 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialectal and Low Resource Machine Translation for Aromanian
Oct 23, 2024We present a neural machine translation system that can translate between Romanian, English, and Aromanian (an endangered Eastern Romance language); the first of its kind. BLEU scores range from 17 to 32 depending on the direction and genre of the text. Alongside, we release the biggest known Aromanian-Romanian bilingual corpus, consisting of 79k cleaned sentence pairs. Additional tools such as an agnostic sentence embedder (used for both text mining and automatic evaluation) and a diacritics converter are also presented. We publicly release our findings and models. Finally, we describe the deployment of our quantized model at https://arotranslate.com.
RoMemes: A multimodal meme corpus for the Romanian language
Oct 20, 2024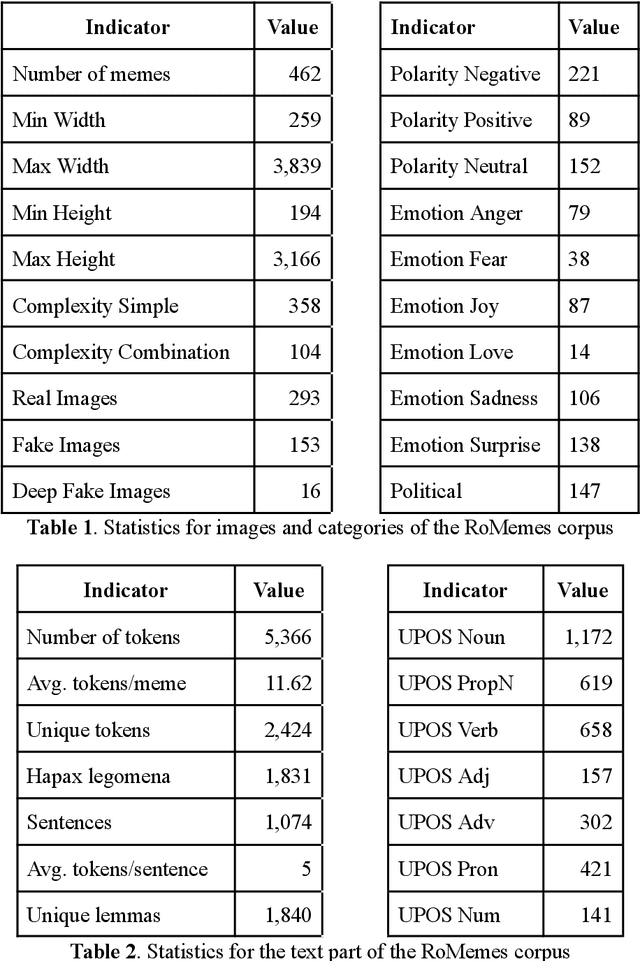

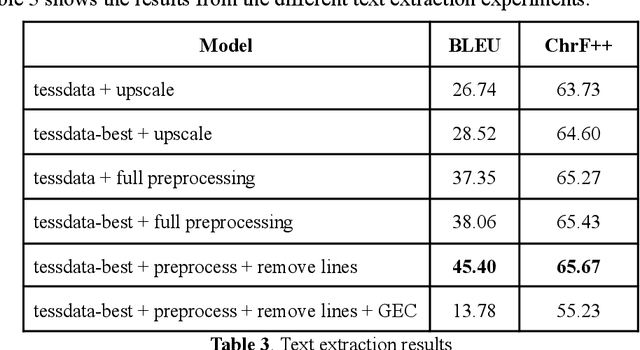
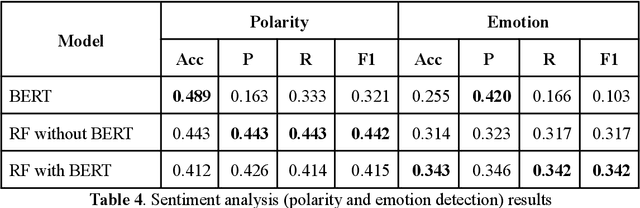
Memes are becoming increasingly more popular in online media, especially in social networks. They usually combine graphical representations (images, drawings, animations or video) with text to convey powerful messages. In order to extract, process and understand the messages, AI applications need to employ multimodal algorithms. In this paper, we introduce a curated dataset of real memes in the Romanian language, with multiple annotation levels. Baseline algorithms were employed to demonstrate the usability of the dataset. Results indicate that further research is needed to improve the processing capabilities of AI tools when faced with Internet memes.
Reddit is all you need: Authorship profiling for Romanian
Oct 13, 2024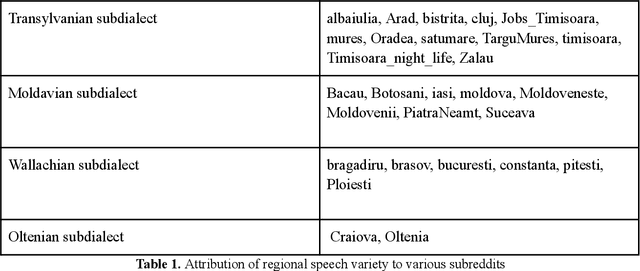
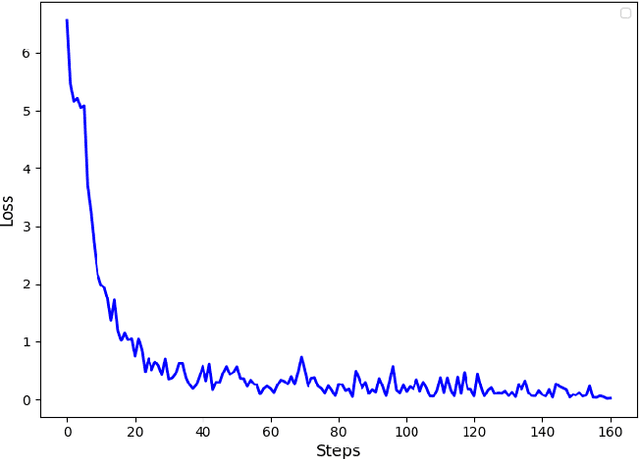
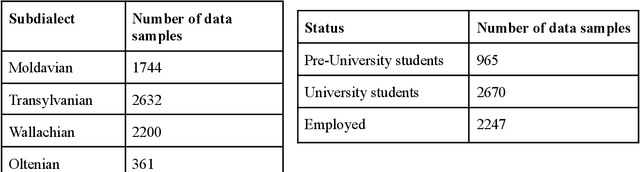
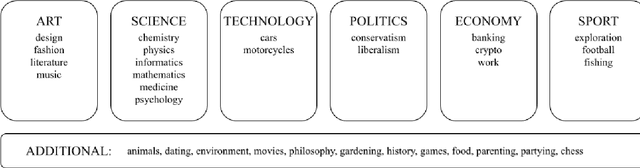
Authorship profiling is the process of identifying an author's characteristics based on their writings. This centuries old problem has become more intriguing especially with recent developments in Natural Language Processing (NLP). In this paper, we introduce a corpus of short texts in the Romanian language, annotated with certain author characteristic keywords; to our knowledge, the first of its kind. In order to do this, we exploit a social media platform called Reddit. We leverage its thematic community-based structure (subreddits structure), which offers information about the author's background. We infer an user's demographic and some broad personal traits, such as age category, employment status, interests, and social orientation based on the subreddit and other cues. We thus obtain a 23k+ samples corpus, extracted from 100+ Romanian subreddits. We analyse our dataset, and finally, we fine-tune and evaluate Large Language Models (LLMs) to prove baselines capabilities for authorship profiling using the corpus, indicating the need for further research in the field. We publicly release all our resources.