 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReddit is all you need: Authorship profiling for Romanian
Paper and Code
Oct 13, 2024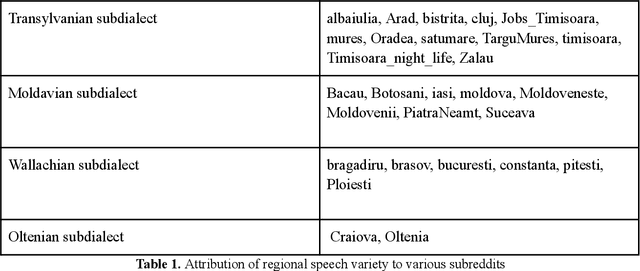
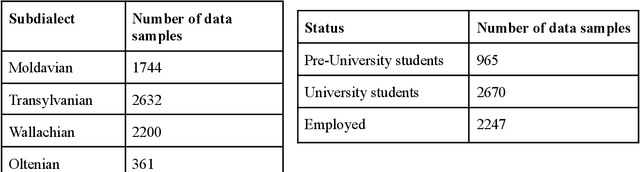
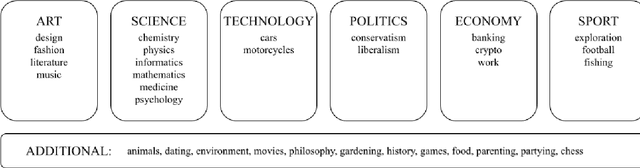
Authorship profiling is the process of identifying an author's characteristics based on their writings. This centuries old problem has become more intriguing especially with recent developments in Natural Language Processing (NLP). In this paper, we introduce a corpus of short texts in the Romanian language, annotated with certain author characteristic keywords; to our knowledge, the first of its kind. In order to do this, we exploit a social media platform called Reddit. We leverage its thematic community-based structure (subreddits structure), which offers information about the author's background. We infer an user's demographic and some broad personal traits, such as age category, employment status, interests, and social orientation based on the subreddit and other cues. We thus obtain a 23k+ samples corpus, extracted from 100+ Romanian subreddits. We analyse our dataset, and finally, we fine-tune and evaluate Large Language Models (LLMs) to prove baselines capabilities for authorship profiling using the corpus, indicating the need for further research in the field. We publicly release all our resources.