 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStandards for Language Resources
Nov 10, 2009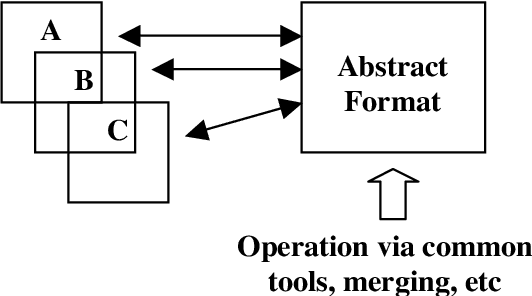

The goal of this paper is two-fold: to present an abstract data model for linguistic annotations and its implementation using XML, RDF and related standards; and to outline the work of a newly formed committee of the International Standards Organization (ISO), ISO/TC 37/SC 4 Language Resource Management, which will use this work as its starting point.
* Colloque avec actes et comit\'e de lecture. internationale
A Common XML-based Framework for Syntactic Annotations
Sep 15, 2009

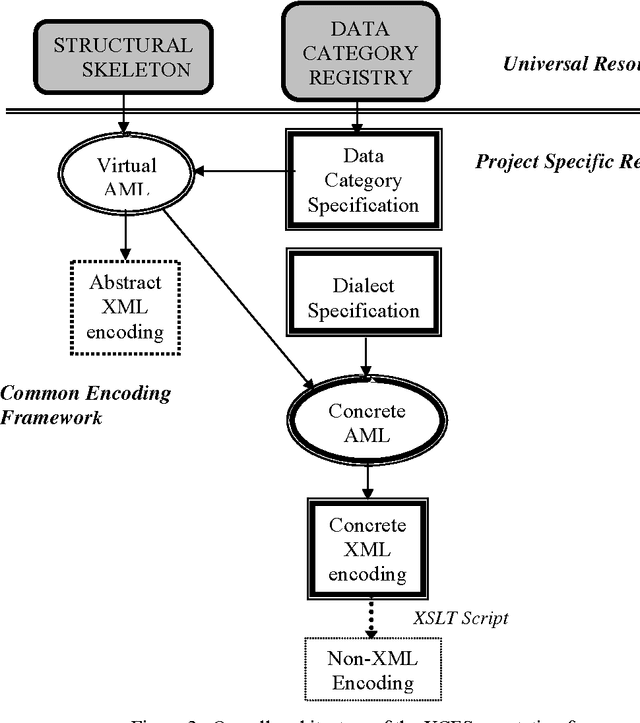
It is widely recognized that the proliferation of annotation schemes runs counter to the need to re-use language resources, and that standards for linguistic annotation are becoming increasingly mandatory. To answer this need, we have developed a framework comprised of an abstract model for a variety of different annotation types (e.g., morpho-syntactic tagging, syntactic annotation, co-reference annotation, etc.), which can be instantiated in different ways depending on the annotator's approach and goals. In this paper we provide an overview of the framework, demonstrate its applicability to syntactic annotation, and show how it can contribute to comparative evaluation of parser output and diverse syntactic annotation schemes.
* Colloque avec actes et comit\'e de lecture. internationale
Marking-up multiple views of a Text: Discourse and Reference
Sep 15, 2009
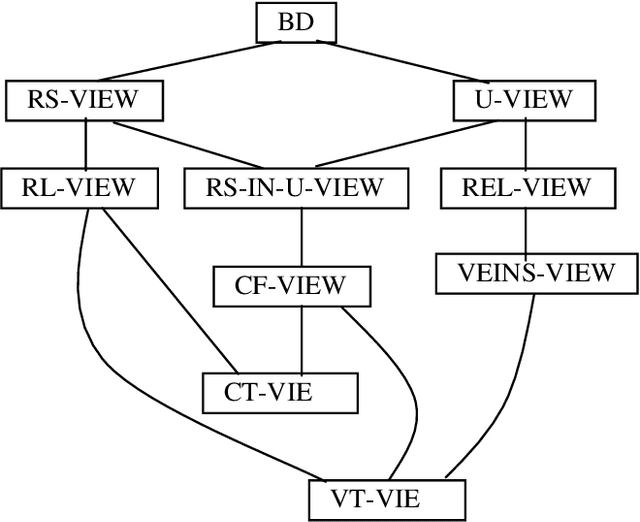
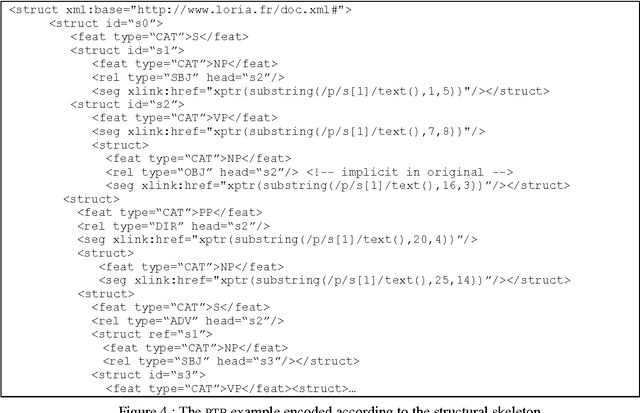
We describe an encoding scheme for discourse structure and reference, based on the TEI Guidelines and the recommendations of the Corpus Encoding Specification (CES). A central feature of the scheme is a CES-based data architecture enabling the encoding of and access to multiple views of a marked-up document. We describe a tool architecture that supports the encoding scheme, and then show how we have used the encoding scheme and the tools to perform a discourse analytic task in support of a model of global discourse cohesion called Veins Theory (Cristea & Ide, 1998).
A Formal Model of Dictionary Structure and Content
Jul 22, 2007


We show that a general model of lexical information conforms to an abstract model that reflects the hierarchy of information found in a typical dictionary entry. We show that this model can be mapped into a well-formed XML document, and how the XSL transformation language can be used to implement a semantics defined over the abstract model to enable extraction and manipulation of the information in any format.
International Standard for a Linguistic Annotation Framework
Jul 22, 2007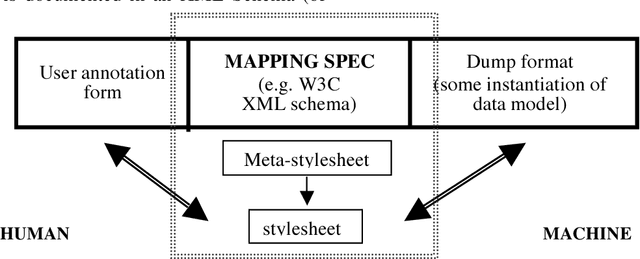
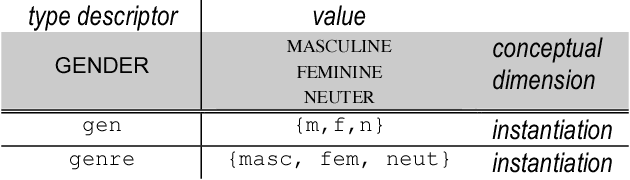
This paper describes the Linguistic Annotation Framework under development within ISO TC37 SC4 WG1. The Linguistic Annotation Framework is intended to serve as a basis for harmonizing existing language resources as well as developing new ones.
Fine-Grained Word Sense Disambiguation Based on Parallel Corpora, Word Alignment, Word Clustering and Aligned Wordnets
Mar 10, 2005

The paper presents a method for word sense disambiguation based on parallel corpora. The method exploits recent advances in word alignment and word clustering based on automatic extraction of translation equivalents and being supported by available aligned wordnets for the languages in the corpus. The wordnets are aligned to the Princeton Wordnet, according to the principles established by EuroWordNet. The evaluation of the WSD system, implementing the method described herein showed very encouraging results. The same system used in a validation mode, can be used to check and spot alignment errors in multilingually aligned wordnets as BalkaNet and EuroWordNet.
* 7 pages in Proc. of COLING2005