 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRELATE: A Modern Processing Platform for Romanian Language
Oct 29, 2024This paper presents the design and evolution of the RELATE platform. It provides a high-performance environment for natural language processing activities, specially constructed for Romanian language. Initially developed for text processing, it has been recently updated to integrate audio processing tools. Technical details are provided with regard to core components. We further present different usage scenarios, derived from actual use in national and international research projects, thus demonstrating that RELATE is a mature, modern, state-of-the-art platform for processing Romanian language corpora. Finally, we present very recent developments including bimodal (text and audio) features available within the platform.
RoMemes: A multimodal meme corpus for the Romanian language
Oct 20, 2024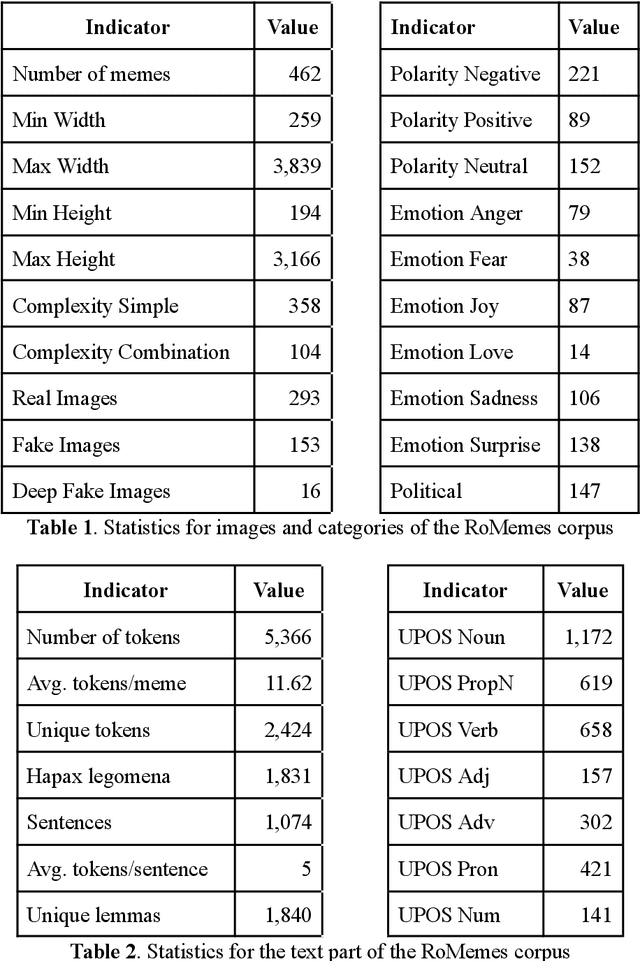

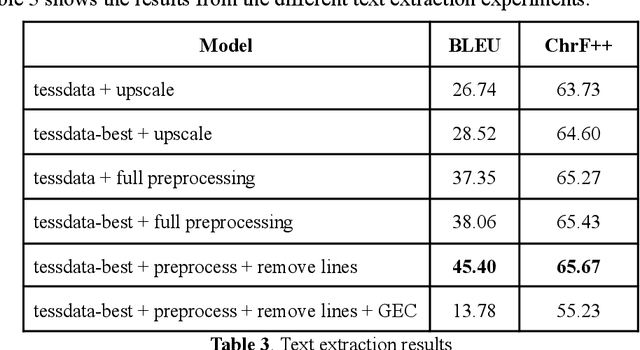
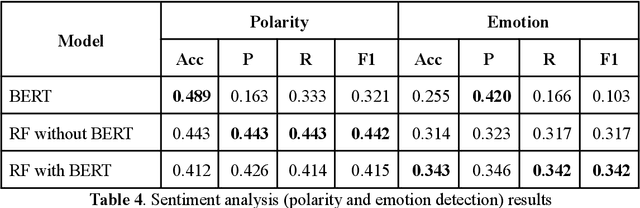
Memes are becoming increasingly more popular in online media, especially in social networks. They usually combine graphical representations (images, drawings, animations or video) with text to convey powerful messages. In order to extract, process and understand the messages, AI applications need to employ multimodal algorithms. In this paper, we introduce a curated dataset of real memes in the Romanian language, with multiple annotation levels. Baseline algorithms were employed to demonstrate the usability of the dataset. Results indicate that further research is needed to improve the processing capabilities of AI tools when faced with Internet memes.
HistNERo: Historical Named Entity Recognition for the Romanian Language
Apr 30, 2024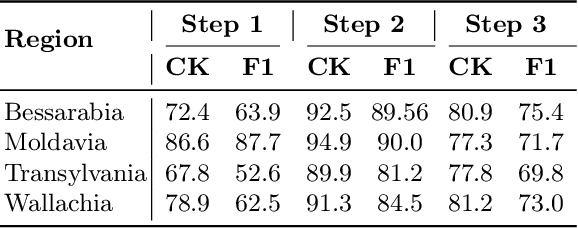
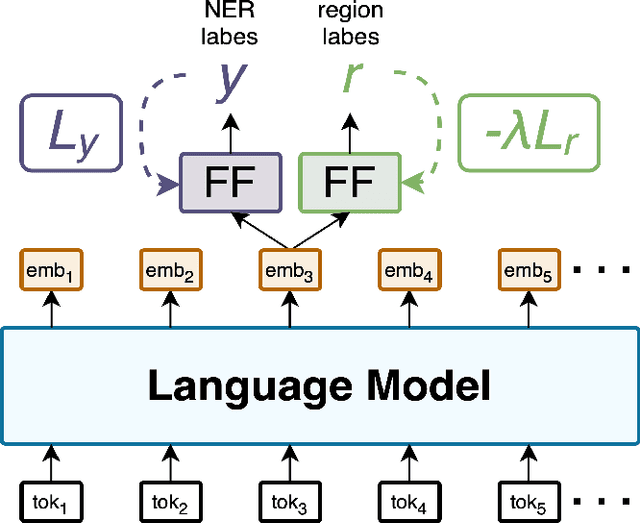
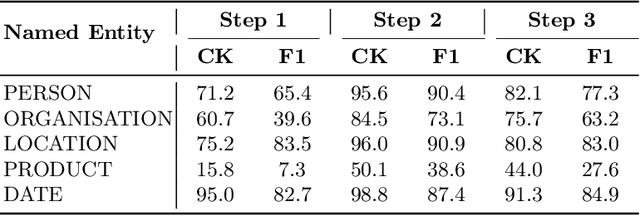
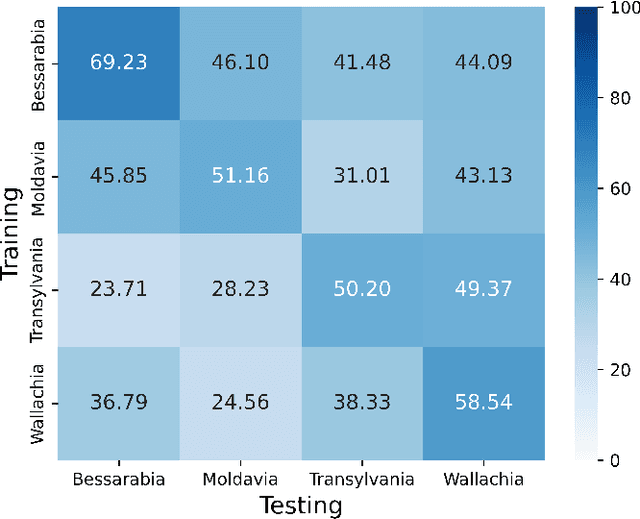
This work introduces HistNERo, the first Romanian corpus for Named Entity Recognition (NER) in historical newspapers. The dataset contains 323k tokens of text, covering more than half of the 19th century (i.e., 1817) until the late part of the 20th century (i.e., 1990). Eight native Romanian speakers annotated the dataset with five named entities. The samples belong to one of the following four historical regions of Romania, namely Bessarabia, Moldavia, Transylvania, and Wallachia. We employed this proposed dataset to perform several experiments for NER using Romanian pre-trained language models. Our results show that the best model achieved a strict F1-score of 55.69%. Also, by reducing the discrepancies between regions through a novel domain adaption technique, we improved the performance on this corpus to a strict F1-score of 66.80%, representing an absolute gain of more than 10%.
Towards Improving the Performance of Pre-Trained Speech Models for Low-Resource Languages Through Lateral Inhibition
Jun 30, 2023


With the rise of bidirectional encoder representations from Transformer models in natural language processing, the speech community has adopted some of their development methodologies. Therefore, the Wav2Vec models were introduced to reduce the data required to obtain state-of-the-art results. This work leverages this knowledge and improves the performance of the pre-trained speech models by simply replacing the fine-tuning dense layer with a lateral inhibition layer inspired by the biological process. Our experiments on Romanian, a low-resource language, show an average improvement of 12.5% word error rate (WER) using the lateral inhibition layer. In addition, we obtain state-of-the-art results on both the Romanian Speech Corpus and the Robin Technical Acquisition Corpus with 1.78% WER and 29.64% WER, respectively.
Multilingual Multiword Expression Identification Using Lateral Inhibition and Domain Adaptation
Jun 17, 2023Correctly identifying multiword expressions (MWEs) is an important task for most natural language processing systems since their misidentification can result in ambiguity and misunderstanding of the underlying text. In this work, we evaluate the performance of the mBERT model for MWE identification in a multilingual context by training it on all 14 languages available in version 1.2 of the PARSEME corpus. We also incorporate lateral inhibition and language adversarial training into our methodology to create language-independent embeddings and improve its capabilities in identifying multiword expressions. The evaluation of our models shows that the approach employed in this work achieves better results compared to the best system of the PARSEME 1.2 competition, MTLB-STRUCT, on 11 out of 14 languages for global MWE identification and on 12 out of 14 languages for unseen MWE identification. Additionally, averaged across all languages, our best approach outperforms the MTLB-STRUCT system by 1.23% on global MWE identification and by 4.73% on unseen global MWE identification.
An Open-Domain QA System for e-Governance
Jun 16, 2022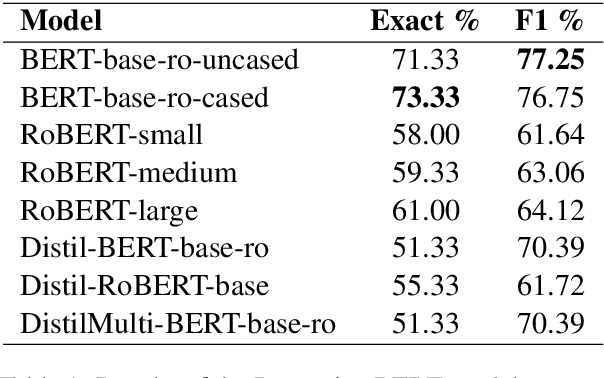
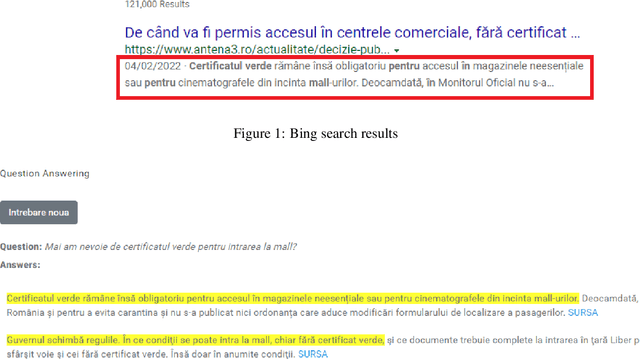
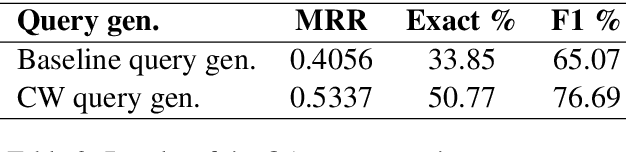
The paper presents an open-domain Question Answering system for Romanian, answering COVID-19 related questions. The QA system pipeline involves automatic question processing, automatic query generation, web searching for the top 10 most relevant documents and answer extraction using a fine-tuned BERT model for Extractive QA, trained on a COVID-19 data set that we have manually created. The paper will present the QA system and its integration with the Romanian language technologies portal RELATE, the COVID-19 data set and different evaluations of the QA performance.
Distilling the Knowledge of Romanian BERTs Using Multiple Teachers
Jan 11, 2022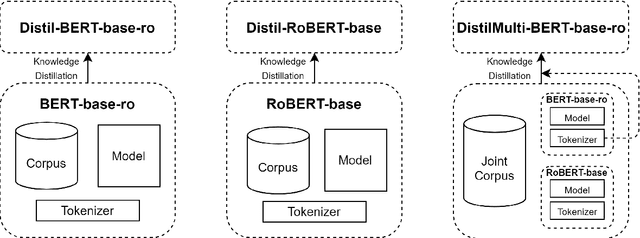
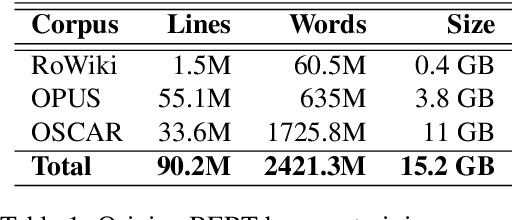
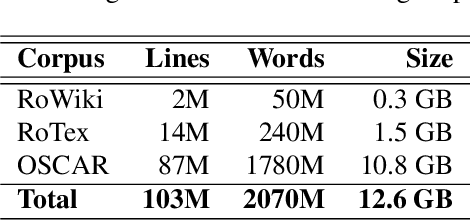
Running large-scale pre-trained language models in computationally constrained environments remains a challenging problem yet to be addressed, while transfer learning from these models has become prevalent in Natural Language Processing tasks. Several solutions, including knowledge distillation, network quantization, or network pruning have been previously proposed; however, these approaches focus mostly on the English language, thus widening the gap when considering low-resource languages. In this work, we introduce three light and fast versions of distilled BERT models for the Romanian language: Distil-BERT-base-ro, Distil-RoBERT-base, and DistilMulti-BERT-base-ro. The first two models resulted from the individual distillation of knowledge from two base versions of Romanian BERTs available in literature, while the last one was obtained by distilling their ensemble. To our knowledge, this is the first attempt to create publicly available Romanian distilled BERT models, which were thoroughly evaluated on five tasks: part-of-speech tagging, named entity recognition, sentiment analysis, semantic textual similarity, and dialect identification. Our experimental results argue that the three distilled models maintain most performance in terms of accuracy with their teachers, while being twice as fast on a GPU and ~35% smaller. In addition, we further test the similarity between the predictions of our students versus their teachers by measuring their label and probability loyalty, together with regression loyalty - a new metric introduced in this work.
Romanian Speech Recognition Experiments from the ROBIN Project
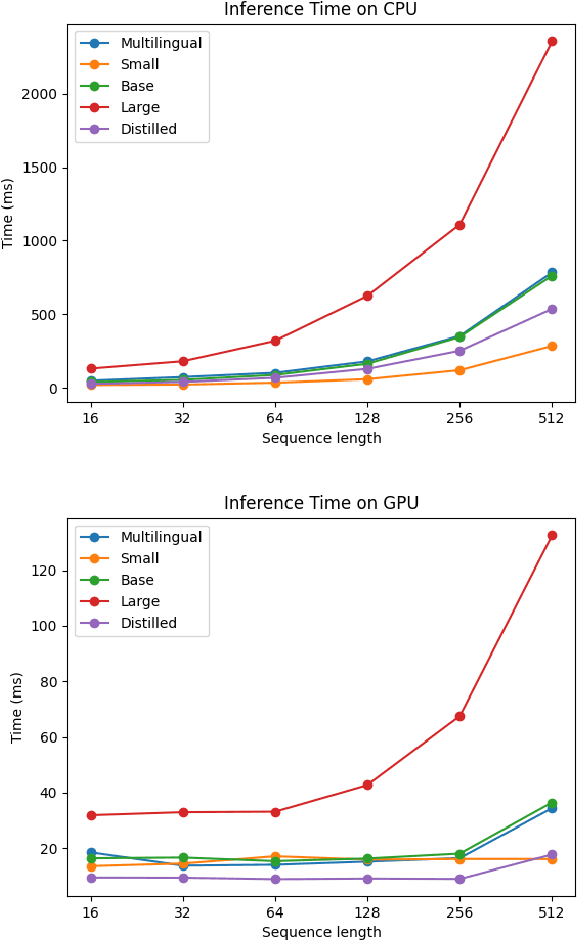
Nov 23, 2021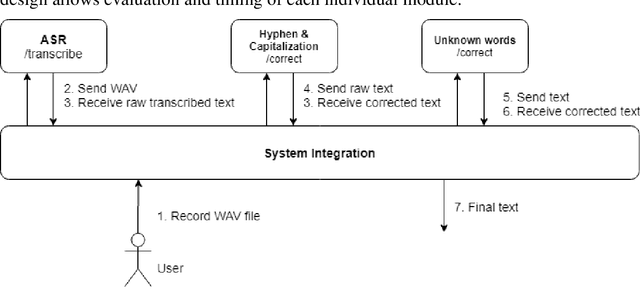
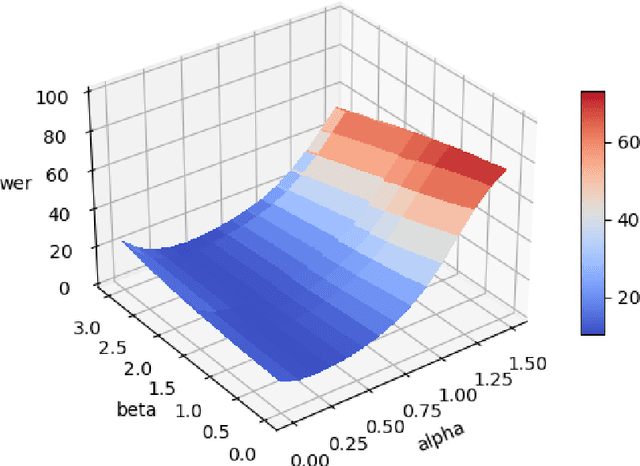
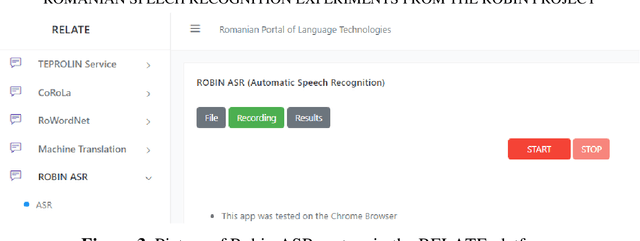
One of the fundamental functionalities for accepting a socially assistive robot is its communication capabilities with other agents in the environment. In the context of the ROBIN project, situational dialogue through voice interaction with a robot was investigated. This paper presents different speech recognition experiments with deep neural networks focusing on producing fast (under 100ms latency from the network itself), while still reliable models. Even though one of the key desired characteristics is low latency, the final deep neural network model achieves state of the art results for recognizing Romanian language, obtaining a 9.91% word error rate (WER), when combined with a language model, thus improving over the previous results while offering at the same time an improved runtime performance. Additionally, we explore two modules for correcting the ASR output (hyphen and capitalization restoration and unknown words correction), targeting the ROBIN project's goals (dialogue in closed micro-worlds). We design a modular architecture based on APIs allowing an integration engine (either in the robot or external) to chain together the available modules as needed. Finally, we test the proposed design by integrating it in the RELATE platform and making the ASR service available to web users by either uploading a file or recording new speech.
Human-Machine Interaction Speech Corpus from the ROBIN project
Nov 22, 2021
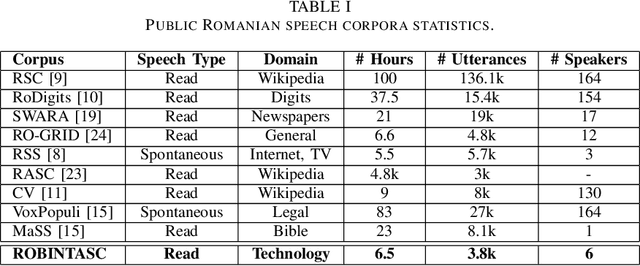
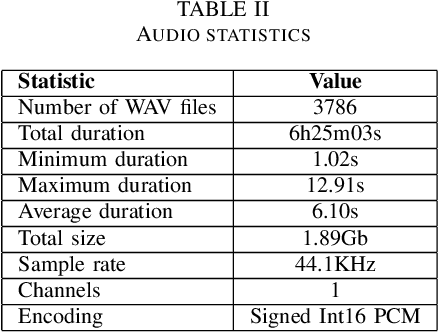
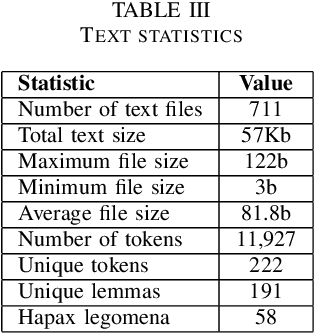
This paper introduces a new Romanian speech corpus from the ROBIN project, called ROBIN Technical Acquisition Speech Corpus (ROBINTASC). Its main purpose was to improve the behaviour of a conversational agent, allowing human-machine interaction in the context of purchasing technical equipment. The paper contains a detailed description of the acquisition process, corpus statistics as well as an evaluation of the corpus influence on a low-latency ASR system as well as a dialogue component.
* V. P\u{a}i\c{s}, R. Ion, A. -M. Avram, E. Irimia, V. B. Mititelu and M. Mitrofan, "Human-Machine Interaction Speech Corpus from the ROBIN project", Proceedings of the 2021 International Conference on Speech Technology and Human-Computer Dialogue (SpeD), 2021, pp. 91-96
More Romanian word embeddings from the RETEROM project
Nov 21, 2021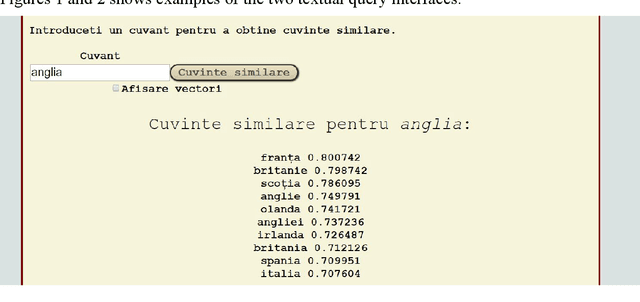
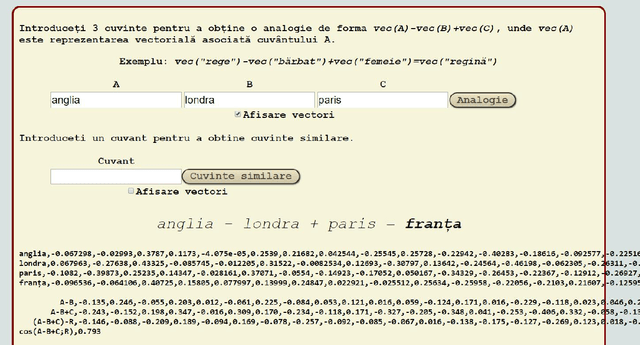
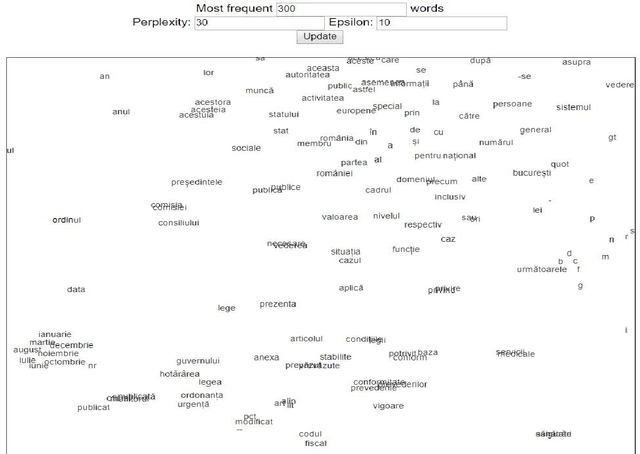

Automatically learned vector representations of words, also known as "word embeddings", are becoming a basic building block for more and more natural language processing algorithms. There are different ways and tools for constructing word embeddings. Most of the approaches rely on raw texts, the construction items being the word occurrences and/or letter n-grams. More elaborated research is using additional linguistic features extracted after text preprocessing. Morphology is clearly served by vector representations constructed from raw texts and letter n-grams. Syntax and semantics studies may profit more from the vector representations constructed with additional features such as lemma, part-of-speech, syntactic or semantic dependants associated with each word. One of the key objectives of the ReTeRom project is the development of advanced technologies for Romanian natural language processing, including morphological, syntactic and semantic analysis of text. As such, we plan to develop an open-access large library of ready-to-use word embeddings sets, each set being characterized by different parameters: used features (wordforms, letter n-grams, lemmas, POSes etc.), vector lengths, window/context size and frequency thresholds. To this end, the previously created sets of word embeddings (based on word occurrences) on the CoRoLa corpus (P\u{a}i\c{s} and Tufi\c{s}, 2018) are and will be further augmented with new representations learned from the same corpus by using specific features such as lemmas and parts of speech. Furthermore, in order to better understand and explore the vectors, graphical representations will be available by customized interfaces.
* Publlished in Proceedings of the 13th International Conference on Linguistic Resources and Tools for Processing Romanian Language - CONSILR 2018. Complete proceedings volume available here: https://profs.info.uaic.ro/~consilr/2019/wp-content/uploads/2019/06/volum-ConsILR-2018-1.pdf