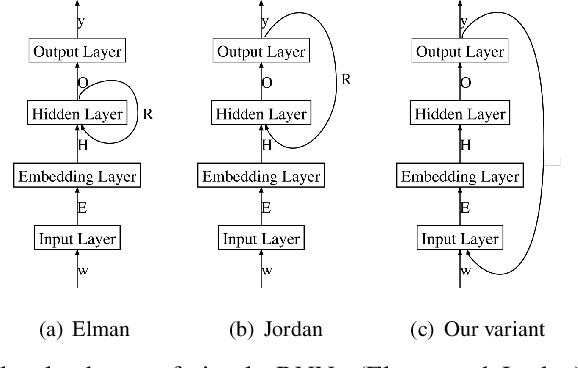
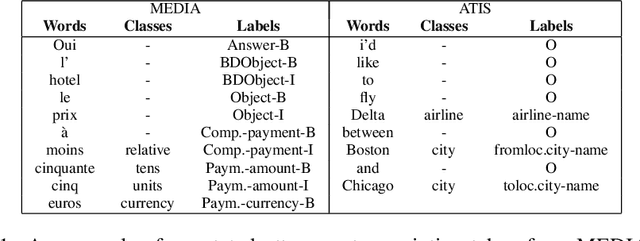
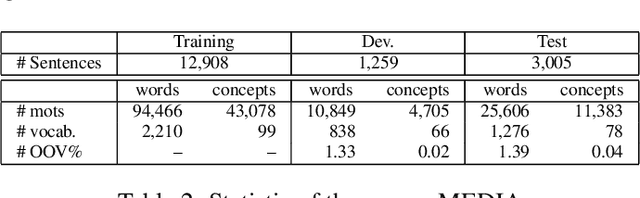
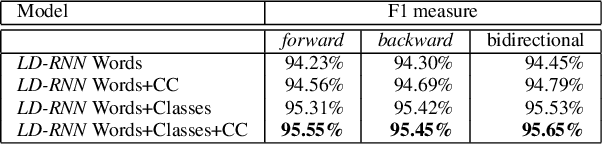
In the last few years, Recurrent Neural Networks (RNNs) have proved effective on several NLP tasks. Despite such great success, their ability to model \emph{sequence labeling} is still limited. This lead research toward solutions where RNNs are combined with models which already proved effective in this domain, such as CRFs. In this work we propose a solution far simpler but very effective: an evolution of the simple Jordan RNN, where labels are re-injected as input into the network, and converted into embeddings, in the same way as words. We compare this RNN variant to all the other RNN models, Elman and Jordan RNN, LSTM and GRU, on two well-known tasks of Spoken Language Understanding (SLU). Thanks to label embeddings and their combination at the hidden layer, the proposed variant, which uses more parameters than Elman and Jordan RNNs, but far fewer than LSTM and GRU, is more effective than other RNNs, but also outperforms sophisticated CRF models.